AWS News Blog
Store and Process Large Sequential Data Sets with EC2 Cluster Instances
To date, we haven’t been very vocal about the performance that is possible when you combine the EC2 Cluster Instances and EBS. I’d like to change that today!
The EC2 Cluster Instance types (CC2, CR1, CG1, HI1, and HS1) support high-performance (10 gigabit) networking between instances and Elastic Block Storage volumes (EBS). Instances of this type make ideal hosts for high-performance relational and NoSQL databases. They are also great for processing workloads that require high throughput, sequential access to large amounts of data.
You can use EBS Provisioned IOPS volumes to create storage arrays that store up to tens of terabytes and provide up to 48,000 16 kilobyte IOPS when accessed from instances of the types listed above. This is equivalent to 768 megabytes per second of data transfer. You can create storage arrays that span multiple EBS volumes by using mdadm. You can use other parallel I/O techniques as well, as is most appropriate for your application and your database.
The CloudWatch graph below shows twelve EBS volumes in action on a CC2 instance, each provisioned for 4,000 IOPS and delivering a consistent 64 megabytes per second per volume for the duration of the test:
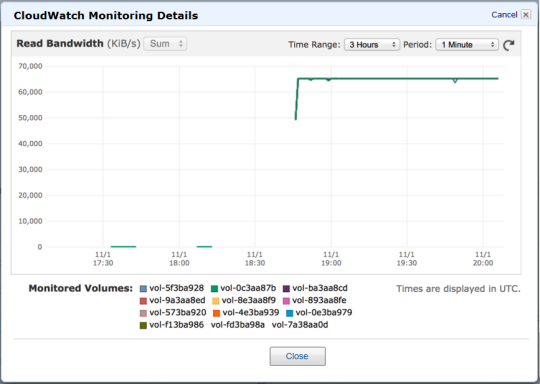
In order to achieve this throughput, the volumes were pre-warmed and optimized for queue depth as described in our EBS Volume Performance document.
Each AWS account has a limit of 10,000 Provisioned IOPS and 20 terabytes of EBS storage. If you need more than this, fill out the Request to Increase the EBS Volume Limit form.
— Jeff;