AWS Partner Network (APN) Blog
Index Engines’ Intelligent Management of Legacy Backup Data to AWS in Support of Long-Term Retention
By Sabina Joseph, Head of Global Storage Partnerships and Alliances, Amazon Web Services
Index Engines is an APN Technology Partner
Data is the lifeblood of every organization. Data that is generated by people is the foundation of future decisions, ideas and products that will represent business growth and success. However much of this data, the aged data that is typically archived on legacy backup tapes, is often hidden in offsite storage vaults and is not easily leveraged. Beyond leveraging the intellectual property on legacy tapes, organizations also face legal and compliance requirements including privacy regulations and eDiscovery requests related to data that only resides on these tapes.
In my opinion, backup tapes are not a viable archive for long-term retention data. Backup tapes cannot be searched for specific content such as historical research and documents, are difficult to manage under legal holds, and data retention policies cannot be directly enforced on them. In addition, since many organizations have thousands to hundreds of thousands of tapes, a mix of different tape types (LTO, DLT, etc.) and backup formats, the cost of simply maintaining tape infrastructure is an issue.
Introducing Index Engines
Index Engines, an APN Technology Partner, has developed an S3 interface to AWS in order to transform organizations’ long-term retention strategies. Index Engines sees the value of migrating legacy data hidden on backup tapes to AWS, making it accessible and available to organizations in the cloud. Making data available in AWS enables organizations to manage it, secure it and understand it versus maintaining it in an offline, proprietary archive. Additionally, the cost of maintaining a legacy infrastructure to manage old backup tapes is quickly surpassing the efficiency and costs of managing this data of value on the AWS Cloud.
Index Engines delivers direct access to files and email on tape. Using patented indexing technology, backup catalogs can be ingested and managed, tapes directly indexed, and data made searchable to find specific content. Organizations can migrate a deduped data set of files, email, or other tape content as required, directly to AWS. Index Engines provides a number of flexible ingestion methods that allow organizations to implement the solution in their data center or ship tapes to a secure Index Engines certified processing lab. Once migrated, the original backup tape is no longer necessary and the tape can be disposed of. This allows the organization to go tapeless and eliminate tape infrastructure.
Typical Workflow
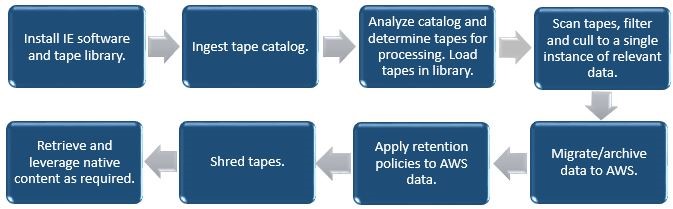
The typical workflow for using Index Engines uses a straightforward set of steps. The results of these steps provides a streamlined method of selecting and identifying both the tapes needed for a particular operation, and the content that needs to be extracted.
Step 1: Backup Catalog Management: Index Engines ingests the backup catalog, eliminating the dependence on the backup software. Index Engines supports direct ingestion of the backup catalog from IBM TSM, Veritas NetBackup, CommVault, and EMC Networker, without ever touching a physical tape. Additionally, Index Engines supports rebuilding the catalog directly from tape, removing the need for the active catalog, for Veritas Backup Exec, HP Data Protector, and CA ArcServe. Once the ingestion is complete, the backup application is no longer needed.
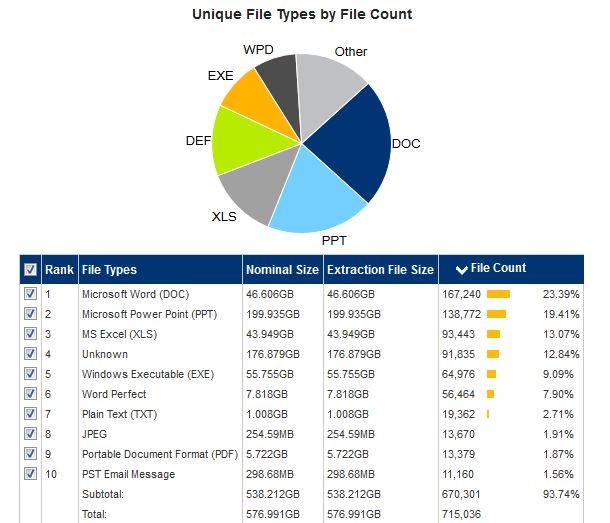
Step 2: Legacy Data Profiling: Once the catalog is ingested it can be filtered or profiled. Profiling allows the user to search, filter and report, ultimately narrowing down the dataset. Some of the reports that come from the profiling process contain items such as backup dates, servers, file owners, extensions and other metadata. Many organizations use profiling to eliminate tapes that no longer have data with any business value.

Step 3: Tape Indexing/Scanning: Once a relevant set of tapes are selected through profiling, they are scanned. Scanning is an indexing process that captures additional metadata on the tape contents, including email and mailboxes in Exchange or Notes databases. This process can be light – simple validation and selection data, or deep, which can include full content indexing. Document signatures are generated as part of this step, allowing for deduplication of the contents.
Step 4: Migration to AWS: With tapes scanned and the relevant data tagged for migration, data can be extracted and stored in AWS via the S3 interface. This process does not require the original backup software. Leveraging S3, data of value is migrated in a forensic archive that ensures no spoliation of the content occurs. The archive is searchable and contains all the native files, ensuring they are intact and forensically sound in order to support even the most stringent legal requests. Requests can produce native files and email, or in load file format compatible with most eDiscovery and analytics solutions. Retention and expiration policies also can now be applied to the data allowing for controlled disposition.
Step 5: Retirement of Legacy Infrastructure: Now that data of value is archived in AWS, the legacy tape infrastructure can be retired. This includes non-production backup software support and maintenance, tape libraries, and other infrastructure that is no longer necessary.
Index Engines – Benefits
Migration of tape contents to AWS makes the data accessible and easier to manage versus offline tape storage. Some of the key benefits provided by Index Engines include:
- Reduce the risk and liability hidden in legacy tape data
- Better manage content in line with corporate data policies
- Reduce the infrastructure and storage footprint in the data center
- Provide better access to unstructured data
- Facilitate knowledge workers’ use of “dark data”
In addition, current ROI analysis show a high percentage of potential savings after three years based on current maintenance, offsite storage, eDiscovery service provider and associated legacy backup data fees.* The combination of the benefits of the Index Engine solution on AWS, combined with the potential ROI savings is a powerful combination in helping to manage the ever growing digital assets and records within the organization.
To learn more about this product, watch the company’s video:
For more information, visit: www.indexengines.com/aws
*Savings comparison can be seen here.