AWS Big Data Blog
New features from Apache Hudi 0.7.0 and 0.8.0 available on Amazon EMR
Apache Hudi is an open-source transactional data lake framework that greatly simplifies incremental data processing and data pipeline development by providing record-level insert, update, and delete capabilities. This record-level capability is helpful if you’re building your data lakes on Amazon Simple Storage Service (Amazon S3) or Hadoop Distributed File System (HDFS). You can use it to comply with data privacy regulations and simplify data ingestion pipelines that deal with late-arriving or updated records from streaming data sources, or to ingest data using change data capture (CDC) from transactional systems. Apache Hudi is integrated with open-source big data analytics frameworks like Apache Spark, Apache Hive, Presto, and Trino. It allows you to maintain data in Amazon S3 or HDFS in open formats like Apache Parquet and Apache Avro.
Starting with release version 5.28.0, Amazon EMR installs the Hudi component by default when you install Spark, Hive, Presto, or Trino. Since the inclusion of Apache Hudi within Amazon EMR, there has been several improvements and bug fixes that have been added to Apache Hudi. Apache Hudi graduated as a top-level Apache project on June 2020.
In this post, we provide a summary of some of the key new features and capabilities included since Apache Hudi release versions 0.7.0 and 0.8.0. These new features and capabilities of Hudi are available since Amazon EMR releases 5.33.0 and 6.3.0:
- Clustering
- Metadata-based file listing
- Amazon CloudWatch integration
- Optimistic Concurrency Control
- Amazon EMR configuration support and improvements
- Apache Flink integration
- Kafka commit callbacks
- Other improvements
Clustering
We see more use cases that need high throughput ingestion to data lakes. However, faster data ingestion often leads to smaller data file sizes that often adversely affects query performance, because a large number of small files increases the costly I/O operations required to return results. Another concern that we see is that the organization of data during ingestion is different from the organization that would be most efficient when querying the data. For example, it’s convenient to ingest ecommerce orders by OrderDate as they come in, but when queried, it’s better if orders for a single customer are stored together.
Apache Hudi version 0.7.0 introduces a new feature that allows you to cluster the Hudi tables. Clustering in Hudi is a framework that provides a pluggable strategy to change and reorganize the data layout while also optimizing the file sizes. With clustering, you can now optimize query performance without having to trade-off data ingest throughput.
You can use clustering to rewrite the data using different methods as per the different use case requirements:
- Improve query performance with data locality – This changes the data layout on disk by sorting the data on one or many user-specified columns. With this approach, we can improve query performance by using the Parquet file format’s ability to perform predicate push-down and skip the unwanted files and Parquet row groups. This strategy can also control the file size to avoid small files.
- Improve data freshness – This requirement assumes that the data locality is not important or taken care of already at the time of ingestion. It’s ideal for use cases where fresh data is important, where data is ingested using several small files and stitched or merged later using the clustering framework.
You can run the clustering table service asynchronously or synchronously. It also introduces the new action type REPLACE, which identifies the clustering action in the Hudi metadata timeline.
In the following example, we create two Copy on Write (CoW) Hudi tables: amazon_reviews and amazon_reviews_clustered using Amazon EMR release version 6.3.0.
We use spark-shell to create the Hudi tables. Start the Spark shell by running the following on the Amazon EMR primary node:
We then create the Hudi table amazon_reviews using the BULK_INSERT operation and without clustering enabled:
We then create the Hudi table amazon_reviews_clustered using BULK_INSERT operation and inline clustering enabled and sorted by columns star_rating and total_votes:
Let’s query these two tables and validate performance difference. To validate the performance, we will use Spark SQL CLI – a convenient tool to run the Hive metastore service in local mode and execute queries input from the command line. To start the Spark SQL CLI, we execute the following command:
We restart the Spark SQL CLI (spark-sql) session between each run in order to avoid caching or warm executors, which may impact query performance.
