AWS News Blog
Reinventing Enterprise Search – Amazon Kendra is Now Generally Available

|
At the end of 2019, we launched a preview version of Amazon Kendra, a highly accurate and easy to use enterprise search service powered by machine learning. Today, I’m very happy to announce that Amazon Kendra is now generally available.
For all its amazing achievements in past decades, Information Technology had yet to solve a problem that all of us face every day: quickly and easily finding the information we need. Whether we’re looking for the latest version of the company travel policy, or asking a more technical question like “what’s the tensile strength of epoxy adhesives?”, we never seem to be able to get the correct answer right away. Sometimes, we never get it at all!
Not only are these issues frustrating for users, they’re also responsible for major productivity losses. According to an IDC study, the cost of inefficient search is $5,700 per employee per year: for a 1,000-employee company, $5.7 million evaporate every year, not counting the liability and compliance risks imposed by low accuracy search.
This problem has several causes. First, most enterprise data is unstructured, making it difficult to pinpoint the information you need. Second, data is often spread across organizational silos, and stored in heterogeneous backends: network shares, relational databases, 3rd party applications, and more. Lastly, keyword-based search systems require figuring out the right combination of keywords, and usually return a large number of hits, most of them irrelevant to our query.
Taking note of these pain points, we decided to help our customers build the search capabilities that they deserve. The result of this effort is Amazon Kendra.
Introducing Amazon Kendra
With just a few clicks, Amazon Kendra enables organizations to index structured and unstructured data stored in different backends, such as file systems, applications, Intranet, and relational databases. As you would expect, all data is encrypted in flight using HTTPS, and can be encrypted at rest with AWS Key Management Service (AWS KMS).
Amazon Kendra is optimized to understand complex language from domains like IT (e.g. “How do I set up my VPN?”), healthcare and life sciences (e.g. “What is the genetic marker for ALS?”), and many other domains. This multi-domain expertise allows Kendra to find more accurate answers. In addition, developers can explicitly tune the relevance of results, using criteria such as authoritative data sources or document freshness.
Kendra search can be quickly deployed to any application (search page, chat apps, chatbots, etc.) via the code samples available in the AWS console, or via APIs. Customers can be up and running with state the art semantic search from Kendra in minutes.
Many organizations already use Amazon Kendra today. For example, the Allen Institute is committed to solving some of the biggest mysteries of bioscience, researching the unknown of human biology, in the brain, the human cell and the immune system. Says Dr. Oren Etzioni, Chief Executive Officer of the Allen Institute for AI: “One of the most impactful things AI like Amazon Kendra can do right now is help scientists, academics, and technologists quickly find the right information in a sea of scientific literature and move important research faster. The Semantic Scholar team at Allen Institute for AI, along with our partners, is proud to provide CORD-19 and to support the AI resources the community is building to leverage this resource to tackle this crucial problem”.
Introducing New Features in Amazon Kendra
Based on customer feedback collected during the preview phase, we added the following features to Amazon Kendra.
- New scaling options for the Enterprise Edition, as well as a newly-introduced Developer Edition (see details below).
- 3 new Cloud Connectors: OneDrive, Salesforce, and ServiceNow (in addition to S3, RDS, and SharePoint Online).
- Expertise on 8 new domains: Automotive, Health, HR, Legal, Media and Entertainment, News, Telecom, Travel and Leisure (in addition to Chemical, Energy, Finance, Insurance, IT, and Pharmaceuticals).
- Faster indexing, and improved accuracy.
Indexing Data with Amazon Kendra
For the purpose of this demo, I downloaded a small subset of Wikipedia (about 50,000 web pages). I uploaded the individual files in HTML format to an Amazon Simple Storage Service (Amazon S3) bucket.
Heading out to the Kendra console, I start by creating a new index, giving it a name and a description. One click is all it takes to enable encryption with AWS Key Management Service (AWS KMS).

After 30 minutes or so, the index is in service. I can now add data sources to it.

