AWS Architecture Blog
Category: Amazon Simple Storage Service (S3)
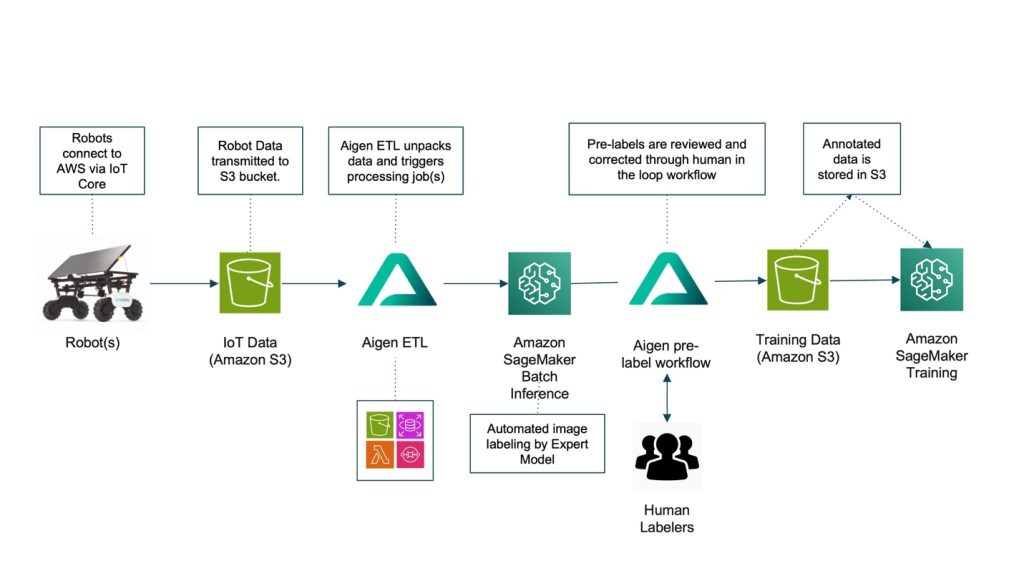
How Aigen transformed agricultural robotics for sustainable farming with Amazon SageMaker AI
In this post, you will learn how Aigen modernized its machine learning (ML) pipeline with Amazon SageMaker AI to overcome industry-wide agricultural robotics challenges and scale sustainable farming. This post focuses on the strategies and architecture patterns that enabled Aigen to modernize its pipeline across hundreds of distributed edge solar robots and showcase the significant business outcomes unlocked through this transformation. By adopting automated data labeling and human-in-the-loop validation, Aigen increased image labeling throughput by 20x while reducing image labeling costs by 22.5x.
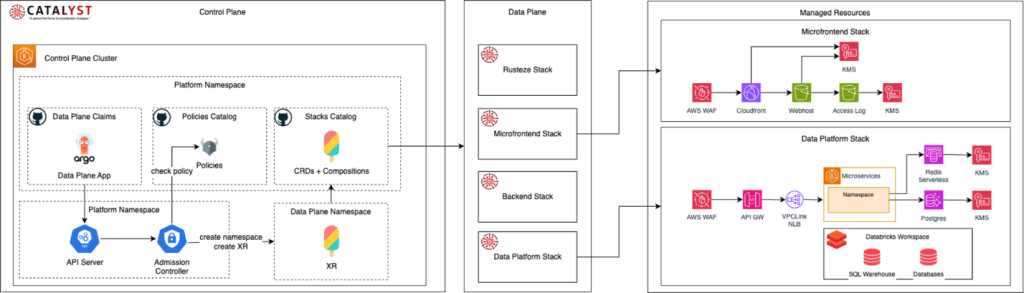
Digital Transformation at Santander: How Platform Engineering is Revolutionizing Cloud Infrastructure
Santander faced a significant technical challenge in managing an infrastructure that processes billions of daily transactions across more than 200 critical systems. The solution emerged through an innovative platform engineering initiative called Catalyst, which transformed the bank’s cloud infrastructure and development management. This post analyzes the main cases, benefits, and results obtained with this initiative.