Let’s run the query against the non-clustered Hudi table by running the following in the spark-sql interface:
Let’s also run the same query on our clustered table from the spark-sql interface:
Let’s compare the underlying file scan performance for the two different Hudi tables. The following screenshot is the output from the Spark UI, which shows the changes in the files scanned for the same number of output rows. First we see the files scanned for the unclustered Hudi table.
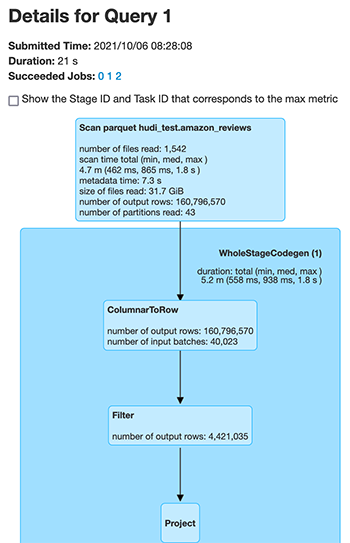
Next, we see the files scanned for the clustered Hudi table.
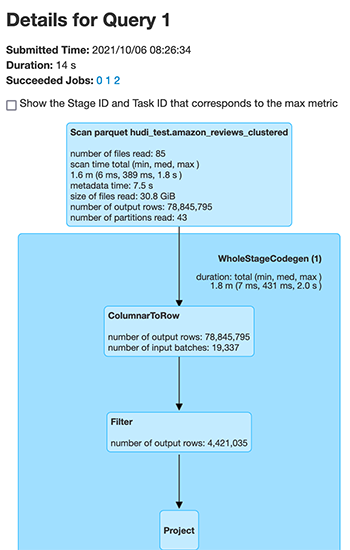
The number of files scanned by Spark dropped from 1,542 files for the unclustered Hudi dataset to 85 files for the clustered Hudi dataset for the exact same data. Also, the number of records scanned reduced from 160,796,570 to 78,845,795.
We compared the performance of the preceding query for the amazon_reviews (non-clustered) and amazon_reviews_clustered (clustered) Hudi dataset, across Spark SQL, Hive, and PrestoDB. The cluster configuration used was 1 leader (m5.4xlarge) and 2 cores (m5.4xlarge).
The following chart provides the query performance comparison using different engines for the Hudi table, which are unclustered, and for the Hudi table, which is clustered.

We found that with clustering enabled for the Hudi table, the query performance increased for all three query engines, ranging from 28% to 63%. The following table provides the details for the query performance for the Hudi table, both with clustering enabled and disabled.
| Query Engine | Non-clustered Table | Clustered Table | Query Runtime Improvement |
| Time (in seconds) | Time (in seconds) | ||
| Spark SQL | 21.6 | 15.4 | 28.7 % |
| Hive | 96.3 | 47 | 51.3 % |
| PrestoDB | 11.7 | 4.3 | 63.25 % |
Metadata-based file listing
Hudi write operations like compaction, cleaning, and global index, as well as queries, perform a file system listing to get the current view of the partitions and files in the dataset. For small datasets, this shouldn’t impact the performance drastically. However, when working with large data, this listing operation can impact the performance negatively when reading the files. For example, with HDFS as the underlying data store, the list operation for a large number of files or partitions can overwhelm HDFS NameNode and affect the stability of job. In cases where Amazon S3 is used as the underlying data store, O(N) calls for N partitions with a large number of files is time-consuming and can also result in throttling errors.
With Apache Hudi version 0.7.0, you can change this behavior by enabling metadata-based listing for Hudi tables. This partitions and files list is stored in an internal metadata table, which is implemented using a Hudi Merge on Read (MoR) table. This metadata table can take all the advantages of the Hudi MoR table, which includes the capability of low-latency updates, and the ability to atomically commit metadata updates and easily roll back if write fails. It also makes it easy to keep metadata in sync with the Hudi table because both use a timeline for traceability. This index of the file list is stored using HFiles for base and log file format for delta updates. The HFile format allows point-lookups of specific records based on record key. The goal is to reduce O(N) list calls for N partitions to O(1) get call to read the metadata.
