AWS News Blog
Amazon Elastic MapReduce Now Available in Europe

|
 Earlier this year I wrote about Amazon Elastic MapReduce and the ways in which it can be used to process large data sets on a cluster of processors. Since the announcement, our customers have wholeheartedly embraced the service and have been doing some very impressive work with it (more on this in a moment).
Earlier this year I wrote about Amazon Elastic MapReduce and the ways in which it can be used to process large data sets on a cluster of processors. Since the announcement, our customers have wholeheartedly embraced the service and have been doing some very impressive work with it (more on this in a moment).
Today I am pleased to announce Amazon Elastic MapReduce job flows can now be run in our European region. You can launch jobs in Europe by simply choosing the new region from the menu. The jobs will run on EC2 instances in Europe and usage will be billed at those rates.
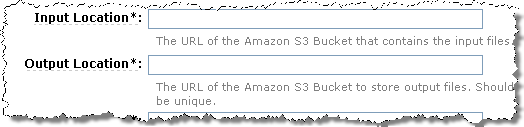 Because the input and output locations for Elastic MapReduce jobs are specified in terms of URLs to S3 buckets, you can process data from US-hosted buckets in Europe, storing the results in Europe or in the US. Since this is an internet data transfer, the usual EC2 and S3 bandwidth charges will apply.
Because the input and output locations for Elastic MapReduce jobs are specified in terms of URLs to S3 buckets, you can process data from US-hosted buckets in Europe, storing the results in Europe or in the US. Since this is an internet data transfer, the usual EC2 and S3 bandwidth charges will apply.
Our customers are doing some interesting things with Elastic MapReduce.
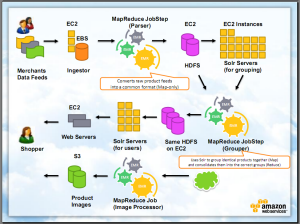 At the recent Hadoop Summit, online shopping site ExtraBux described their multi-stage processing pipeline. The pipeline is fed with data supplied by their merchant partners. This data is preprocessed on some EC2 instances and then stored on a collection of Elastic Block Store volumes. The first MapReduce step processes this data into a common format and stores it in HDFS form for further processing. Additional processing steps transform the data and product images into final form for presentation to online shoppers.
At the recent Hadoop Summit, online shopping site ExtraBux described their multi-stage processing pipeline. The pipeline is fed with data supplied by their merchant partners. This data is preprocessed on some EC2 instances and then stored on a collection of Elastic Block Store volumes. The first MapReduce step processes this data into a common format and stores it in HDFS form for further processing. Additional processing steps transform the data and product images into final form for presentation to online shoppers.
Online dating site eHarmony is also making good use of Elastic MapReduce, processing tens of gigabytes of data representing hundreds of millions of users, each with several hundred attributes to be matched. According to SearchCloudComputing.com, they are doing this work for $1,200 per month, a considerable savings from the $5,000 per month that they estimated it would cost them to do it internally.
— Jeff;
PS – If you have a lot of data that you would like to process on Elastic MapReduce, don’t forget to check out the new AWS Import/Export service. You can send your physical media to us and we’ll take care of loading it into Amazon S3 for you.