Amazon Web Services ブログ
公益システムの信頼性向上のためのデータに基づいたクラウドベースの電力グリッドシステムモデルの活用
この記事は、「Using cloud-based, data-informed, power system models to engineer utility reliability」を翻訳したものになります。
グリッドシミュレーションは、計画から運用に至る電力会社のエンジニアリング・バリューチェーンにおけるさまざまなアプリケーションを支援します。公益事業者は、脱炭素化、分散化、デジタル化の目標に向かい、高品質のグリッドネットワークの測定指標を利用しながら、モデルベースのシミュレーションを今まで以上に詳細かつ正確に、高速化することを求められています。このブログでは、データに基づいたモデルベースのグリッドエンジニアリングに関連するいくつかの課題を紹介し、電力会社のエンジニアが AWS を使用した非常にスケーラブルで費用対効果の高い方法で、グリッドシミュレーションのニーズを満たしながら、データからより多くの価値を引き出す方法について説明します。
何十年もの間、世界中の電力システムエンジニアは、さまざまな送電網管理ワークロードに物理ベースの送電網モデルを使用してきました。パワーエレクトロニクスの進歩は、高電圧直流(HVDC)伝送、フレキシブル交流伝送システム(FACTS)、分散型エネルギー電源(DER)を通じて電力業界に広がっています。現在、電力会社は電力グリッド全体に分散した多くの種類のデバイスやセンサー、および非線形な特性を持つ相互作用を考慮するため、これまで以上に現実的なグリッドモデルを構築する必要があります。その結果、電力会社のモデルはさらに大きくなり、モデルベースの解析はより複雑になり、より多くの計算能力が必要になりました。このようにグリッドモデルの規模の拡大と複雑さの増大は、電力会社の以下のニーズにも表れています。
- 二次配電ネットワークのモデリング
- 三相送電ネットワークのモデリング
- 統合送配電(T&D)システムのモデリング
二次配電ネットワークのモデリング
ハワイアン・エレクトリックでは、非化石ベースのエネルギー生成に最大の貢献をしているのは、屋上型(ルーフトップ)太陽光発電になります。ハワイアン・エレクトリックの再生可能エネルギー生産の約半分は、「顧客設置型グリッド接続型」の再生可能エネルギーによるものであり、そのほとんどが屋上太陽光発電で占められています。これらの屋上ソーラーパネルに加えて、同時に増加している顧客世帯用蓄電池設備は、配電サービス用変圧器の背後の小さな二次配電線に接続されています。この小さな二次配電線の電気的特性(抵抗対リアクタンス比 (R/X) ~ 10)は、一次配電線(R/X ~ 1)や送電導線 (R/X ~ 0.1)とは大きく異なります。スマートメーター、スマートインバータ、その他のセンサーからの電圧測定では、配電サービス用変圧器の背後で最大 10V (公称 120V の場合)、最悪の場合はそれ以上の電圧拡散が確認されています。このような大きな電圧拡散は、二次接続された DER(分散電源)がない状態でも観測されており、長距離の共有二次ネットワークのトポロジのみが原因となっています。その結果、電力会社のエンジニアは、配電電圧が最も重要な場所である顧客宅付近の電圧に与える大きな影響を正確に把握するために、二次配電とサービス低下を考慮したグリッドモデルを求めています。