Adding my S3 bucket is extremely easy. I first enter a name for the data source.
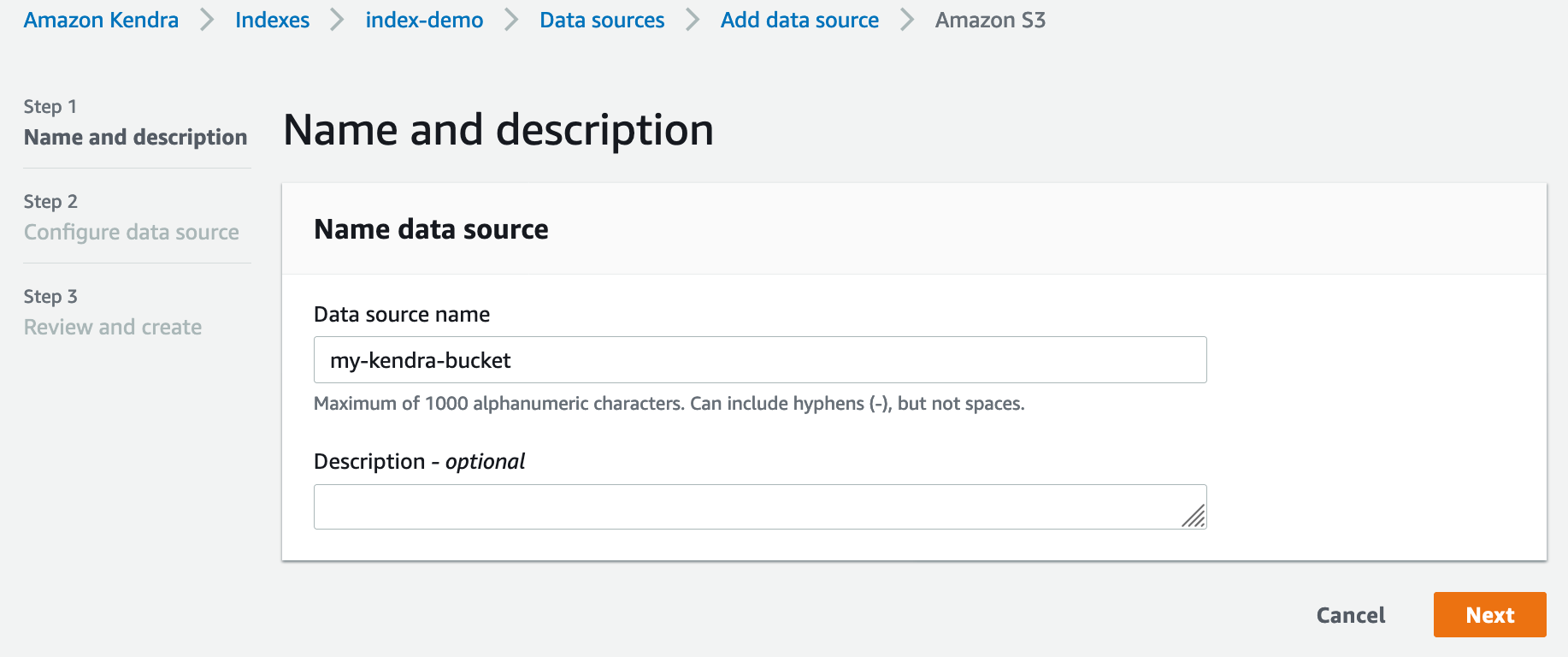
Then, I define the name of the S3 bucket. I also need to specify the name of the IAM role used by Kendra, either selecting an existing role or creating a new one.
I’m given the choice to schedule synchronization at periodic intervals, in order to refresh the index with new data added to the data source. I go for a daily refresh running at midnight.
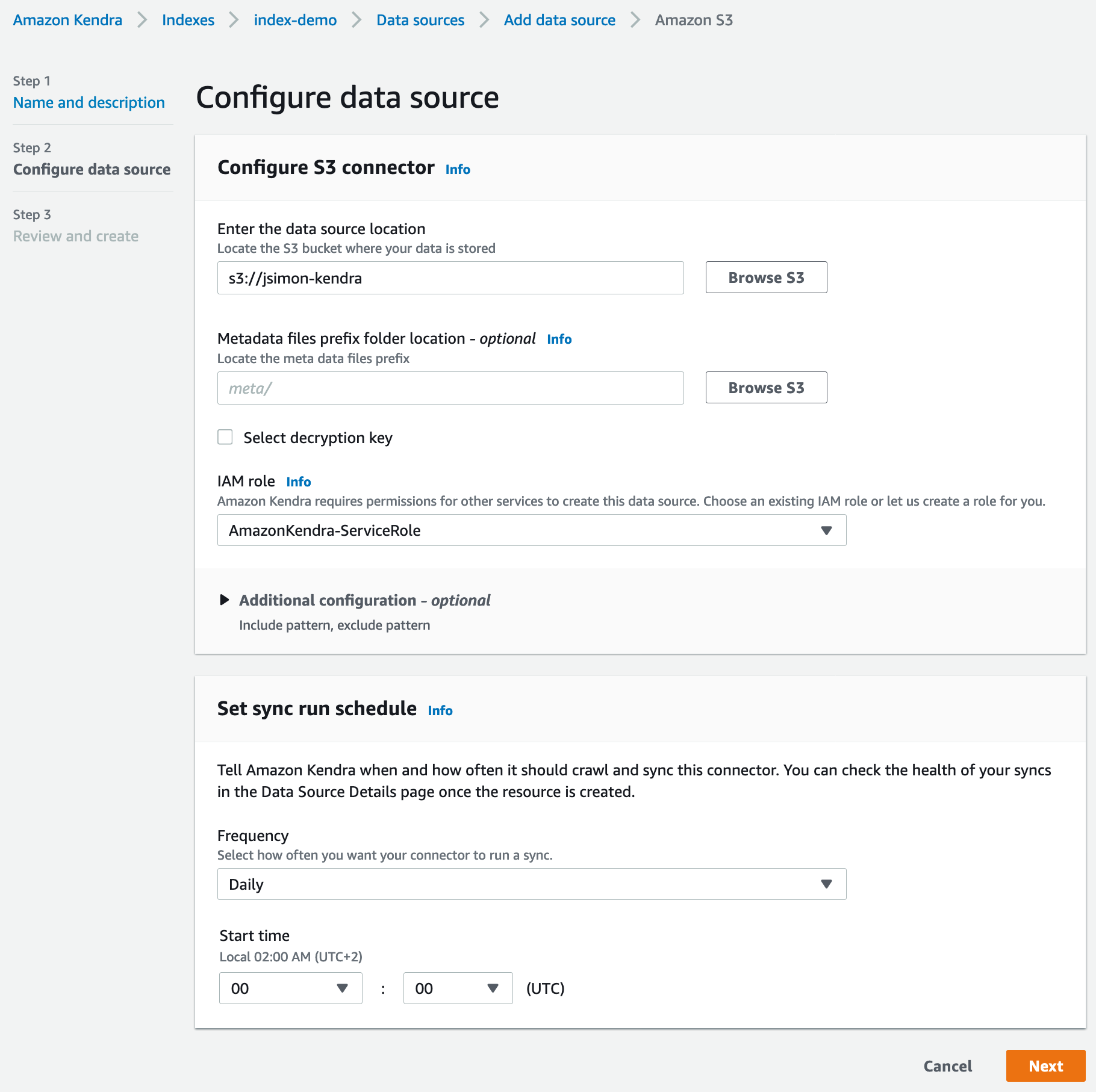
The next screen lets me review all parameters, and create the data source. Once it’s active, I launch the initial synchronization by clicking on the “Sync now” button.