We compared query performance for a Hudi dataset with metadata listing enabled vs. not enabled. For this example, we used a larger dataset of 3 TB with Amazon EMR release version 6.3.0. We used the following code snippet to create the metadata enabled and not enabled dataset by setting the HoodieMetadataConfig.METADATA_ENABLE_PROP (hoodie.metadata.enable) config:
On the query engine side, we can enable it via the following methods:
- Spark data source:
- Spark SQL CLI:
- Hive:
- PrestoDB:
We used the following query to compare query performance via Hive and PrestoDB:
The following chart provides the query performance comparison.

We found that with metadata listing, query execution runtime decreased by around 25% for the Hive engine, and by around 32% for PrestoDB. The following table provides the details of query execution runtime with and without metadata listing.
| Query Engine | Metadata Disabled | Metadata Enabled | Query Runtime Improvement |
| Time (in seconds) | Time (in seconds) | ||
| Hive | 415.28533 | 310.02367 | 25.35% |
| Presto | 72 | 48.6 | 32.50% |
Metadata listing considerations
With Hudi 0.7.0 and 0.8.0, you may not observe noticeable improvements for queries via Spark SQL (with metadata listing), because Hudi relies on Spark’s InMemoryFileIndex to do the actual file listing and can’t use the metadata. You may observe improvements because HoodieROPathFilter uses the metadata for its filtering. However, with Hudi release 0.9.0, we’re introducing a custom FileIndex implementation for Hudi to use metadata for file listing instead of relying on Spark. Therefore, from 0.9.0, you will observe noticeable performance improvements for Spark SQL queries.
Amazon CloudWatch integration
