AWS News Blog
Announcing Amazon Elastic MapReduce

|
Today we are introducing Amazon Elastic MapReduce , our new Hadoop-based processing service. I’ll spend a few minutes talking about the generic MapReduce concept and then I’ll dive in to the details of this exciting new service.
Over the past 3 or 4 years, scientists, researchers, and commercial developers have recognized and embraced the MapReduce programming model. Originally described in a landmark paper, the MapReduce model is ideal for processing large data sets on a cluster of processors. It is easy to scale up a MapReduce application to jobs of arbitrary size by simply adding more compute power. Here’s a very simple overview of the data flow in a typical MapReduce job:
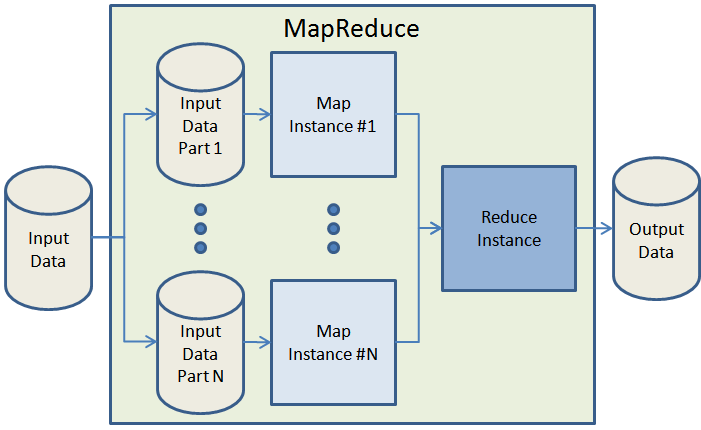
Given that you have enough computing hardware, MapReduce takes care of splitting up the input data into chunks of more or less equal size, spinning up a number of processing instances for the map phase (which must, by definition, be something that can be broken down into independent, parallelizable work units) apportioning the data to each of the mappers, tracking the status of each mapper, routing the map results to the reduce phase, and finally shutting down the mappers and the reducers when the work has been done. It is easy to scale up MapReduce to handle bigger jobs or to produce results in a shorter time by simply running the job on a larger cluster.
Hadoop is an open source implementation of the MapReduce programming model. If you’ve got the hardware, you can follow the directions in the Hadoop Cluster Setup documentation and, with some luck, be up and running before too long.
Developers the world over seem to think that the MapReduce model is easy to understand and easy to work in to their thought process. After a while they tend to report that they begin to think in terms of the new style, and then see more and more applications for it. Once they start to show that the model has a genuine business model (e.g. better results, faster) demand for hardware resources increases rapidly. Like any true viral success, one team shows great results and before too long everyone in the organization wants to do something similar. For example, Yahoo! uses Hadoop on a very large scale. A little over a year ago they reported that they were able to use the power of over 10,000 processor cores to generate a web map to power Yahoo! Search.

This is Rufus, the “first dog” of our AWS Developer Relations team. As you can see, he’s scaled up quite well since his debut on this very blog three years ago. Your problems may start out like the puppy-sized version of Rufus but will quickly grow into the full-scale 95 pound version.
Over the past year or two a number of our customers have told us that they are running large Hadoop jobs on Amazon EC2. There’s some good info on how to do this here and also here. AWS Evangelist Jinesh Varia covered the concept in a blog post last year, and also went into considerable detail in his Cloud Architectures white paper.
Given our belief in the power of the MapReduce programming style and the knowledge that many developers are already running Hadoop jobs of impressive size in our cloud, we wanted to find a way to make this important technology accessible to even more people.