BASF Digital Farming builds a STAC-based solution on Amazon EKS
This post was co-written with Frederic Haase and Julian Blau with BASF Digital Farming GmbH. At xarvio – BASF Digital Farming, our mission is to empower farmers around the world with cutting-edge digital agronomic decision-making tools. Central to this mission is our crop optimization platform, xarvio FIELD MANAGER, which delivers actionable insights through a range […]
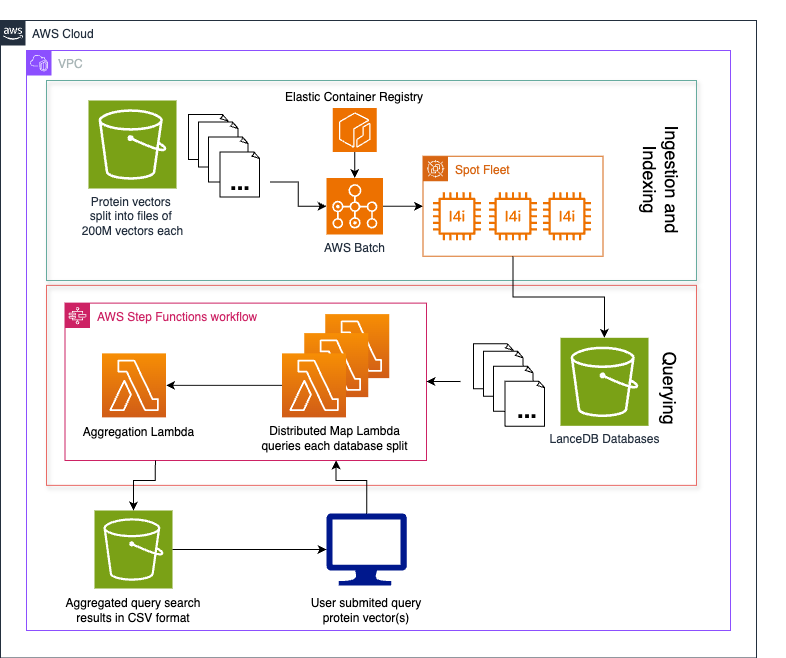
A scalable, elastic database and search solution for 1B+ vectors built on LanceDB and Amazon S3
In this post, we explore how Metagenomi built a scalable database and search solution for over 1 billion protein vectors using LanceDB and Amazon S3. The solution enables rapid enzyme discovery by transforming proteins into vector embeddings and implementing a serverless architecture that combines AWS Lambda, AWS Step Functions, and Amazon S3 for efficient nearest neighbor searches.

From virtual machine to Kubernetes to serverless: How dacadoo saved 78% on cloud costs and automated operations
In this post, we walk you step-by-step through dacadoo’s journey of embracing managed services, highlighting their architectural decisions as we go.

Top Architecture Blog Posts of 2024
Well, it’s been another historic year! We’ve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the Architecture Blog happily participated, we also made every effort to stay true to our channel’s original scope, and your readership this last year has proven that decision was […]

How to build custom nodes workflow with ComfyUI on Amazon EKS
ComfyUI is an open-source node-based workflow solution for Stable Diffusion and increasingly being used by many creators. We previously published a blog and solution about how to deploy ComfyUI on AWS. Typically, ComfyUI users use various custom nodes, which extend the capabilities of ComfyUI, to build their own workflows, often using ComfyUI-Manager to conveniently install and manage their […]

Let’s Architect! Modern data architectures
Data is the fuel for AI; modern data is even more important for generative AI and advanced data analytics, producing more accurate, relevant, and impactful results. Modern data comes in various forms: real-time, unstructured, or user-generated. Each form requires a different solution. AWS’s data journey began with Amazon Simple Storage Service (Amazon S3) in 2006, […]

How CyberArk is streamlining serverless governance by codifying architectural blueprints
This post was co-written with Ran Isenberg, Principal Software Architect at CyberArk and an AWS Serverless Hero. Serverless architectures enable agility and simplified cloud resource management. Organizations embracing serverless architectures build robust, distributed cloud applications. As organizations grow and the number of development teams increases, maintaining architectural consistency, standardization, and governance across projects becomes crucial. […]

Hybrid Cloud Journey using Amazon Outposts and AWS Local Zones
This post was co-written with Amy Flanagan, Vice President of Architecture and leader of the Virtual Architecture Team (VAT) at athenahealth, and Anusha Dharmalingam, Executive Director and Senior Architect at athenahealth. athenahealth has embarked on an ambitious journey to modernize its technology stack by leveraging AWS’s hybrid cloud solutions. This transformation aims to enhance scalability, […]