AWS Big Data Blog
Define error handling for Amazon Redshift Spectrum data
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift Spectrum allows you to query open format data directly from the Amazon Simple Storage Service (Amazon S3) data lake without having to load the data into Amazon Redshift tables. With Redshift Spectrum, you can query open file formats such as Apache Parquet, ORC, JSON, Avro, and CSV. This feature of Amazon Redshift enables a modern data architecture that allows you to query all your data to obtain more complete insights.
Amazon Redshift has a standard way of handling data errors in Redshift Spectrum. Data file fields containing any special character are set to null. Character fields longer than the defined table column length get truncated by Redshift Spectrum, whereas numeric fields display the maximum number that can fit in the column. With this newly added user-defined data error handling feature in Amazon Redshift Spectrum, you can now customize data validation and error handling.
This feature provides you with specific methods for handling each of the scenarios for invalid characters, surplus characters, and numeric overflow while processing data using Redshift Spectrum. Also, the errors are captured and visible in the newly created dictionary view SVL_SPECTRUM_SCAN_ERROR. You can even cancel the query when a defined threshold of errors has been reached.
Prerequisites
To demonstrate Redshift Spectrum user-defined data handling, we build an external table over a data file with soccer league information and use that to show different data errors and how the new feature offers different options in dealing with those data errors. We need the following prerequisites:
- An AWS account
- An S3 bucket
- An AWS Glue Data Catalog database
- An Amazon Redshift cluster with an AWS Identity and Access Management (IAM) role that can read from the S3 bucket
- A data file for the demonstration (for this post, our data file contains soccer clubs, their leagues, and their rankings)
- A SQL script to create an external schema and external table
- A SQL script for the needed DDL for user-defined data handling tests
Solution overview
We use the data file for soccer leagues to define an external table to demonstrate different data errors and the different handling techniques offered by the new feature to deal with those errors. The following screenshot shows an example of the data file.
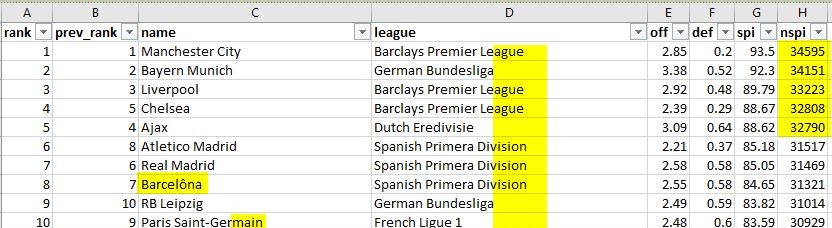
Note the following in the example:
- The club name can typically be longer than 15 characters
- The league name can be typically be longer than 20 characters
- The club name Barcelôna includes an invalid character
- The column
nspiincludes values that are bigger than SMALLINT range
Then we create an external table (see the following code) to demonstrate the new user-defined handling:
- We define the
club_nameandleague_nameshorter than they should to demonstrate handling of surplus characters - We define the column
league_nspias SMALLINT to demonstrate handling of numeric overflow - We use the new table property
data_cleansing_enabledto enable custom data handling
Invalid character data handling
With the introduction of the new table and column property invalid_char_handling, you can now choose how you deal with invalid characters in your data. The supported values are as follows:
- DISABLED – Feature is disabled (no handling).
- SET_TO_NULL – Replaces the value with
null. - DROP_ROW – Drops the whole row.
- FAIL – Fails the query when an invalid UTF-8 value is detected.
- REPLACE – Replaces the invalid character with a replacement. With this option, you can use the newly introduced table property
replacement_char.
The table property can work over the whole table or just a column level. Additionally, you can define the table property during create time or later by altering the table.
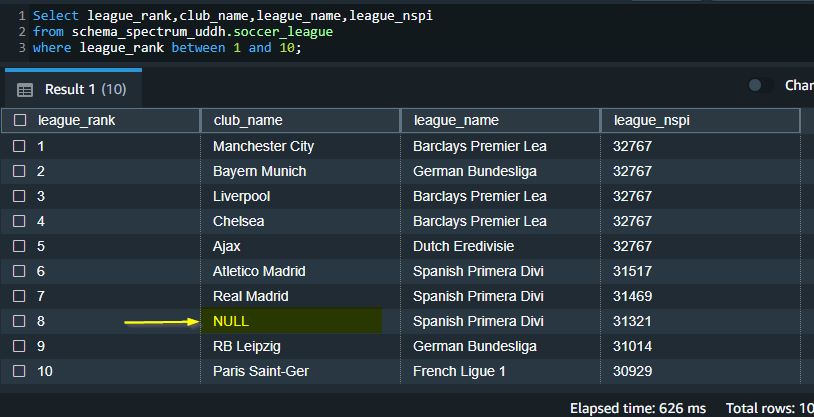
When you disable user-defined handling, Redshift Spectrum by default sets the value to null (similar to SET_TO_NULL):
When you change the setting of the handling to DROP_ROW, Redshift Spectrum simply drops the row that has an invalid character:

