AWS Architecture Blog
Organizing Software Deployments to Match Failure Conditions
Deploying new software into production will always carry some amount of risk, and failed deployments (e.g., software bugs, misconfigurations, etc.) will occasionally occur. As a service owner, the goal is to try and reduce the number of these incidents and to limit customer impact when they do occur. One method to reduce potential impact is to shape your deployment strategies around the failure conditions of your service. Thus, when a deployment fails, the service owner has more control over the blast radius as well as the scope of the impact. These strategies require an understanding of how the various components of your system interact, how those components can fail and how those failures impact your customers. This blog post discusses some of the deployment strategies that we’ve made on the Route 53 team and how these choices affect the availability of our service.
To begin, I’ll briefly describe some of the deployment procedures and the Route 53 architecture in order to provide some context for the deployment strategies that we have chosen. Hopefully, these examples will reveal strategies that could benefit your own service’s availability. Like many services, Route 53 consists of multiple environments or stages: one for active development, one for staging changes to production and the production stage itself. The natural tension with trying to reduce the number of failed deployments in production is to add more rigidity and processes that slow down the release of new code. At Route 53, we do not enforce a strict release or deployment schedule; individual developers are responsible for verifying their changes in the staging environment and pushing their changes into production. Typically, our deployments proceed in a pipelined fashion. Each step of the pipeline is referred to as a “wave” and consists of some portion of our fleet. A pipeline is a good abstraction as each wave can be thought of as an independent and separate step. After each wave of the pipeline, the change can be verified — this can include automatic, scheduled and manual testing as well as the verification of service metrics. Furthermore, we typically space out the earlier waves of production deployment at least 24 hours apart, in order to allow the changes to “bake.” Letting our software bake refers to rolling out software changes slowly to allow us to validate those changes and verify service metrics with production traffic before pushing the deployment to the next wave. The clear advantage of deploying new code to only a portion of your fleet is that it reduces the impact of a failed deployment to just the portion of the fleet containing the new code. Another benefit of our deployment infrastructure is that it provides us a mechanism to quickly “roll back” a deployment to a previous software version if any problems are detected which, in many cases, enables us to quickly mitigate a failed deployment.
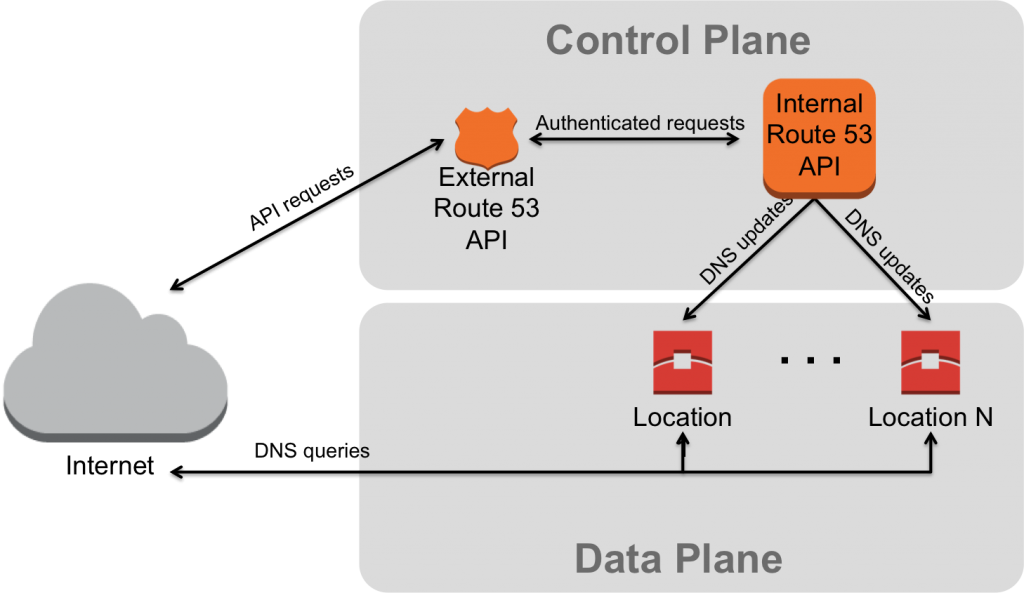
Based on our experiences, we have further organized our deployments to try and match our failure conditions to further reduce impact. First, our deployment strategies are tailored to the part of the system that is the target of our deployment. We commonly refer to two main components of Route 53: the control plane and the data plane (pictured below). The control plane consists primarily of our API and DNS change propagation system. Essentially, this is the part of our system that accepts a customer request to create or delete a DNS record and then the transmission of that update to all of our DNS servers distributed across the world. The data plane consists of our fleet of DNS servers that are responsible for answering