AWS Big Data Blog
Run queries 3x faster with up to 70% cost savings on the latest Amazon Athena engine
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
In November 2020, Athena announced the General Availability of the V2 version of its core engine in addition to performance enhancements and new feature capabilities. Today, V2 is the default engine version for every Athena workgroup and it includes additional enhancements made since its first release. Engine enhancements are released frequently and are automatically available to you without the need for manual intervention.
In this post, we discuss the performance benchmarks and performance enhancements of Athena’s latest engine.
We performed benchmark testing on our latest engine using TPC-DS benchmark queries at 3 TB scale and observed that query performance improved by 3x and cost decreased by 70% as a result of reduced scanned data size when compared to our earlier engine.
Performance and cost comparison on TPC-DS benchmarks
We used the industry-standard TPC-DS 3 TB to represent different customer use cases. These benchmark tests have a range of accuracy within +/- 10% and are representative of workloads with 10 times the stated benchmark size. This means a 3 TB benchmark dataset accurately represents customer workloads on 30–50 TB datasets.
In our testing, the dataset was stored in Amazon S3 in non-compressed Parquet format with no additional optimizations and the AWS Glue Data Catalog was used to store metadata for databases and tables. Fact tables were partitioned on the date column used for join operations and each fact table consisted of 2,000 partitions. We selected 71 of the 99 queries from the TPC-DS benchmark that best illustrated the differences between engines V1 and V2. We ran the queries with a concurrency of 3. This means up to 3 queries were in a running state at any given time and the next query was submitted as soon as one of the 3 running queries completed.
The following graph illustrates the total runtime of queries on engines V1 and V2 and shows runtime was 3x faster on engine V2.
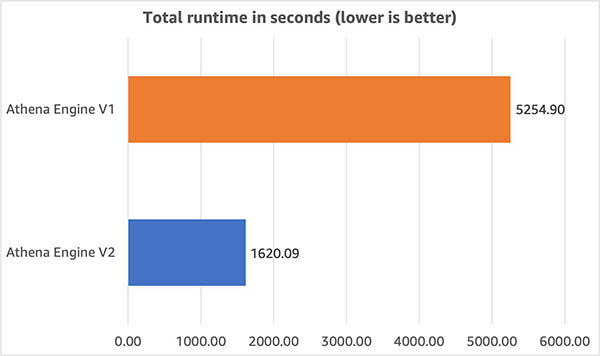
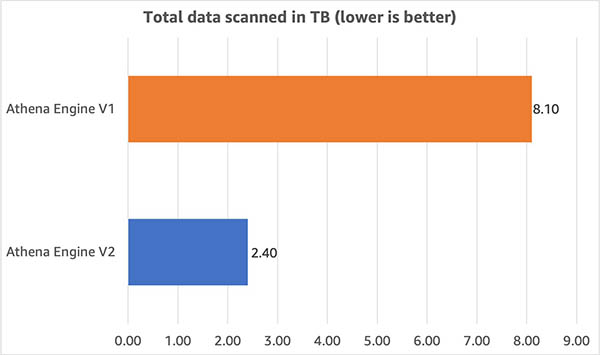
We also compared the amount of data scanned by queries in this benchmark. As shown in the following graph, we found that the data scanned – and the resulting per-query costs – were 70% lower with engine V2.
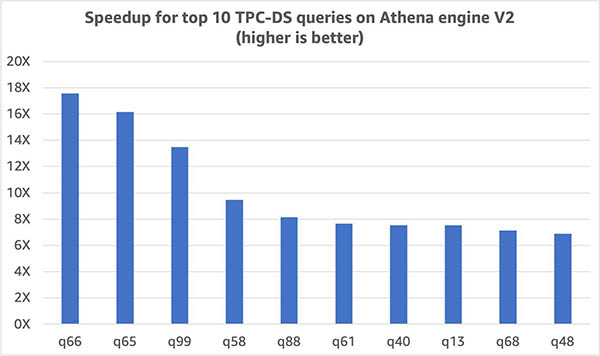
Queries in our benchmark were consistently more performant with engine V2. The following graph shows the 10 TPC-DS queries with the largest improvement in runtime. For this set of queries, runtime improved by 6.9 times.
Now, let’s look at some of the enhancements in engine V2 that contributed towards these astounding results.
Performance enhancements in engine V2
The Athena engine is built upon Presto, an open-source distributed SQL query engine optimized for low latency. We’re continuously improving Athena’s engine with enhancements developed by Athena and AWS engineering teams as well as incorporating contributions from the PrestoDB and Trino community. The result is an engine with continuously increasing performance and cost-effectiveness benefits that are automatically available to you. A few such enhancements are highlighted in the following sections.
More efficient joins via dynamic filtering and dynamic partition pruning
Dynamic filtering and dynamic partition pruning improves the query runtime and reduces data scanned for queries with joins and a very selective filter clause for the table on the right side of join, as shown in the following example.