三相送電ネットワークのモデリング
従来の送電解析のほとんどは、送電系統がねん架(transpose)されており、適切にバランスが取れていることを前提としています。この前提は、電力グリッドシミュレーションツールやエンジニアが、高度にメッシュ化された3相の送電網を計算上はるかに容易に解ける正弦波等価回路を使用してモデル化できるようにしたため、非常に強力なものとなっています。しかし、いくつかの電力会社が、フェーザー計測装置(PMU)やシンクロフェーザーからの追加計測値を分析した結果、送電網は私達が望むほどにはバランスしていないことが判明しました。定常運転時でさえ、重大なインバランス(不均衡)状態がしばしば観測されます。これらのインバランスは、いくつかの要因に起因すると考えられます:
- 実際には送電線は常にねん架されている訳ではない。
- DER の普及に伴い、配電網が受動的な負荷であるのとは対照的に、より能動的な部分が出てくると本来のアンバランスな性質も送電網に導入されるようになりました。
これにより、送電網の三相解析が必要となり、計算負荷が増えています。
統合送配電(T&D)システムのモデリング
ポートランド・ゼネラル・エレクトリック(PGE)は、2021 年 10 月にオレゴン州公益事業委員会に提出した資料で、2030 年までには最も暑い日や最も寒い日の必要電力需要の 25% にものぼる電力量が、太陽光パネル、バッテリー、電気自動車などの顧客世帯の DER から得られると試算しています。世界中の他の電力会社も配電システムから必要な電力に対して、同等の、あるいはそれ以上の貢献を期待しています。多くのエネルギー資源が配電網と統合され、相互接続された送電網に双方向の電力が流れるようになると送電網の位相アンバランスが悪化する可能性があるだけでなく、配電網が送電網における定常状態の電圧安定度限界に大きな影響を与える可能性があります。このため、T&D グリッドのモデリングとシミュレーションを組み合わせることへの関心が高まっています。
これら3つの要因が相まって、グリッドモデルの規模はこれまでとは桁違いの大きさになりつつあります。例えば、約 100 万人のエンド顧客にサービスを提供する垂直統合型の投資家所有の電力会社では、グリッド全体を3つのレイヤでモデル化し、バランスのとれた状態を想定をせずに、500kV 以上から顧客世帯につながる二次配電側まで、そのすべてをモデル化すると 600 万コンポーネント以上のグリッドモデルを作成することになります。多くの場合、最も正確な分析を行うには、設計者は電力会社の垣根を越えて、数十億以上のコンポーネントからなる相互接続されたグリッド全体をモデル化する必要があります。電力会社のエンジニアリングリーダーは、ここで選択を迫られています。それは、より小さくシンプルではあるが、将来のための精度に欠ける「同等」のグリッドモデルでやり過ごすか、コンピュータサイエンスとクラウド技術の進歩を活用して、より正確で現実的なグリッドモデルを手頃なコストで作成するかということです。