DNS queries on behalf of our customers. These servers currently reside in more than 50 locations around the world. Both of these components have their own set of failure conditions and differ in how a failed deployment will impact customers. Further, a failure of one component may not impact the other. For example, an API outage where customers are unable to create new hosted zones or records has no impact on our data plane continuing to answer queries for all records created prior to the outage. Given their distinct set of failure conditions, the control plane and data plane have their own deployment strategies, which are each discussed in more detail below.
Control Plane Deployments
The bulk of the of the control plane actually consists of two APIs. The first is our external API that is reachable from the Internet and is the entry point for customers to create, delete and view their DNS records. This external API performs authentication and authorization checks on customer requests before forwarding them to our internal API. The second, internal API supports a much larger set of operations than just the ones needed by the external API; it also includes operations required to monitor and propagate DNS changes to our DNS servers as well as other operations needed to operate and monitor the service. Failed deployments to the external API typically impact a customer’s ability to view or modify their DNS records. The availability of this API is critical as our customers may rely on the ability to update their DNS records quickly and reliably during an operational event for their own service or site.
Deployments to the external API are fairly straightforward. For increased availability, we host the external API in multiple availability zones. Each wave of deployment consists of the hosts within a single availability zone, and each host in that availability zone is deployed to individually. If any single host deployment fails, the deployment to the entire availability zone is halted automatically. Some host failures may be quickly caught and mitigated by the load balancer for our hosts in that particular availability zone, which is responsible for health checking the hosts. Hosts that fail these load balancer health checks are automatically removed from service by the load balancer. Thus, a failed deployment to just a single host would result in it being removed from service automatically and the deployment halted without any operator intervention. For other types of failed deployments that may not cause the load balancer health checks to fail, restricting waves to a single availability zone allows us to easily flip away from that availability zone as soon as the failure is detected. A similar approach could be applied to services that utilize Route 53 plus ELB in multiple regions and availability zones for their services. ELBs automatically health check their back-end instances and remove unhealthy instances from service. By creating Route 53 alias records marked to evaluate target health (see ELB documentation for how to set this up), if all instances behind an ELB are unhealthy, Route 53 will fail away from this alias and attempt to find an alternate healthy record to serve. This configuration will enable automatic failover at the DNS-level for an unhealthy region or availability zone. To enable manual failover, simply convert the alias resource record set for your ELB to either a weighted alias or associate it with a health check whose health you control. To initiate a failover, simply set the weight to 0 or fail the health check. A weighted alias also allows you the ability to slowly increase the traffic to that ELB, which can be useful for verifying your own software deployments to the back-end instances.
