AWS News Blog
New Elastic MapReduce Features: Metrics, Updates, VPC, and Cluster Compute Support (Guest Post)

|
Today’s guest blogger is Adam Gray. Adam is a Product Manager on the Elastic MapReduce Team.
— Jeff;
Were always excited when we can bring features to our customers that make it easier for them to derive value from their dataso its been a fun month for the EMR team. Here is a sampling of the things weve been working on.
Free CloudWatch Metrics
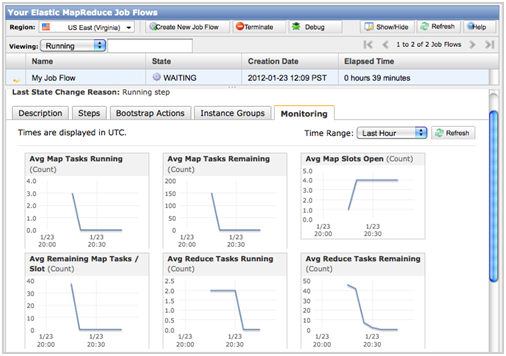
Starting today customers can view graphs of 23 job flow metrics within the EMR Console by selecting the Monitoring tab in the Job Flow Details page. These metrics are pushed CloudWatch every five minutes at no cost to you and include information on:
- Job flow progress including metrics on the number of map and reduce tasks running and remaining in your job flow and the number of bytes read and written to S3 and HDFS.
- Job flow contention including metrics on HDFS utilization, map and reduce slots open, jobs running, and the ratio between map tasks remaining and map slots.
- Job flow health including metrics on whether your job flow is idle, if there are missing data blocks, and if there are any dead nodes.
Please watch this video to see how to view CloudWatch graphs in the EMR Console:
You can also learn more from the Viewing CloudWatch Metrics section of the EMR Developer Guide.
You can view the new metrics in the AWS Management Console:
Further, through the CloudWatch Console, API, or SDK you can set alarms to be notified via SNS if any of these metrics go outside of specified thresholds. For example, you can receive an email notification whenever a job flow is idle for more than 30 minutes, HDFS Utilization goes above 80%, or there are five times as many remaining map tasks as there are map slots, indicating that you may want to expand your cluster size.
Please watch this video to see how to set EMR alarms through the CloudWatch Console:
Hadoop 0.20.205, Pig 0.9.1, and AMI Versioning
EMR now supports running your job flows using Hadoop 0.20.205 and Pig 0.9.1. To simplify the upgrade process, we have also introduced the concept of AMI versions. You can now provide a specific AMI version to use at job flow launch or specify that you would like to use our latest AMI, ensuring that you are always using our most up-to-date features. The following AMI versions are now available:
- Version 2.0.x: Hadoop 0.20.205, Hive 0.7.1, Pig 0.9.1, Debian 6.0.2 (Squeeze)
- Version 1.0.x: Hadoop 0.18.3 and 0.20.2, Hive 0.5 and 0.7.1, Pig 0.3 and 0.6, Debian 5.0 (Lenny)
You can specify an AMI version when launching a job flow in the Ruby CLI using the –ami-version argument (note that you will have to download the latest version of the Ruby CLI):
Please visit the AMI Versioning section of the Elastic MapReduce Developer Guide for more information.
S3DistCp for Efficient Copy between S3 and HDFS
We have also made available S3DistCp, an extension of the open source Apache DistCp tool for distributed data copy, that has been optimized to work with Amazon S3. Using S3DistCp, you can efficiently copy large amounts of data between Amazon S3 and HDFS on your Amazon EMR job flow or copy files between Amazon S3 buckets. During data copy you can also optimize your files for Hadoop processing. This includes modifying compression schemes, concatenating small files, and creating partitions.
For example, you can load Amazon CloudFront logs from S3 into HDFS for processing while simultaneously modifying the compression format from Gzip (the Amazon CloudFront default) to LZO and combining all the logs for a given hour into a single file. As Hadoop jobs are more efficient processing a few, large, LZO-compressed files than processing many, small, Gzip-compressed files, this can improve performance significantly.
Please see Distributed Copy Using S3DistCp in the Amazon Elastic MapReduce documentation for more details and code examples.
cc2.8xlarge Support
Amazon Elastic MapReduce also now supports the new Amazon EC2 Cluster Compute instance, Cluster Compute Eight Extra Large (cc2.8xlarge). Like other Cluster Compute instances, cc2.8xlarge instances are optimized for high performance computing, giving customers very high CPU capabilities and the ability to launch instances within a high bandwidth, low latency, full bisection bandwidth network. cc2.8xlarge instances provide customers with more than 2.5 times the CPU performance of the first Cluster Compute instance (cc1.4xlarge) instance, more memory, and more local storage at a very compelling cost. Please visit the Instance Types section of the Amazon Elastic MapReduce detail page for more details.
In addition, we are pleased to announce an 18% reduction in Amazon Elastic MapReduce pricing for cc1.4xlarge instances, dropping the total per hour cost to $1.57. Please visit the Amazon Elastic MapReduce Pricing Page for more details.
VPC Support
Finally, we are excited to announce support for running job flows in an Amazon Virtual Private Cloud (Amazon VPC), making it easier for customers to:
- Process sensitive data – Launching a job flow on Amazon VPC is similar to launching the job flow on a private network and provides additional tools, such as routing tables and Network ACLs, for defining who has access to the network. If you are processing sensitive data in your job flow, you may find these additional access control tools useful.
- Access resources on an internal network – If your data is located on a private network, it may be impractical or undesirable to regularly upload that data into AWS for import into Amazon Elastic MapReduce, either because of the volume of data or because of its sensitive nature. Now you can launch your job flow on an Amazon VPC and connect to your data center directly through a VPN connection.
You can launch Amazon Elastic MapReduce job flows into your VPC through the Ruby CLI by using the –subnet argument and specifying the subnet address (note that you will have to download the latest version of the Ruby CLI):
Please visit the Running Job Flows on an Amazon VPC section in the Elastic MapReduce Developer Guide for more information.
— Adam Gray, Product Manager, Amazon Elastic MapReduce.