Apache Hudi provides MetricsReporter implementations like JmxMetricsReporter, MetricsGraphiteReporter, and DatadogMetricsReporter, which you can use to publish metrics to user-specified sinks. Amazon EMR, with its release 6.4.0 having Hudi 0.8.0, has introduced CloudWatchMetricsReporter, which you can use to publish these metrics to Amazon CloudWatch. It helps publish Hudi writer metrics like commit duration, rollback duration, file-level metrics (number of files added or deleted per commit), record-level metrics (records inserted or updated per commit) and partition-level metrics (partitions inserted or updated per commit). This is useful in debugging Hudi jobs, as well as making decisions around cluster scaling.
You can enable the CloudWatch metric via the following configurations:
The following table summarizes additional configurations that you can change if needed.
| Configuration | Description | Value |
| hoodie.metrics.cloudwatch.report.period.seconds | Frequency (in seconds) at which to report metrics to CloudWatch | Default value is 60 seconds, which is fine for the default 1-minute resolution offered by CloudWatch |
| hoodie.metrics.cloudwatch.metric.prefix | Prefix to be added to each metric name | Default value is empty (no prefix) |
| hoodie.metrics.cloudwatch.namespace | CloudWatch namespace under which metrics are published | Default value is Hudi |
| hoodie.metrics.cloudwatch.maxDatumsPerRequest | Maximum number of datums to be included in one request to CloudWatch | Default value is 20, which is same as the CloudWatch default |
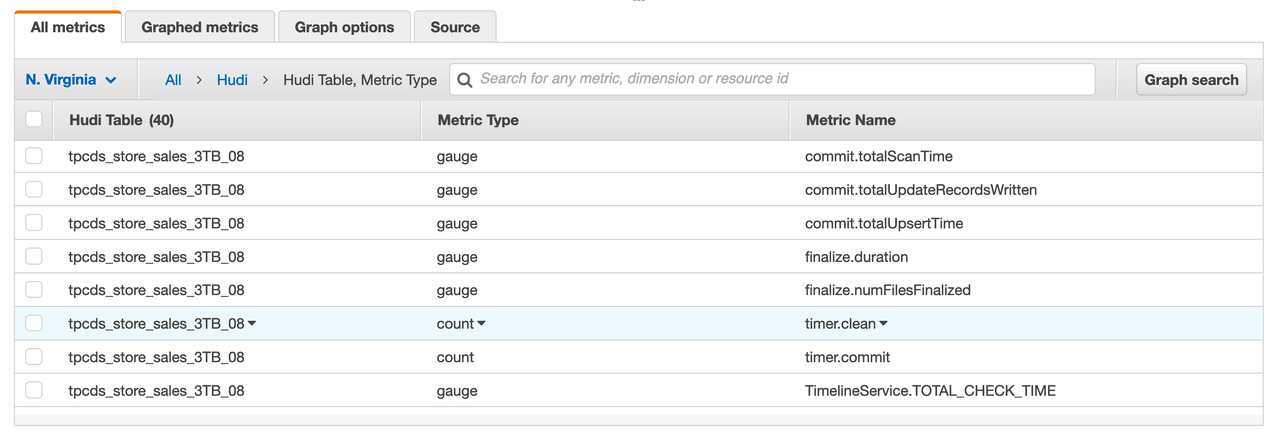
The following screenshot shows some of the metrics published for a particular Hudi table, including the type of metric and its name. These are dropwizard metrics; gauge represents the exact value at a point in time, and counter represents a simple incrementing or decrementing integer.
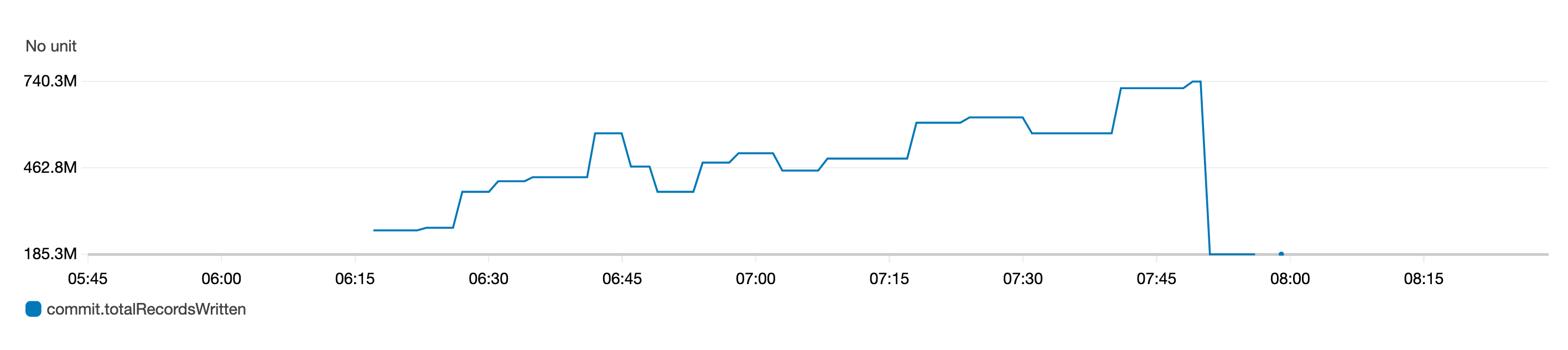
The following graph of the gauge metric represents the total records written to a table over time.
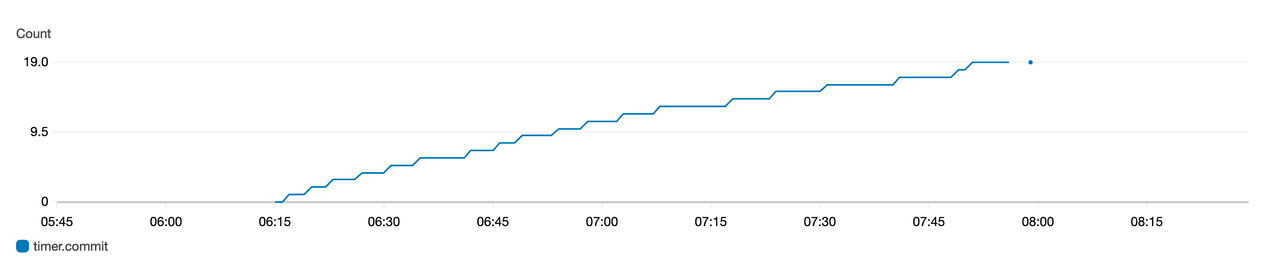
The following graph of the counter metric represents the number of commits increasing over time.
