AWS Open Source Blog
Speed up Highly Available Deployments on Kubernetes
The Amazon Managed Service for Prometheus provides a Prometheus-compatible monitoring service that is operated on Kubernetes. As AWS customers have increasingly adopted Prometheus to monitor their containerized applications over the past year, our existing processes for updating our software while maintaining availability began to take too long. Software updates were slowing down the release of new features and impacting our ability to quickly roll out bug fixes.
In this post, we deep dive into the internals of our Prometheus service and how we speed up our deployment times without impacting availability. We open sourced our solution as two Kubernetes controllers: the ZoneAwareUpdate (ZAU) controller and ZoneDisruptionBudget (ZDB) admission webhook controller. Together these two open source controllers allow any Kubernetes user to take advantage of faster deployments for StatefulSet pods deployed across multiple availability zones.
Background
Amazon Managed Service for Prometheus is powered by Cortex, an open source Cloud Native Computing Foundation (CNCF) project, which provides a horizontally scalable, highly available, and long-term storage solution for Prometheus metrics.
Cortex is designed as a set of microservices that typically run in a Kubernetes cluster. Each microservice uses the most appropriate technique for horizontal scaling; most are stateless and can handle requests for all users while some, such as the ingesters, are semi-stateful.

Figure 1 – Cortex Architecture
Ingesters receive time-series samples from distributors which are kept in memory and periodically (by default, every 2 hours) write to a long-term storage backend such as Amazon Simple Storage Service (Amazon S3).
When an ingester shuts down because of a rolling update or maintenance, the in-memory data must not be discarded to avoid data loss. Given that, Cortex uses a write-ahead log (WAL) to write all incoming series samples to a persistent disk (such as an EBS volume) until they’re flushed to the long-term storage. During the restart, the WAL is replayed to recover the in-memory series samples before having the ingester ready to process new requests. To do that, a StatefulSet is used to have ingesters using the same persistent volume across restarts.
This process of synchronizing data to disk and afterwards replaying the WAL takes time, causing the update of a single ingester to take several minutes depending on how many active time series it is holding in memory. During internal tests we observed that it takes an average of 2:30 minutes to update ingesters handling 1 million active time-series samples.
Besides that, at AWS we replicate services across multiple Availability Zones (AZs) to reduce blast radius and ensure continued operation even if an AZ becomes impaired. Given that, we use zone aware replication and topology spread constraints to hold multiple replicas (typically three) of each time series in distinct AZs.
With zone aware replication a request fails when a single time series fails to be replicated to at least 2 out of 3 ingesters. Therefore, the Cortex documentation recommends to update ingesters one at a time using the StatefulSet’s default RollingUpdate strategy, avoiding concurrently shutting down 2 ingesters responsible for handling the same time series.
Because of the limitation that we can only update one ingester at a time, and given that it takes several minutes to restart a single ingester, on large clusters a deployment can take several hours. For instance, on clusters with 100 ingesters holding 1 million active time series a single deployment takes more than 4 hours (250 minutes).
Zone Aware Controllers
As discussed in the previous section, deployment of large clusters takes hours when updating one ingester at a time. This slows down our ability to deploy new features, bug fixes, security patches and to scale our service to handle higher loads.
We could have improved the rolling update duration by restarting multiple ingesters in parallel using the new StatefulSets’ Max Unavailable alpha feature available on Kubernetes 1.24+. However, we needed to make sure when updating multiple ingesters that we always have a quorum of 2 replicas (out of 3) answering requests. Since those replicas are spread across different AZs, one easy way to guarantee this is to simultaneously update ingesters that are in the same AZ. To achieve this, we built a couple of custom controllers for zone (AZ) aware rollouts and disruptions which were open sourced in September 2022 at https://github.com/aws/zone-aware-controllers-for-k8s.
ZoneAwareUpdates (ZAU)
The ZoneAwareUpdate (ZAU) controller enables faster deployments for a StatefulSet whose pods are deployed across multiple AZs. At each control loop, it applies zone-aware logic to check for pods in an old revision and deletes them so that they can be updated to a new revision.

Figure 2 – ZoneAwareUpdate controller
Instead of updating replicas at a constant rate, the controller exponentially increases the number of pods deleted at the same time, until the configured MaxUnavailable value. For example, it will start by updating a single ingester, then 2, then 4 and so on. This allows us to deploy slowly at first, and increase the speed as confidence is gained in the new revision.
The controller also will never update pods in different zones at the same time, and when moving to subsequent zones it continues to increase the number of pods to be deleted until MaxUnavailable is reached, as shown in the figure below:

