AWS News Blog
Amazon S3: Multipart Upload
Can I ask you some questions?
- Have you ever been forced to repeatedly try to upload a file across an unreliable network connection? In most cases there’s no easy way to pick up from where you left off and you need to restart the upload from the beginning.
- Are you frustrated because your company has a great connection that you can’t manage to fully exploit when moving a single large file? Limitations of the TCP/IP protocol make it very difficult for a single application to saturate a network connection.
In order to make it faster and easier to upload larger (> 100 MB) objects, we’ve just introduced a new multipart upload feature.
You can now break your larger objects into chunks and upload a number of chunks in parallel. If the upload of a chunk fails, you can simply restart it. You’ll be able to improve your overall upload speed by taking advantage of parallelism. In situations where your application is receiving (or generating) a stream of data of indeterminate length, you can initiate the upload before you have all of the data.
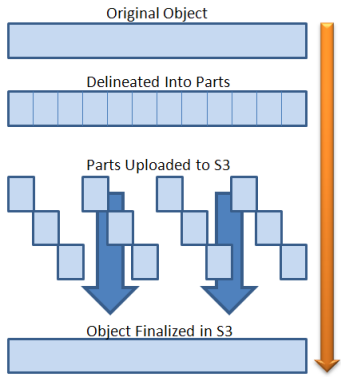 Using this new feature, you can break a 5 GB upload (the current limit on the size of an S3 object) into as many as 1024 separate parts and upload each one independently, as long as each part has a size of 5 megabytes (MB) or more. If an upload of a part fails it can be restarted without affecting any of the other parts. Once you have uploaded all of the parts you ask S3 to assemble the full object with another call to S3.
Using this new feature, you can break a 5 GB upload (the current limit on the size of an S3 object) into as many as 1024 separate parts and upload each one independently, as long as each part has a size of 5 megabytes (MB) or more. If an upload of a part fails it can be restarted without affecting any of the other parts. Once you have uploaded all of the parts you ask S3 to assemble the full object with another call to S3.
Here’s what your application needs to do:
- Separate the source object into multiple parts. This might be a logical separation where you simply decide how many parts to use and how big they’ll be, or an actual physical separation accomplished using the Linux split command or similar (e.g. the hk-split command for Windows).
- Initiate the multipart upload and receive an upload id in return. This request to S3 must include all of the request headers that would usually accompany an S3 PUT operation (Content-Type, Cache-Control, and so forth).
- Upload each part (a contiguous portion of an object’s data) accompanied by the upload id and a part number (1-10,000 inclusive). The part numbers need not be contiguous but the order of the parts determines the position of the part within the object. S3 will return an ETag in response to each upload.
- Finalize the upload by providing the upload id and the part number / ETag pairs for each part of the object.
You can implement the third step in several different ways. You could iterate over the parts and upload one at a time (this would be great for situations where your internet connection is intermittent or unreliable). Or, you can upload many parts in parallel (great when you have plenty of bandwidth, perhaps with higher than average latency to the S3 endpoint of your choice). If you choose to go the parallel route, you can use the list parts operation to track the status of your upload.
Over time we expect much of the chunking, multi-threading, and restarting logic to be embedded into tools and libraries. If you are a tool or library developer and have done this, please feel free to post a comment or to send me some email.
Update: Bucket Explorer now supports S3 Multipart Upload!
Update 2: So does CloudBerry S3 Explorer.
Update 3: And now S3 Browser!
Update 4 (2017): Removed link to the now-defunct Bucket Explorer.
— Jeff;