AWS News Blog
Apache HBase on Amazon EMR – Real-time Access to Your Big Data
All Your Base
AWS has already given you a lot of storage and processing options to choose from, and today we are adding a really important one.
You can now use Apache HBase to store and process extremely large amounts of data (think billions of rows and millions of columns per row) on AWS. HBase offers a number of powerful features including:
- Strictly consistent reads and writes.
- High write throughput.
- Automatic sharding of tables.
- Efficient storage of sparse data.
- Low-latency data access via in-memory operations.
- Direct input and output to Hadoop jobs.
- Integration with Apache Hive for SQL-like queries over HBase tables, joins, and JDBC support.
HBase is formally part of the Apache Hadoop project, and runs within Amazon Elastic MapReduce. You can launch HBase jobs (version 0.92.0) from the command line or the AWS Management Console.
HBase in Action
HBase has been optimized for low-latency lookups and range scans, with efficient updates and deletions of individual records. Here are some of the things that you can do with it:
Reference Data for Hadoop Analytics – Because HBase is integrated into Hadoop and Hive and provides rapid access to stored data, it is a great way to store reference data that will be used by one or more Hadoop jobs on a single cluster or across multiple Hadoop clusters.
Log Ingestion and Batch Analytics – HBase can handle real-time ingestion of log data with ease, thanks to its high write throughput and efficient storage of sparse data. Combining this with Hadoop’s ability to handle sequential reads and scans in a highly optimized fashion, and you have a powerful tool for log analysis.
Storage for High Frequency Counters and Summary Data – HBase supports high update rates (the classic read-modify-write) along with strictly consistent reads and writes. These features make it ideal for storing counters and summary data. Complex aggregations such as max-min, sum, average, and group-by can be run as Hadoop jobs and the results can be piped back into an HBase table.
I should point out that HBase on EMR runs in a single Availability Zone and does not guarantee data durability; data stored in an HBase cluster can be lost if the master node in the cluster fails. Hence, HBase should be used for summarization or secondary data or you should make use of the backup feature described below.
You can do all of this (and a lot more) by running HBase on AWS. You’ll get all sorts of benefits when you do so:
Freedom from Drudgery – You can focus on your business and on your customers. You don’t have to set up, manage, or tune your HBase clusters. Elastic MapReduce will handle provisioning of EC2 instances, security settings, HBase configuration, log collection, health monitoring, and replacement of faulty instances. You can even expand the size of your HBase cluster with a single API call.
Backup and Recovery – You can schedule full and incremental backups of your HBase data to Amazon S3. You can rollback to an old backup on an existing cluster or you can restore a backup to a newly launched cluster.
Seamless AWS Integration – HBase on Elastic MapReduce was designed to work smoothly and seamlessly with other AWS services such as S3, DynamoDB, EC2, and CloudWatch.
Getting Started
You can start HBase from the command line by launching your Elastic MapReduce cluster with the –hbase flag :
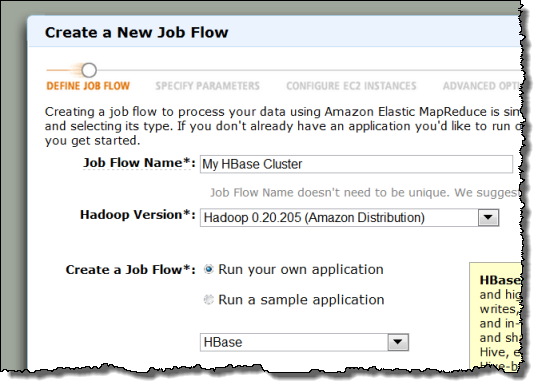
You can also start it from the Create New Cluster page of the AWS Management Console:
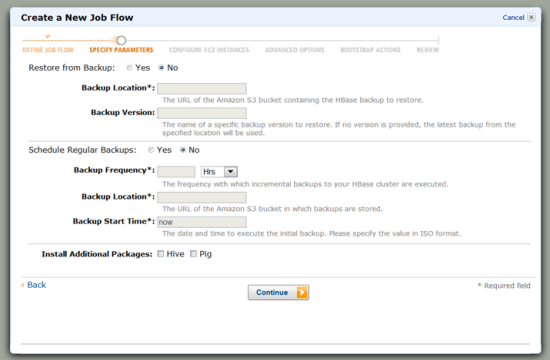
When you create your HBase Job Flow from the console you can restore from an existing backup, and you can also schedule future backups:
Beyond the Basics
Here are a couple of advanced features and options that might be of interest to you:
You can modify your HBase configuration at launch time by using an EMR bootstrap action. For example, you can alter the maximum file size (hbase.hregion.max.filesize) or the maximum size of the memstore (hbase.regionserver.global.memstore.upperLimit).
You can monitor your cluster with the standard CloudWatch metrics that are generated for all Elastic MapReduce job flows. You can also install Ganglia at startup time by invoking a pair of predefined bootstrap actions (install-ganglia and configure-hbase-for-ganglia). We plan to add additional metrics, specific to HBase, over time.
You can run Apache Hive on the same cluster, or you can install it on a separate cluster. Hive will run queries transparently against HBase and Hive tables. We do advise you to proceed with care when running both on the same cluster; HBase is CPU and memory intensive, while most other MapReduce jobs are I/O bound, with fixed memory requirements and sporadic CPU usage.
HBase job flows are always launched with EC2 Termination Protection enabled. You will need to confirm your intent to terminate the job flow.
I hope you enjoy this powerful new feature!
— Jeff;
PS – There is no extra charge to run HBase. You pay the usual rates for Elastic MapReduce and EC2.