複雑なモデリングに加え、電力会社はグリッドデータの「津波(tsunami)」に見舞われています。Utility Analytics Institute によると、2017 年には 2.7 ゼタバイトのデジタルデータがあり、この数は 2025 年までには 175 ゼタバイトに膨らむと予想されています。ユーティリティ企業にとってわかりやすい例は、スマートメーターからのデータの爆発的な増加です。ユーティリティ企業は、顧客1人あたり月1回の読み取りから、顧客1人あたり1日96回の読み取り(次世代スマートメーターではさらに増加)になり、顧客レベルのエネルギー利用量データだけでも 287,900% の増加を示しています。電力網のデジタル化によって増加したデータは、AI/ML や確率論的手法を利用して直接分析することができ、異常検出、負荷モデリング、負荷予測など、いくつかのグリッド管理のユースケースに活用することができます。しかし、多くのユーティリティ企業のエンジニアリーダーにとって魅力的なのは、状態推定やモデルチューニングといったモデルベースのエンジニアリング技術と組み合わせてデータを利用できる可能性があることです。電力グリッドのエンジニアは、増え続けるグリッドからのデータに加えて、分散型、顧客中心型、動的な電力グリッドの変動特性を考慮し、非常に多くのシナリオを分析する必要があります。さらにこれらの課題に加えて、ユーティリティ企業がユースケースや部門ごとに異なるツールを使用している現在のエンジニアリングシステムの状況も難しさに拍車をかけています。このため、同じグリッドに対して異なるツールが異なる結果をもたらし、モデルが断片化されるとともに、異なる供給元システムから大量のデータ転送が必要になります。データとモデルの重複は、ストレージとコストの問題を引き起こします。時間が経つにつれて、異なる場所にある重複した情報は、より多くの問題を引き起こすことになります。
迅速なユーティリティモデリングのための AWS の選択
AWS の豊富な AI/ML サービスに電力事業データを投入することで、いくつかの重要なユースケースを解決できます。既存のグリッドシミュレーションアプリケーションの実行に適切な AWS コンピュートインスタンスを活用することで、短期間でパフォーマンスを向上させることができます。しかし、AWS の価値を最大限に引き出すには、電力会社のサービス領域全体をさらに超えて、関連する測定値に基づいたリアルタイムの電力フロー/最適化計算を可能にするクラウドベースのアーキテクチャを活用して、グリッドモデルベースエンジニアリングの分野を再発明し変革する必要があるのです。以下は、そのような変革を促進するためのハイレベルなアーキテクチャのフレームワークです。
信頼あるシングルソース(single source-of-truth)のグリッドモデルとデータ
まず図1のような基礎的なレイヤから始め、その上に他のすべてを構築していきます。これはグリッドモデルであり、すべてのアプリケーションで共有されるデータレイクです。データ(計測と予測)は、AWS データレイクにバッチ処理で取り込むことも、リアルタイムでストリーミングデータも取り組むことも可能です。Amazon Simple Storage Service (Amazon S3)は、データレイクを作成するためのコスト効率と耐久性の高いサービスを提供し、これにより、データメッセージング用のETLパイプラインや異常検知、電力負荷や発電量の予測などの特定のユースケースの AI/ML パイプラインの作成が可能になります。物理学ベースの初期グリッドモデルは、ユーティリティグリッドの「設計時の状態」の情報に基づいて作成することができます。これは電力会社固有の設計/建設基準や GIS などのトポロジ・システムには非常に有効です。構築後は、SCADA、停電管理、ネットワーク管理、またはその他の関連する公益事業アプリケーションからストリームされるデータに基づいて、グリッドの「実運用状態」モデルを自動的に更新、維持することができます。