After a little while, synchronization is complete. Moving to the test window, I can now start running queries on the index.
Querying Data with Amazon Kendra
While working on one of my posts the other day, I listened to a Jazz song that I really liked, played by a musician named Thad Jones. Knowing absolutely nothing about Jazz players, I’m curious whether Kendra can help me learn more.

Unsurprisingly, this query matches a large number of documents. However, Kendra comes up with a suggested answer, a high confidence answer to my query. It points at a specific paragraph in one of indexed pages. Relevant content is highlighted for more convenience, and I can immediately see that this is the right answer to my query. No need to look any further! Accordingly, I give it a thumbs up so that Amazon Kendra knows that this is indeed a good answer.
Looking to learn more about Thad Jones, I ask a second question.

Once again, I get a suggested answer. This time, Kendra went one step further by returning the exact answer from the document, instead of just returning the document itself. This shows how Kendra is able to understand context and extract relationships, in this case the link between an individual and their city of birth.
Still curious, I ask a third question.

I get another suggested answer, and it’s once again right on target. The information I’m looking for is in the first sentence: Thad Jones has played with Count Basie. As you can see, the paragraph above doesn’t even include the word “play”. Yet, Amazon Kendra interpreted my question correctly. Thad Jones is a musician: if I’m asking about him playing with someone else, it’s very likely that I’m looking for other musicians, not for sport partners! This ability to understand natural language queries and to extract deep domain knowledge is what makes Amazon Kendra so accurate.
Getting Started
Amazon Kendra is available today in US East (N. Virginia), US West (Oregon), and Europe (Ireland).
You can pick one of two editions.
The Enterprise Edition lets you search up to 500,000 documents, and run up to 40,000 queries per day for $7 per hour. You will also be charged $0.000001 per document scanned, and $0.35 per hour per connector when syncing. If you need more indexing or querying capacity, you can now scale each independently: $3.5 per hour for additional 40,000 queries, and $3.5 per hour for additional 500,000 searchable documents.
The Developer Edition has the same features as the Enterprise Edition. However, it’s limited to 4,000 queries per day, on up to 10,000 searchable documents across 5 data sources. No scaling options are available. Please note that the Developer Edition runs on a single availability zone, which is why it shouldn’t be used for production purposes.
Please give Amazon Kendra a try! We’d love to get your feedback, either through your usual AWS Support contacts, or on the AWS Forum for Kendra.
- Julien