In the following query, Table_B is a small table with a very selective filter. (column_A = “value”). After the selective filter is applied to Table_B, a value list for a joined column Table_B.date is extracted first, and it’s pushed down to a joined table Table_A as a filter. It’s used to filter out unnecessary rows and partitions of Table_A. This results in reading fewer rows and partitions from the source for Table_A and helping reduce query runtime and data scan size, which in turn helps reduce the costs of running the query in Athena.
More intelligent join ordering and distribution selections
Choosing a better join order and join algorithm is critical to better query performance. They can easily affect how much data is read from a particular table, how much data is transferred to the intermediate stages through networks, and how much memory is needed to build up a hash table to facilitate a join. Join order and join algorithm decisions are part of the cost-based optimizer that uses statistics to improve query plans by deciding how tables and subqueries are joined.
For cases where statistics aren’t available, we introduced a similar concept but through enumerating and analyzing the metadata of the S3 files to optimize query plans. The logic for those rules takes into account both small tables and small subqueries while making these decisions. For example, consider the following query:
The syntactical join order is A join B join C. With those optimization rules, if A is considered a small table after retrieving the approximate size through fast file enumeration on Amazon S3, the rules place table A on the build side (the side that is built into a hash table for a join) and makes the join as a broadcast join to speed up the query and reduce memory consumption. Additionally, the rules reorder the joins to minimize the intermediate result size, which helps further speed up the overall query runtime.
Nested field pruning for complex data types
In this improvement for Parquet and ORC datasets, when a nested field is queried in a complex data type like struct, array of structs, or map, only the specific subfield or nested field is read from the source instead of reading the entire row. If there is a filter on the nested field, Athena can now push down the predicate to the Parquet or ORC file to prune the content at source level. This has led to significant savings in data scanned and a reduction in query runtime. With this feature, you don’t need to flatten your nested data to improve query performance.
Optimized top N rank() functions
Previously, all input data for rank() window functions was sent to the window operator for processing and the LIMIT and filter clauses were applied at a later stage.
With this optimization, the engine can replace the window operator with a top N rank operator, push down the filters, and only keep top N (where N is the LIMIT number) entries for each window group to save memory and I/O throughput.
A good example of a query that benefited from this optimization is query 67 (shown in the following code) of the TPC-DS benchmark. It contains a subquery with a memory- and CPU-heavy window function rank() that is applied to the output of another subquery, which generates a huge amount of intermediate data after scanning the large fact table store_sales. The output of this subquery is further filtered with LIMIT and comparison operators before returning the final results. Because of the LIMIT and comparison operator, only records with the lowest 100 total sales are meaningful in each item category window group; the rest are discarded. Processing these records (which are discarded later through window functions) is memory and network intensive.
With this enhancement, only a small amount of data is kept in memory and sent across the network because the filters and limits are pushed down. This makes the entire workflow more efficient and enables the engine to process a larger amount of data with the same resources.
Query 67 was unsuccessful on engine V1 despite the considerable effort and time needed to scan (approximately 75 GB of data) and process data that was eventually thrown away due to resource exhaustion. On engine V2, this query completes in approximately 165 seconds and scans only 17 GB of data.
In the following query, filter clause rk <=100 and limit 100 are pushed to the rank() function as described earlier:
Other optimizations
In addition to these optimizations, the following contributed towards faster queries and reduced data scan for the queries in our benchmark:
- Further pushdown of LIMIT and filter operators to reduce the intermediate results size and data scanned from the sources
- Enhancement of aggregation and window functions to consume much less memory and provide better performance
- Addition of a distributed sort for the ORDER BY operator to utilize resources effectively which helps sort more data reliably
- Improvement in task-scheduling mechanisms for more efficient processing across resources
Conclusion
With the performance optimizations in the latest engine V2 of Athena, you can run queries faster and at lower cost than before. The TPC-DS benchmark queries on engine V2 showed a 3x improvement in query runtime and cost reduction of 70%.
In our mission to innovate on behalf of customers, Athena routinely releases performance and reliability enhancements on its latest engine version. To stay up to date with the latest engine release, ensure your Athena workgroups have selected Automatic query engine upgrade in your workgroup settings.
For more information, see the performance enhancements for engine V2 and check our release notes to learn about new features and enhancements.
About the Authors
 Pathik Shah is a Sr. Big Data Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
Pathik Shah is a Sr. Big Data Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
 Xuanyu Zhan is a Software Development Engineer on Amazon Athena. He joined Athena in 2019 and has been working on different areas of Athena engine V2, including engine upgrade, engine reliability, and engine performance.
Xuanyu Zhan is a Software Development Engineer on Amazon Athena. He joined Athena in 2019 and has been working on different areas of Athena engine V2, including engine upgrade, engine reliability, and engine performance.
 Sungheun Wi is a Sr. Software Development Engineer on Amazon Athena. He joined AWS in 2019 and has been working on multiple database engines such as Athena and Aurora, focusing on analytic query processing enhancements.
Sungheun Wi is a Sr. Software Development Engineer on Amazon Athena. He joined AWS in 2019 and has been working on multiple database engines such as Athena and Aurora, focusing on analytic query processing enhancements.