一般的に、電力グリッドのモデリングとシミュレーションのツールは、グリッドネットワークのトポロジをリレーショナルデータベースに格納します。Amazon Relational Database Service (RDS) や Amazon Aurora Serverless を使えば簡単に始められますが、Amazon Neptune というフルマネージのグラフデータベースを活用して、グリッドのトポロジを保存することも可能です。Amazon Neptune は、Gremlin による効率的なグラフ探索(トラバーサル)を可能にします。グラフ探索は、新しいセンサー、DER、または電気自動車(EV)充電ステーションを最適に配置するためのグリッド設計など、いくつかのユーティリティ・アルゴリズムに不可欠なものとなっています。
この基礎的なレイヤの主な特徴は、すべてのグリッドエンジニアリング・アプリケーションに対して、単一の信頼あるシングルソース(single source-of-truth)を保持することです。これにより、モデルやデータの重複、それに伴う時間やコスト、複数の情報ソースを持つことで発生する精度や管理上の問題を回避することができます。
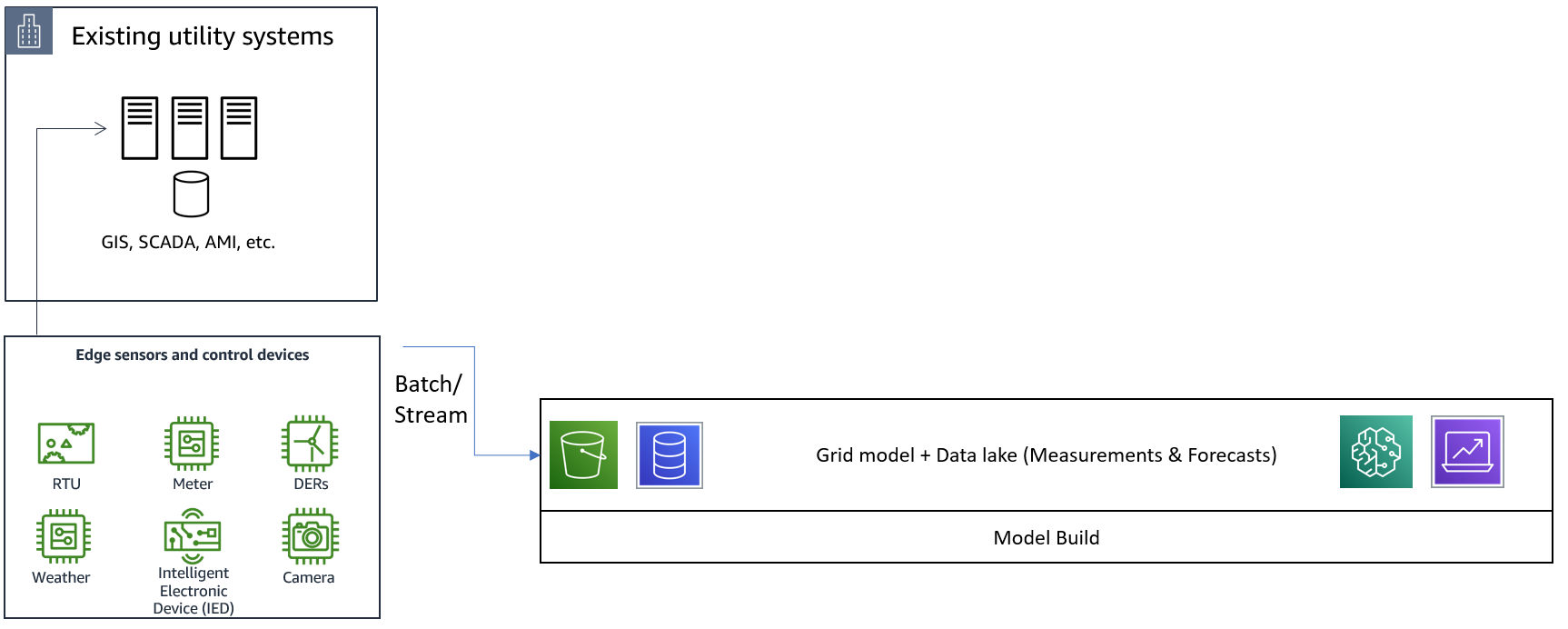
図1: 信頼あるシングルソース:グリッドモデルとデータレイク
非線形微分代数方程式と非凸最適化問題計算に深層学習(ディープラーニング)とハイパフォーマンスコンピューティング(HPC)を活用
次に図2に示すように、数学的な力仕事の大部分を行う中間層を構築します。この層には、定常解析のための代数方程式、動的解析や過渡解析のための微分方程式、最適電力フローのような非線形・非凸最適化問題を解くためのアルゴリズムが含まれています。これらのアルゴリズムは、図2のアーキテクチャ図の基礎レイヤからグリッドモデルやデータを使用するため、非常に大規模なグリッドモデルでは計算コストが高くなることがあります。機械学習アルゴリズムの効率性から人気を集めている深層学習アルゴリズムや強化学習アルゴリズムは、PyTorch、MXNet、TensorFlow など最も人気のある深層学習フレームワークやツールの最新バージョンが統合された Amazon SageMaker または AWS Deep Learning AMI を活用することが可能です。実装する数値解析アルゴリズムの仕様に応じて、CPU、GPU、FPGA インスタンスを必要に応じて柔軟に「適材適所」の選択により、コストと計算結果を得るまでの時間を削減することが重要です。HPC on AWS は、何万もの並列計算に対応し、性能ニーズとコスト制約のバランスをとることができ、この中間レイヤの重要な要素になります。例えば、HPC に最適化された新しい EC2 インスタンスである Hpc6a は、同等の x86 ベースのコンピュート最適化インスタンスと比較して、最大 65% の価格性能の向上を実現しています。HPC 計算ノードに分散する密結合の数値解析ワークロード間で低レイテンシの変数交換を行うには、独自の OS バイパスネットワーク機構を利用してスループットを向上させ、数千 CPU や GPU への拡張を可能にする Elastic Fabric Adapter(EFA)の上でメッセージ・パッシング・インターフェース(MPI)または NVIDIA Collective Communications Library(NCCL)を使用することが可能です。