Figure 3 – ZAU Update Sequence
It’s important as well that when a rollback (or new rollout) is initiated before a deployment finishes that we start by updating the pods that were most recently created to move away as fast as possible from a faulty revision. To achieve that, the controller always deletes pods in a specific order, using the zone ascending alphabetical order in conjunction with the pod decreasing ordinal order, as shown in the previous figure.
Finally, the ZAU controller also allows users to specify the name of an Amazon CloudWatch aggregate alarm that will pause the rollout when in alarm state. This can be used, for example, to prevent deployments from proceeding in case of canary failures. We use alarms to stop deployments when there is an ingester running on degraded mode because of a disk or instance failure.
ZoneDisruptionBudgets (ZDB)
In addition to rolling updates, we were also facing long deployments during node upgrades.
We use one Amazon Elastic Kubernetes Service (Amazon EKS) managed node group per AZ to automate the provisioning and lifecycle of nodes (EC2 instances), with node groups upgraded sequentially to avoid taking down two ingesters from different AZs at the same time.
Despite Amazon EKS allowing multiple managed nodes to be upgraded simultaneously through the maxUnavailable update config, we were not taking advantage of it. The problem was that in case of an unhealthy ingester in AZ-1, there was no way to automatically fail a node group upgrade happening on AZ-2 to stop pods to continue to be evicted. PodDisruptionBudgets (PDB) are respected during the node upgrade phase, however there is no way to configure PDBs in a way to allow evictions only if the pods being disrupted belong to the same AZ.
To bypass this limitation and allow us to update multiple nodes at the same time, we developed the ZoneDisruptionBudget (ZDB) admission webhook controller, which extends the PDB concept, allowing multiple disruptions only if the pods being disrupted are in the same zone. It’s responsible for watching for changes to ZDBs and for keeping their status up to date, checking at each control-loop which pods are unavailable to calculate the number of disruptions allowed per zone at any time.
A validation admission webhook is used to intercept requests to the eviction API, accepting or rejecting them based on ZDB’s status, allowing multiple pod disruptions in zone-1, while blocking evictions from other zones.
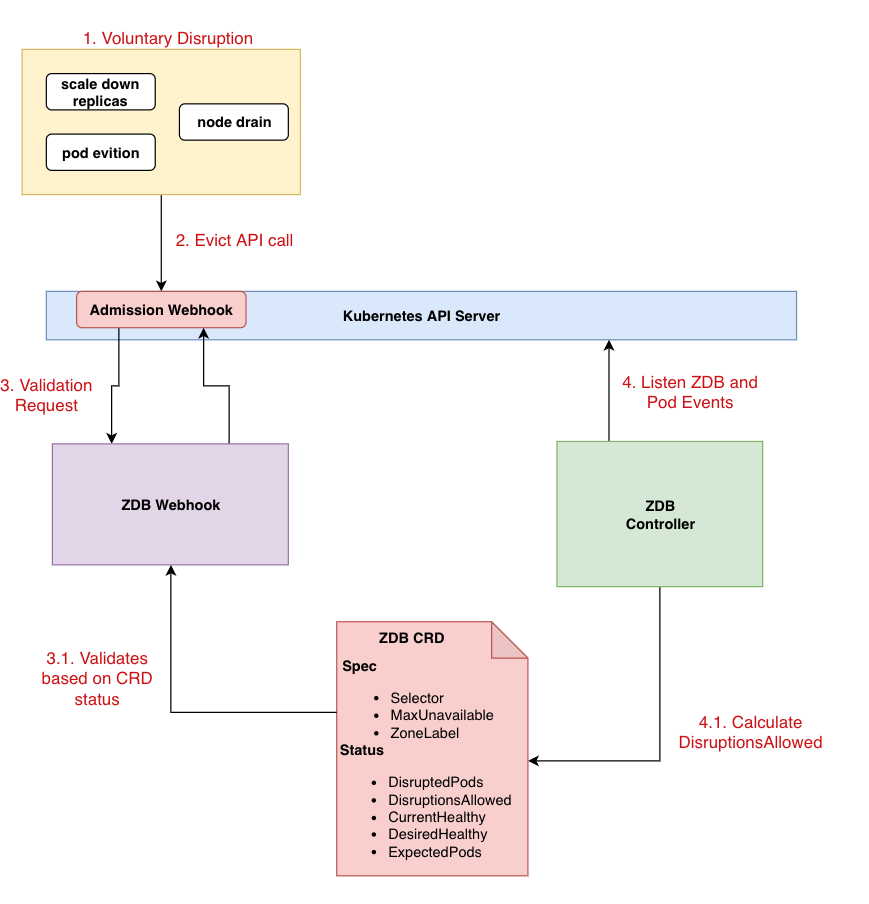
Figure 4 – ZoneDisruptionBudget controller
With ZDBs, evictions are denied if there is an unhealthy ingester in another AZ, helping us to mitigate customer impact during node group upgrades by preventing node group upgrades from proceeding in such cases.
Conclusion
Kubernetes allows pods to be spread across different zones through topology constraints but these are not taken into consideration during rollout updates, or on pod disruption budgets. For instance, it’s recommended to replicate Cortex’s ingesters across different zones for high availability, allowing for the system to continue to work in the event of a zone outage. However, the lack of zone aware deployments support forces Cortex operators to allow just a single container to be updated at once, causing long deployments and impacting the velocity in which nodes can be upgraded.
To bypass these limitations, the Amazon Managed Service for Prometheus team released two new Kubernetes controllers for zone aware rollouts and disruptions (https://github.com/aws/zone-aware-controllers-for-k8s) that can be used by any highly available quorum-base distributed application, such as Cortex, to improve the velocity of deployments in a safe way. If you’re doing stateful deployments, give it a try and join us on GitHub if you need anything.