Optimistic Concurrency Control
A major feature that has been introduced with Hudi 0.8.0, and available since Amazon EMR release 6.4.0, is Optimistic Concurrency Control (OCC) to enable multiple writers to concurrently ingest data into the same Hudi table. This is file-level OCC, which means that for any two commits (or writers) happening to the same table at the same time, both are allowed to succeed if they don’t have writes to overlapping files. The feature requires acquiring locks, for which you can use either Zookeeper or HiveMetastore. For more information about the guarantees provided, see Concurrency Control.
Amazon EMR clusters have Zookeeper installed, which you can use as a lock provider to perform concurrent writes from the same cluster. To make it easier to use, Amazon EMR preconfigures the lock provider in the newly introduced /etc/hudi/conf/hudi-defaults.conf file (see the next section) via the following properties:
Although the lock provider is preconfigured, enabling of OCC still needs to be handled by the users either via Hudi job options or at cluster level via the Amazon EMR Configurations API:
Amazon EMR configuration support and improvements
Amazon EMR release 6.4.0 has introduced the ability to configure and reconfigure Hudi via the configurations feature. Hudi configurations that are needed across jobs and tables can now be configured at cluster level via the hudi-defaults classification or /etc/hudi/conf/hudi-defaults.conf file, similar to other applications like Spark and Hive. The following code is an example of the hudi-defaults classification to enable metadata-based listing and CloudWatch metrics:
Amazon EMR automatically configures suitable defaults for a few configs, to improve the user experience by removing the need for customers having to pass them:
- HIVE_URL_OPT_KEY is configured to the cluster’s Hive server URL and no longer needs to be specified. This is particularly useful when running a job in Spark cluster mode, where users previously had to determine and themselves specify the Amazon EMR primary IP.
- HBase specific configurations, which are useful for using HBase index with Hudi.
- Zookeeper lock provider specific configuration, as discussed under concurrency control, which makes it easier to use OCC.
Additional changes have been introduced to reduce the number of configurations that users need to pass, and to infer automatically where possible:
- The partitionBy API can now be used to specify partition column.
- When enabling Hive Sync, it’s no longer mandatory to pass HIVE_TABLE_OPT_KEY, HIVE_PARTITION_FIELDS_OPT_KEY, or HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY. These configs can be inferred from the Hudi table name and partition fields itself.
- KEYGENERATOR_CLASS_OPT_KEY is not mandatory to pass if you’re using
SimpleKeyGeneratororComplexKeyGenerator, and can be inferred depending on whether there are single or multiple record key columns.
Apache Flink integration
Apache Hudi started off with a very tight integration with Apache Spark. With release version 0.7.0, we now have integrations available to ingest data using Apache Flink. It required decoupling Spark from the internal table format, writers, and table services code in a way that can be used by other evolving engines in the industry like Flink.
Hudi 0.7.0 provides initial Flink support via HooodieFlinkStreamer, which you can use to write CoW tables by streaming data from a Kafka topic using Apache Flink. For example, you can use the following Flink command to start reading the topic ExampleTopic from the Kafka brokers broker-1, broker-2, and broker-3 running on port 9092:
With Hudi 0.8.0, there have been major improvements in Flink integration performance and scalability, as well as the introduction of new features like SQL connector for both source and sink, writer for MoR, batch reader for CoW and MoR, streaming reader for MoR, and state-backed indexing with bootstrap support. For more information about Flink integration design, see Apache Hudi meets Apache Flink. To get started with Flink SQL, see Flink Guide.