AMI(Advanced Metering Infrastructure:スマートメーター通信システム)ベースの負荷測定、AI/ML 駆動の確率的負荷予測、SCADA ベースの電圧測定など、これらの数値アルゴリズムで使用する測定や予測の共有には、Amazon FSx for Lustre を利用することができます。このファイルシステム(Amazon FSx for Lustre)を適切な Amazon S3 バケット(アーキテクチャの基礎レイヤ)とリンクさせることで、データレイクから直接データにアクセスすることができます。
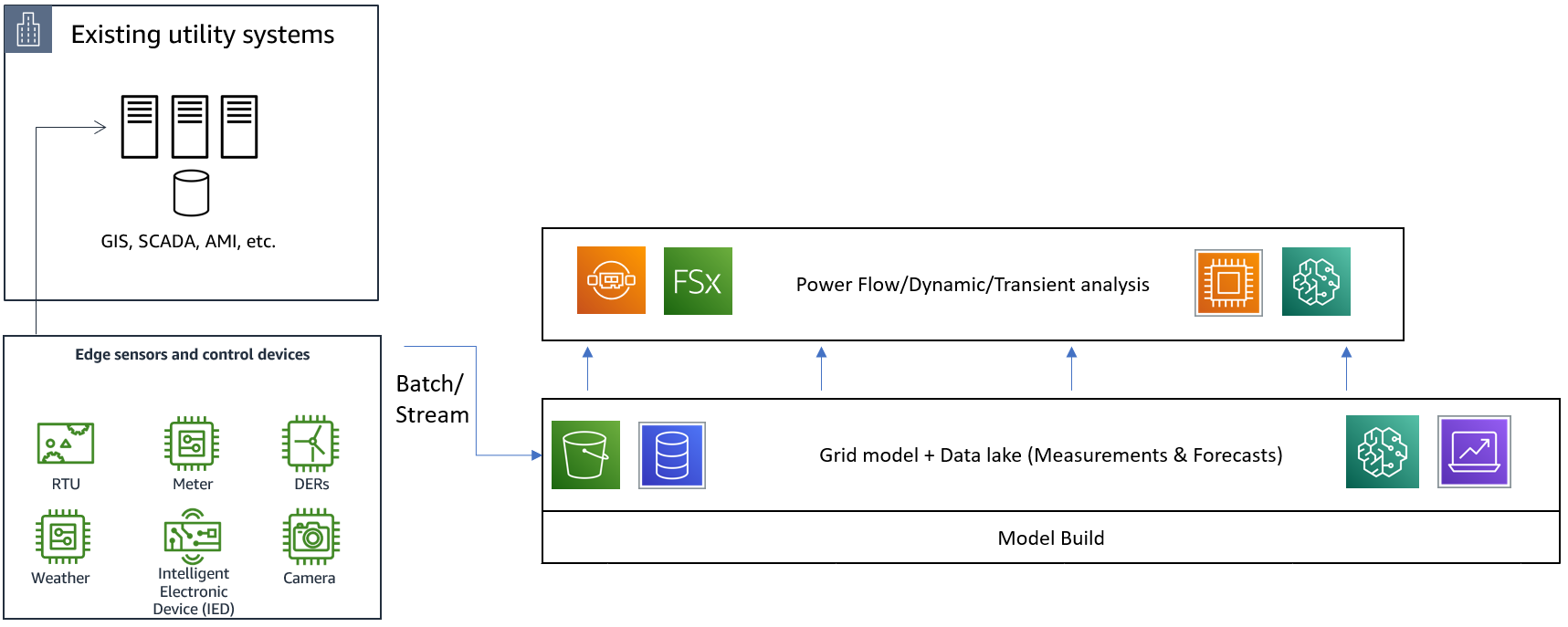
図2: グリッドモデルや基礎層のデータを用いた数値解析アルゴリズム
HPC 技術によるパフォーマンス向上の例として,積載量 60 トンの貨物飛行船を開発しているフランスのスタートアップ企業 FLYING WHALES では,数値流体力学(CFD)ジョブを 15 倍高速化して実行できるようになりました。この成果は EC2 C5n.18xlarge インスタンスと EFA によって使用できる計算パワーとノード間ネットワーク性能向上を実現することにより高速処理することが可能になりました。また、Woodside Energy は、AWS 上の 100 万以上の vCPU で震探データを分析し、オンプレミスのシステムより 150 倍速い数時間で分析結果を得ることが出来ました。AWS HPCが大規模なパフォーマンス向上を実現している例は、業界を問わず他にもいくつかあり、電力工学計算も例外ではないはずです。
ビジネスロジック主導の電力工学アプリケーション
最後に、最上位レイヤは、ビジネスやエンジニアリングのニーズに基づいてアプリケーションを構築します。送電ニーズの評価や DER 計画/配電回路設計など、グリッドの計画や分析を支援するオフラインアプリケーション(訳註:「オフラインアプリケーション」の意味はデータ発生元に直接接続していない、データ発生時から時間が経過したものを利用するアプリケーションを意味します)では、基礎レイヤのデータレイクからデータを照会することが可能です。リアルタイムの状態評価、状況認識(situation awarenss)、電力グリッドのアクティブ制御のためにリアルタイムデータをベースにした「オンライン」アプリケーションの場合、Amazon S3 ベースのデータレイクへのデータ取り込みを担うデータストリームを利用することでリアルタイムデータ連携/処理できます。すべてのアプリケーションは、基礎レイヤからグリッドモデルを取得します。これにより、すべてのビジネスアプリケーションが共通の情報ソースを使用することができます。さらに、最上位レイヤのすべてのアプリケーションは、複雑な最適化問題や微分・代数方程式を解くという非常に重い処理を中間レイヤに委任し、一方でビジネスロジック自体をアプリケーション内に実装します。