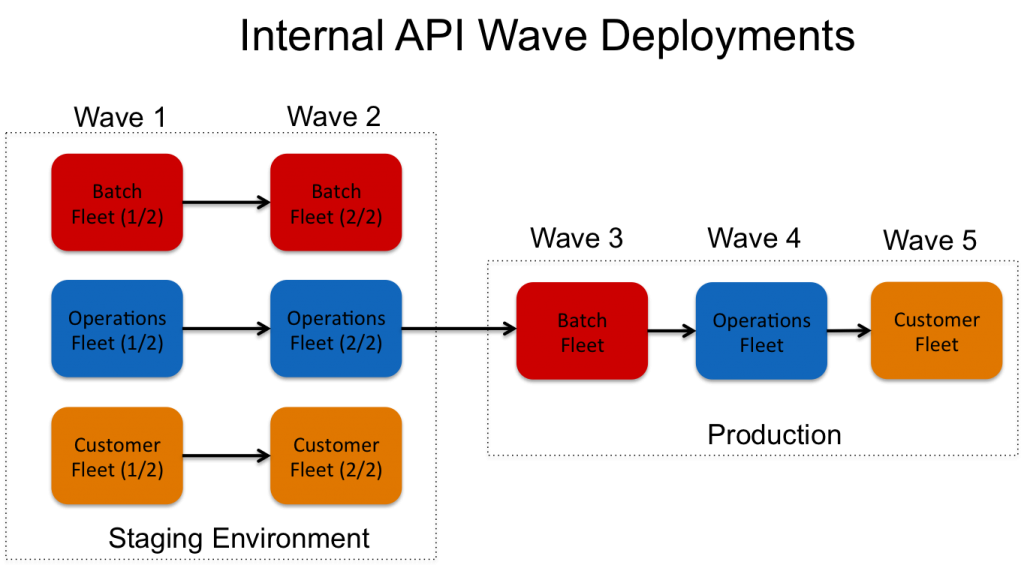
For our internal API, the deployment strategy is more complicated (pictured below). Here, our fleet is partitioned by the type of traffic it handles. We classify traffic into three types: (1) low-priority, long-running operations used to monitor the service (batch fleet), (2) all other operations used to operate and monitor the service (operations fleet) and (3) all customer operations (customer fleet). Deployments to the production internal API are then organized by how critical their traffic is to the service as a whole. For instance, the batch fleet is deployed to first because their operations are not critical to the running of the service and we can tolerate long outages of this fleet. Similarly, we prioritize the operations fleet below that of customer traffic as we would rather continue accepting and processing customer traffic after a failed deployment to the operations fleet. For the internal API, we have also organized our staging waves differently from our production waves. In the staging waves, all three fleets are split across two waves. This is done intentionally to allow us to verify that the code changes work in a split-world where multiple versions of the software are running simultaneously. We have found this to be useful in catching incompatibilities between software versions. Since we never deploy software in production to 100% of our fleet at the same time, our software updates must be designed to be compatible with the previous version. Finally, as with the external API, all wave deployments proceed with a single host at a time. For this API, we also include a deep application health check as part of the deployment. Similar to the load balancer health checks for the external API, if this health check fails, the entire deployment is immediately halted.
Data Plane Deployments
As mentioned earlier, our data plane consists of Route 53’s DNS servers, which are distributed across the world in more than 50 distinct locations (we refer to each location as an ‘edge location’). An important consideration with our deployment strategy is how we stripe our anycast IP space across locations. In summary, each hosted zone is assigned four delegation name servers, each of which belong to a “stripe” (i.e., one quarter of our anycast range). Generally speaking, each edge location announces only a single stripe, so each stripe is therefore announced by roughly 1/4 of our edge locations worldwide. Thus, when a resolver issues a query against each of the four delegation name servers, those queries are directed via BGP to the closest (in a network sense) edge location from each stripe. While the availability and correctness of our API is important, the availability and correctness of our data plane are even more critical. In this case, an outage directly results in an outage for our customers. Furthermore, the impact of serving even a single wrong answer on behalf of a customer is magnified by that answer being cached by both intermediate resolvers and end clients alike. Thus, deployments to our data plane are organized even more carefully to both prevent failed deployments and to reduce potential impact.