Today we are rolling out Amazon Elastic MapReduce. Using Elastic MapReduce, you can create, run, monitor, and control Hadoop jobs with point-and-click ease. You don’t have to go out and buys scads of hardware. You don’t have to rack it, network it, or administer it. You don’t have to worry about running out of resources or sharing them with other members of your organization. You don’t have to monitor it, tune it, or spend time upgrading the system or application software on it. You can run world-scale jobs anytime you would like, while remaining focused on your results. Note that I said jobs (plural), not job. Subject to the number of EC2 instances you are allowed to run, you can start up any number of MapReduce jobs in parallel. You can always request an additional allocation of EC2 instances here.
Processing in Elastic MapReduce is centered around the concept of a Job Flow. Each Job Flow can contain one or more Steps. Each step inhales a bunch of data from Amazon S3, distributes it to a specified number of EC2 instances running Hadoop (spinning up the instances if necessary), does all of the work, and then writes the results back to S3. Each step must reference application- specific “mapper” and/or “reducer” code (Java JARs or scripting code for use via the Streaming model). We’ve also included the Aggregate Package with built-in support for a number of common operations such as Sum, Min, Max, Histogram, and Count. You can get a lot done before you even start to write code!
We’re providing three distinct access routes to Elastic MapReduce. You have complete control via the Elastic MapReduce API, you can use the Elastic MapReduce command-line tools, or you can go all point-and-click with the Elastic MapReduce tab within the AWS Management Console! Let’s take a look at each one.
The Elastic MapReduce API represents the fundamental, low-level entry point into the system. Action begins with the RunJobFlow function. This call is used to create a Job Flow with one or more steps inside. It accepts an EC2 instance type, an EC2 instance count, a description of each step (input bucket, output bucket, mapper, reducer, and so forth) and returns a Job Flow Id. This one call is equivalent to buying, configuring, and booting up a whole rack of hardware. The call itself returns in a second or two and the job is up and running in a matter of minutes. Once you have a Job Flow Id, you can add additional processing steps (while the job is running!) using AddJobFlowSteps. You can see what’s running with DescribeJobFlows, and you can shut down one or more jobs using TerminateJobFlows.
The Elastic MapReduce client is a command-line tool written in Ruby. The client can invoke each of the functions I’ve already described. You can create, augment, describe, and terminate Job Flows from the command line.
Finally, you can use the new Elastic MapReduce tab of the AWS Management Console to create, augment, describe, and terminate job flows from the comfort of your web browser! Here are a few screen shots to whet your appetite:
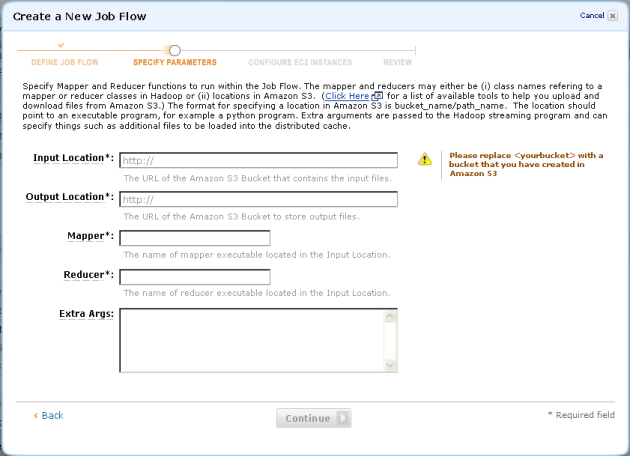
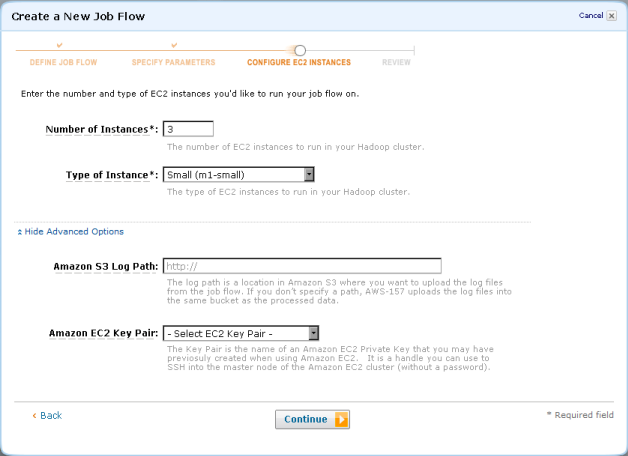
I’m pretty psyched about the fact that we are giving our users access to such a powerful programming model in a form that’s really easy to use. Whether you use the console, the API, or the command-line tools, you’ll be able to focus on the job at hand instead of spending your time wandering through dark alleys in the middle of the night searching for more hardware.
What do you think? Is this cool, or what?
— Jeff;