Kafka commit callbacks
The previous version (0.6.0) of Apache Hudi introduced write commit callback functionality. With this functionality, Hudi can send a callback message every time a successful commit arrives to the Hudi dataset. The write commit callback supported HTTP method in the previous release. With Apache Hudi release version 0.7.0, Hudi now supports write commit callback for Kafka as well. Using Kafka for sending the callback messages for every successful commit can now enable you to build asynchronous data pipelines or business processing logic every time the Hudi dataset sees a new commit. You can now build incremental ETL pipelines for processing new events that arrive in the Hudi data lake.
The implementation of Kafka commit callback uses HoodieWriteCommitKafkaCallback as the hoodie.write.commit.callback.class. Besides setting the commit callback class, you can also set up additional parameters for the Kafka bootstrap servers and the topic configurations.
The following is a code snippet where commit callback messages are published to the Kafka topic ExampleTopic hosted on the Kafka brokers b-1.demo-hudi.xxxxxx.xxx.kafka.us-east-1.amazonaws.com, b-2.demo-hudi.xxxxxx.xxx.kafka.us-east-1.amazonaws.com, and b-3.demo-hudi.xxxxxx.xxx.kafka.us-east-1.amazonaws.com when writing to a Hudi dataset:
The following is how the messages appear in your Kafka topic:
A downstream pipeline can now easily query these events from Kafka and process the incremental data into derived Hudi tables.
Other improvements
Besides the aforementioned improvements, there have been some additional changes worth mentioning. On the writer side, there are the following improvements:
- Support for Spark 3 – Support for writing and querying the data using Apache Spark 3 is now available with Apache Hudi 0.7.0 onwards. This works with Scala 2.12 bundle for
hudi-spark-bundle. - Insert overwrite and insert overwrite table write operations – Apache Hudi 0.7.0 introduces two new operations,
insert_overwriteandinsert_overwrite_table, to support batch ETL jobs where an entire table or partition is overwritten during each execution. You can use these operations instead of theupsertoperation, and it’s must cheaper to run. - Delete partitions – The new API is now available since 0.7.0 to delete an entire partition. This helps avoid the use of record-level deletes.
- Java writer support – Hudi 0.7.0 introduced Java-based writing support via the
HoodieJavaWriteClientclass.
Similarly, on the query integration side, there have been the following improvements:
- Structured streaming reads – Hudi 0.8.0 introduced a Spark structured streaming source implementation via the
HoodieStreamSourceclass. You can use it to support streaming reads from Hudi tables. - Incremental query on MoR – Since Hudi 0.7.0, we now have incremental query support for MoR tables, which you can use to incrementally pull data by downstream applications.
Conclusion
The new features introduced in Apachi Hudi enable you to build decoupled solutions by using features like Kafka commit callback and Flink integration with Apache Hudi with Amazon EMR. You can also improve your overall performance of the Hudi data lake by using the capabilities of clustering and metadata tables.
About the Authors
 Udit Mehrotra is a software development engineer at Amazon Web Services and an Apache Hudi PMC member/committer. He works on cutting-edge features of Amazon EMR and is also involved in open-source projects such as Apache Hudi, Apache Spark, Apache Hadoop, and Apache Hive. In his spare time, he likes to play guitar, travel, binge watch, and hang out with friends.
Udit Mehrotra is a software development engineer at Amazon Web Services and an Apache Hudi PMC member/committer. He works on cutting-edge features of Amazon EMR and is also involved in open-source projects such as Apache Hudi, Apache Spark, Apache Hadoop, and Apache Hive. In his spare time, he likes to play guitar, travel, binge watch, and hang out with friends.
 Gagan Brahmi is a Specialist Solutions Architect focused on Big Data & Analytics at Amazon Web Services. Gagan has over 16 years of experience in information technology. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Gagan Brahmi is a Specialist Solutions Architect focused on Big Data & Analytics at Amazon Web Services. Gagan has over 16 years of experience in information technology. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.