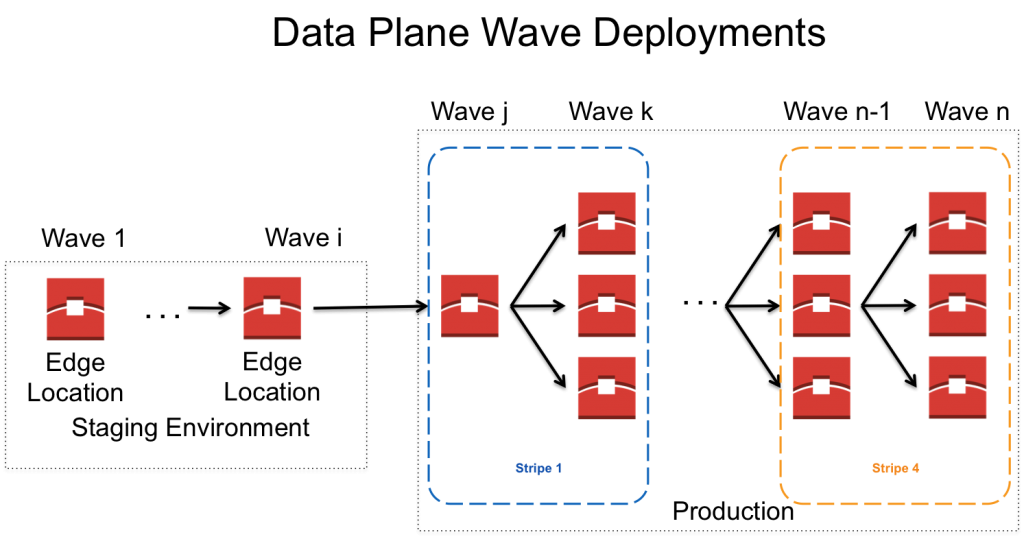
The safest way to deploy and minimize impact would be to deploy to a single edge location at a time. However, with manual deployments that are overseen by a developer, this approach is just not scalable with how frequently we deploy new software to over 50 locations (with more added each year). Thus, most of our production deployment waves consist of multiple locations; the one exception is our first wave that includes just a single location. Furthermore, this location is specifically chosen because it runs our oldest hardware, which provides us a quick notification for any unintended performance degradation. It is important to note that while the caching behavior for resolvers can cause issues if we serve an incorrect answer, they handle other types failures well. When a recursive resolver receives a query for a record that is not cached, it will typically issue queries to at least three of the four delegation name servers in parallel and it will use the first response it receives. Thus, in the event where one of our locations is black holing customer queries (i.e., not replying to DNS queries), the resolver should receive a response from one of the other delegation name servers. In this case, the only impact is to resolvers where the edge location that is not answering would have been the fastest responder. Now, that resolver will effectively be waiting for the response from the second fastest stripe. To take advantage of this resiliency, our other waves are organized such that they include edge locations that are geographically diverse, with the intent that for any single resolver, there will be nearby locations that are not included in the current deployment wave. Furthermore, to guarantee that at most a single nameserver for all customers is affected, waves are actually organized by stripe. Finally, each stripe is spread across multiple waves so that failures impact only a single name server for a portion of our customers. An example of this strategy is depicted below. A few notes: our staging environment consists of a much smaller number of edge locations than production, so single-location waves are possible. Second, each stripe is denoted by color; in this example, we see deployments spread across a blue and orange stripe. You, too, can think about organizing your deployment strategy around your failure conditions. For example, if you have a database schema used by both your production system and a warehousing system, deploy the change to the warehousing system first to ensure you haven’t broken any compatibility. You might catch problems with the warehousing system before it affects customer traffic.
Conclusions
Our team’s experience with operating Route 53 over the last 3+ years have highlighted the importance of reducing the impact from failed deployments. Over the years, we have been able to identify some of the common failure conditions and to organize our software deployments in such a way so that we increase the ease of mitigation while decreasing the potential impact to our customers.
– Nick Trebon