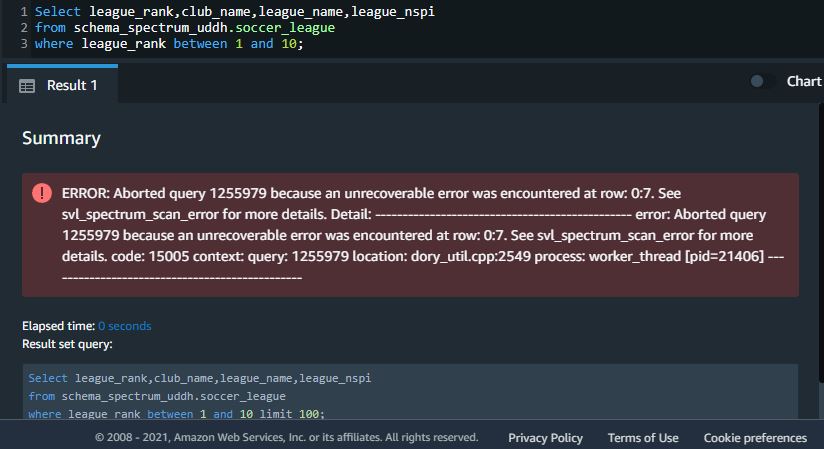
When you change the setting of the handling to FAIL, Redshift Spectrum fails and returns an error:
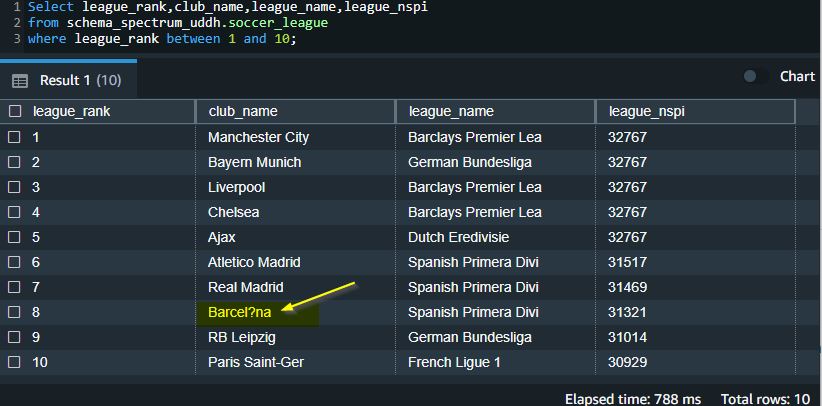
When you change the setting of the handling to REPLACE and choose a replacement character, Redshift Spectrum replaces the invalid character with the chosen replacement character:
Surplus character data handling
As mentioned earlier, we defined the columns club_name and league_name shorter than the actual contents of the corresponding fields in the data file.
With the introduction of the new table property surplus_char_handling, you can choose from multiple options:
- DISABLED – Feature is disabled (no handling)
- TRUNCATE – Truncates the value to the column size
- SET_TO_NULL – Replaces the value with
null - DROP_ROW – Drops the whole row
- FAIL – Fails the query when a value is too large for the column
When you disable the user-defined handling, Redshift Spectrum defaults to truncating the surplus characters (similar to TRUNCATE):
When you change the setting of the handling to SET_TO_NULL, Redshift Spectrum simply sets to NULL the column value of any field that is longer than the defined length:

When you change the setting of the handling to DROP_ROW, Redshift Spectrum drops the row of any field that is longer than the defined length:

When you change the setting of the handling to FAIL, Redshift Spectrum fails and returns an error:
We need to disable the user-defined data handling for this data error before demonstrating the next type of error:
Numeric overflow data handling
For this demonstration, we defined league_nspi intentionally SMALLINT (with a range to hold from -32,768 to +32,767) to show the available options for data handling.
With the introduction of the new table property numeric_overflow_handling, you can choose from multiple options:
- DISABLED – Feature is disabled (no handling)
- SET_TO_NULL – Replaces the value with
null - DROP_ROW – Replaces each value in the row with
NULL - FAIL – Fails the query when a value is too large for the column
When we look at the source data, we can observe that the top five countries have more points than the SMALLINT field can handle.
When you disable the user-defined handling, Redshift Spectrum defaults to the maximum number the numeric data type can handle, for our case SMALLINT can handle up to 32767:

When you choose SET_TO_NULL, Redshift Spectrum sets to null the column with numeric overflow:
When you choose DROP_ROW, Redshift Spectrum drops the row containing the column with numeric overflow:
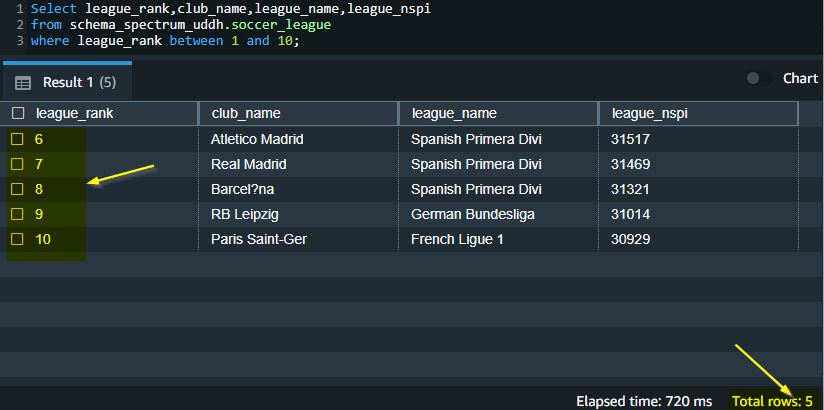
When you choose FAIL, Redshift Spectrum fails and returns an error:
We need to disable the user-defined data handling for this data error before demonstrating the next type of error:
Stop queries at MAXERROR threshold
You can also choose to stop the query if it reaches a certain threshold in errors by using the newly introduced parameter spectrum_query_maxerror:
The following screenshot shows that the query ran successfully.
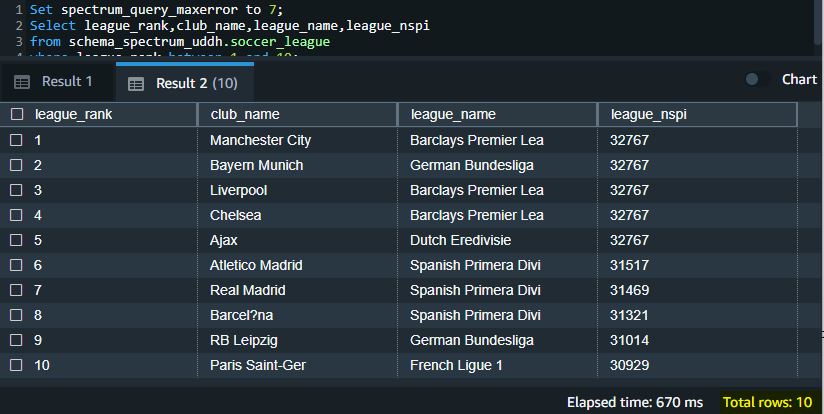
However, if you decrease this threshold to a lower number, the query fails because it reached the preset threshold:

Error logging
With the introduction of the new user-defined data handling feature, we also introduced the new view svl_spectrum_scan_error, which allows you to view a useful sample set of the logs of errors. The table contains the query, file, row, column, error code, handling action that was applied, as well as the original value and the modified (resulting) value. See the following code:

Clean up
To avoid incurring future charges, complete the following steps:
- Delete the Amazon Redshift cluster created for this demonstration. If you were using an existing cluster, drop the created external table and external schema.
- Delete the S3 bucket.
- Delete the AWS Glue Data Catalog database.
Conclusion
In this post, we demonstrated Redshift Spectrum’s newly added feature of user-defined data error handling and showed how this feature provides the flexibility to take a user-defined approach to deal with data exceptions in processing external files. We also demonstrated how the logging enhancements provide transparency on the errors encountered in external data processing without needing to write additional custom code.
We look forward to hearing from you about your experience. If you have questions or suggestions, please leave a comment.
About the Authors
 Ahmed Shehata is a Data Warehouse Specialist Solutions Architect with Amazon Web Services, based out of Toronto.
Ahmed Shehata is a Data Warehouse Specialist Solutions Architect with Amazon Web Services, based out of Toronto.
 Milind Oke is a Data Warehouse Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift. He is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
Milind Oke is a Data Warehouse Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift. He is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.