最上位レイヤのアプリケーションでは、開発者はコンピュートやデータベース、ロギングやデバッグなどの技術カテゴリーに応じた幅広い機能とサービスを選択することができます。注目すべきは、このアプリケーション開発には、必ずしもソフトウェアエンジニアリングの専門家が必要ではないことです。例えば、電力エンジニアは AWS Lambda を使うことで、既存のグリッドシミュレーションツールと同じように、サーバーのプロビジョニングや管理を気にせずにプログラムコードを実行するだけでよいのです。AWS Lambda は高可用性を備えたコードの実行とスケーリングに必要な様々なことを引き受けます。エンジニアリングの研究やワークフローによっては、異なるコードのブロックを段階的にオーケストレーション(連携・統合)することが必要な場合があります。これは、ビジュアルワークフロー開発ツールを使用して分散アプリケーションやマイクロサービスのコンポーネントを簡単に連動させるフルマネージドサービスである AWS Step Functions を使用して実現できます。最終的にエンジニアは ML 推論エンドポイントをリアルタイム処理に使用し、事前に学習された ML モデルを使用して予測分析を行うことができます。また、Amazon SageMaker Canvas を使用することもできます。これは、開発コードを書かずに ML モデルを構築して精度の高い予測を生成するための新しいビジュアル開発機能で、ML の専門知識を必要としません。

図3: 共通のモデル、データ、計算技術を共有するビジネスドリブンなアプリケーション
アプリケーション例として、モデル管理について見てみましょう。これは、Amazon EventBridge でスケジュールされたイベントを使用して、時系列、グリッドの状態推定をベースにした電力フロー、および AMI や他のグリッドのセンサーから入手できる測定データを定期的に比較するトリガーとして実装することができます。この場合、アプリケーションは電力フローの計算を中間レイヤに委ね、中間層はニュートンラプソン(Newton-Raphson)法や他の数値解析技術を使用して計算を実行します。様々な場所で指定された期間の測定データは、基礎レイヤから検索されます。グリッドの状態の計算値に対する測定値の時系列誤差プロファイルに基づき、アプリケーションは、必要に応じてグリッドインピーダンスを自動的に調整することができます。これは、SCADA/OMS や既存のビジネスプロセスでは捕捉できないような現場のイベントを捕捉するのに役立ちます。このようなアプリケーションは、AWS Lambda を使用して実装することで、ミリ秒単位の課金で処理リクエストに応じて拡張させることができます。これはアプリケーションがここで提案しているアーキテクチャ・フレームワークを活用し、他のすべてのアプリケーションで共有されているグリッドモデルを定期的に更新することによって、さらにこのフレームワークを有益にする例です。エンジニアリング、オペレーション、ビジネスの各分野の電力会社関係者は、3つのレイヤーのいずれからでもアプリケーション、シミュレーション・アルゴリズム、データに直接アクセスすることができます。サードパーティのエンジニアリングコンサルタントやベンダーのアプリケーションも同じ環境に安全にアクセスでき、すべてのグリッドエンジニアリング研究、シミュレーションツール、制御システムが同じグリッドモデル、データ、計算技術を共有できるようにします。
電力会社やその他の業界関係者は、AWS Energy & Utilities チームとの共同パートナーシップモデルを通じて AWS テクニカルサポートを活用し、このフレームワークを実装、評価することができます。詳細については、AWS Power and Utilities をご覧ください。
本ブログは、ソリューションアーキテクトの丹羽が翻訳しました。原文はこちらです