AWS News Blog
Amazon Aurora Update – Parallel Read Ahead, Faster Indexing, NUMA Awareness
Amazon Aurora is currently the fastest-growing AWS service!
As a relational database designed for the cloud (read Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS to learn more), Aurora offers great performance, effortless storage scaling all the way up to 64 TB, durability, and high availability. Because Aurora was designed to be compatible with MySQL, our customers have been able to move existing applications and to build new ones with ease.
With MySQL compatibility “on top” and the unique, cloud-native Aurora architecture underneath, we have a lot of room to innovate. We can continue to make Aurora more efficient while still remaining compatible with all of those applications.
Today we are making three such performance improvements to Aurora, each one aimed at making Aurora more performant on a wide range of workloads commonly run by AWS customers. Here’s an overview:
Parallel Read Ahead – Range selects, full table scans, table alterations, and index generation are now up to 5x faster.
Faster Index Build – Generation of indexes is now about 75% faster.
NUMA-Aware Scheduling – When run on instances with more than one CPU chip, reads from the query cache and the buffer cache are faster, improving overall throughput by up to 10%.
Let’s dive in…
Parallel Read Ahead
The InnoDB storage engine used by MySQL organizes table rows and the underlying storage (disk pages) using the index keys. This makes sequential scans over full tables fast and efficient for freshly created tables. However, as rows are updated, inserted, and deleted over time, the storage becomes fragmented, the pages are no longer physically sequential, and scans can slow down dramatically. InnoDB’s Linear Read Ahead feature attempts to deal with this fragmentation by bringing up to 64 pages in to memory before they are actually needed. While well-intentioned, this feature does not provide a meaningful performance improvement on enterprise-scale workloads.
With today’s update, Aurora is now a lot smarter about handling this very common situation. When Aurora scans a table, it logically (as opposed to physically) identifies and then performs a parallel prefetch of the additional pages. The parallel prefetch takes advantage of Aurora’s replicated storage architecture (two copies in each of three Availability Zones) and helps to ensure that the pages in the database cache are relevant to the scan operation.
As a result of this change, range selects, full table scans, the ALTER TABLE operation, and index generation are up to 5x faster than before.
You will see the improved performance as soon as you upgrade to Aurora 1.7 (see below for more information).
Faster Index Build
When you create a primary or secondary index on a table, the storage engine creates a tree structure that contains the new keys. This process entails a lot of top-down tree searching and plenty of page-splitting as the tree is restructured to accommodate more and more keys.
Aurora now builds the trees in a bottom-up fashion, building the leaves first and then adding parent pages as needed. This reduces the amount of back-and-forth to storage, and also obviates the need to split pages since each page is filled once.
With this change, adding indexes and rebuilding tables is now up to 4x faster than before, depending on the table schema. For example, the Aurora team created a table with the following schema, and added 100 million rows, resulting in a 5 GB table:
create table test01 (id int not null auto_increment primary key, i int, j int, k int);
Then they added four additional indexes:
alter table test01 add index (i), add index (j), add index (k), add index comp_idx(i, j, k);
On a db.r3.large instance, the time to run this query dropped from 67 minutes to 25 minutes. On a db.r3.8xlarge instance, the time dropped from 29 minutes to 11.5 minutes.
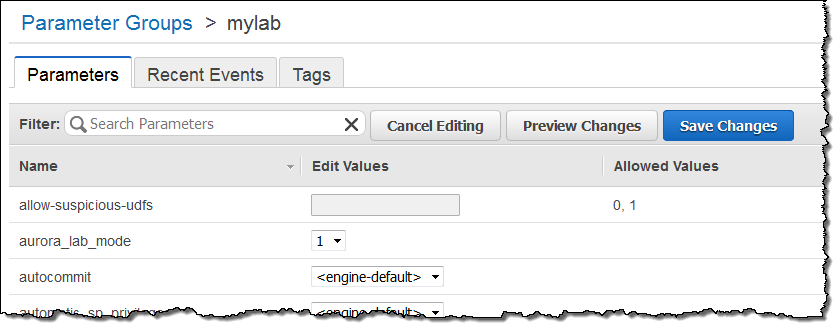
This is a brand new feature and we would like you to try it out on your non-production workloads. You’ll need to upgrade to Aurora 1.7 and then set aurora_lab_mode to 1 in the DB Instance Parameter group (see DB Cluster and DB Instance Parameters to learn more):
The team is very interested in your feedback on this performance enhancement. Please feel free to post your observations in the Amazon RDS Forum.
NUMA-Aware Scheduling
The largest DB Instance (db.r3.8xlarge) has two CPU chips and a feature commonly known as NUMA, short for Non-Uniform Memory Access. On systems of this type, each an equal fraction of main memory is directly and efficiently accessible to each CPU. The remaining memory is accessible via a somewhat less efficient cross-CPU access path.
Aurora now does a better job of scheduling threads across the CPUs in order to take advantage of this disparity in access times. The threads no longer need to fight against each other for access to the less-efficient memory attached to the other CPUs. As a result, CPU-bound operations that make heavy use of the query cache and the buffer cache now run up to 10% faster. The performance improvement will be most apparent when you are making hundreds or thousands of connections to the same database instance. As an example, performance on the Sysbench oltp.lua benchmark grew from 570,000 reads/second to 625,000 reads/second. The test was run on a db.r3.8xlarge DB Instance with the following parameters:
oltp_table_count=25oltp_table_size=10000num-threads=1500
You will see the improved performance as soon as you upgrade to Aurora 1.7.
Upgrading to Aurora 1.7
Newly created DB Instances will run Aurora 1.7 automatically. For exiting DB Instances, you can choose to install the update immediately or during your next maintenance window.
You can confirm that you are running Aurora 1.7 by running the following query:
mysql> show global variables like "aurora_version";
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| aurora_version | 1.7 |
+----------------+-------+
— Jeff;