AWS Big Data Blog
Security considerations for Amazon Redshift cross-account data sharing
Data driven organizations recognize the intrinsic value of data and realize that monetizing data is not just about selling data to subscribers. They understand the indirect economic impact of data and the value that good data brings to the organization. They must democratize data and make it available for business decision makers to realize its benefits. Today, this would mean replicating data across multiple disparate databases, which requires moving the data across various platforms.
Amazon Redshift data sharing lets you securely and easily share live data across Amazon Redshift clusters or AWS accounts for read purposes. Data sharing can improve the agility of your organization by giving you instant, granular, and high-performance access to data across Amazon Redshift clusters without manually copying or moving it. Data sharing provides you with live access to data so that your users can see the most up-to-date and consistent information as it’s updated in Amazon Redshift clusters.
Cross-account data sharing lets you share data across multiple accounts. The accounts can be within the same organization or across different organizations. We have built in additional authorization steps for security control, since sharing data across accounts could also mean sharing data across different organizations. Please review AWS documentation on cross-account data sharing and a blog from our colleague for detailed steps. We also have a YouTube video on setting up cross-account data sharing for a business use case which you can refer as well.
Cross-account data sharing scenario
For this post, we will use this use case to demonstrate how you could setup cross-account data sharing with the option to control data sharing to specific consumer accounts from the producer account. The producer organization has one AWS account and one Redshift cluster. The consumer organization has two AWS accounts and three Redshift clusters in each of the accounts. The producer organization wants to share data from the producer cluster to one of the consumer accounts “ConsumerAWSAccount1”, and the consumer organization wants to restrict access to the data share to a specific Redshift cluster, “ConsumerCluster1”. Sharing to the second consumer account “ConsumerAWSAccount2” should be disallowed. Similarly, access to the data share should be restricted to the first consumer cluster, “ConsumerCluster1”.
Walkthrough
You can setup this behavior using the following steps:
Setup on the producer account:
- Create a data share in the Producer cluster and add schema and tables.
- Setup IAM policy to control which consumer accounts can be authorized for data share.
- Grant data share usage to a consumer AWS account.
Setup on the consumer account:
- Setup IAM policy to control which of the consumer Redshift clusters can be associated with the producer data share.
- Associate consumer cluster to the data share created on the producer cluster.
- Create database referencing the associated data share.

Prerequisites
To set up cross-account data sharing, you should have the following prerequisites:
- Three AWS accounts. Once for producer < ProducerAWSAccount1>, and two consumer accounts – <ConsumerAWSAccount1> and < ConsumerAWSAccount2>.
- AWS permissions to provision Amazon Redshift and create an IAM role and policy.
We assume you have provisioned the required Redshift clusters: one for the producer in the producer AWS Account, two Redshift clusters in ConsumerCluster1, and optionally one Redshift cluster in ConsumerCluster2
- Two users in producer account, and two users in consumer account 1
- ProducerClusterAdmin
- ProducerCloudAdmin
- Consumer1ClusterAdmin
- Consumer1CloudAdmin
Security controls from producer and consumer
Approved list of consumer accounts from the producer account
When you share data across accounts, the producer admin can grant usage of the data share to a specific account. For additional security to allow the separation of duty between the database admin and the cloud security administrator, organizations might want to have an approved list of AWS accounts that can be granted access. You can achieve this by creating an IAM policy listing all of the approved accounts, and then add this policy to the role attached to the Producer Cloud Account Admin.
Creating the IAM Policy for the approved list of consumer accounts
- On the AWS IAM Console, choose Policies.
- Choose Create policy.

- On the JSON tab, enter the following policy:
This is the producer side policy. Note: you should replace the following text with the specific details for your cluster and account.
-
- “Resource”: “*” – Replace “*” with the ARN of the specific data share.
- <AWSAccountID> – Add one or more consumer account numbers based on the requirement.

- From the Amazon Redshift console in the producer AWS Account, choose Query Editor V2 and connect to the producer cluster using temporary credentials.

- After connecting to the producer cluster, create the data share and add the schema and tables to the data share. Then, grant usage to the consumer accounts<ConsumerAWSAccount1> and <ConsumerAWSAccount2>
Note: the GRANT will be successful even though the account is not listed in the IAM policy. But the Authorize step will validate against the list of approved accounts in the IAM policy, and it will fail if the account is not in the approved list.
- Now the producer admin can authorize the data share by using the AWS CLI command line interface or the console. When you authorize the data share to <ConsumerAWSAccount1>, then the authorization is successful.


- When you authorize the data share to <ConsumerAWSAccount2>, the authorization fails, as the IAM policy we setup in the earlier step does not allow data share to <ConsumerAWSAccount2>.


We have demonstrated how you can restrict access to the data share created on the producer cluster to specific consumer accounts by using a conditional construct with an approved account list in the IAM policy.
Approved list of Redshift clusters on consumer account
When you grant access to a data share to a consumer account, the consumer admin can determine which Redshift clusters can read the data share by associating it with the appropriate cluster. If the organization wants to control which of the Redshift clusters the admin can associate with the data share, then you can specify the approved list of Redshift clusters by using the cluster ARN in an IAM policy.
- On the AWS IAM Console, choose Policies.
- Choose Create policy.

- On the JSON tab, enter the following policy:
This is the consumer side policy. Note: you should replace the following text with the specific details for your cluster and account.
-
- “Resource”: “*” – Replace “*” with the ARN of the specific data share.
- Replace “<ProducerDataShareARN>” with the ARN of the data share created in the Redshift cluster in AWS Consumer account 1.
- Replace “<ConsumerRedshiftCluster1ARN>” with the ARN of the first Redshift cluster in AWS Consumer account 1.
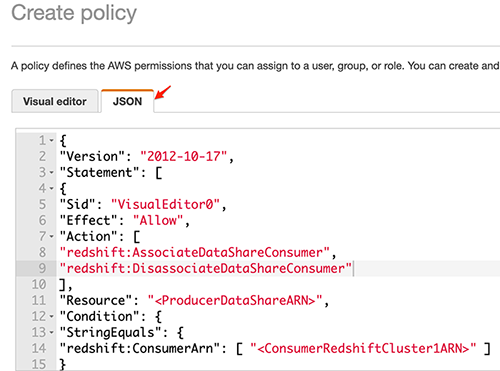
- Now the consumer admin can associate the data share using the AWS CLI command line interface or the console. When you associate the Redshift cluster 1
<ConsumerRedshiftCluster1ARN >, the association is successful.


- Now the consumer admin can associate the data share by using the AWS CLI command line interface or the console. When you associate the Redshift cluster 2
<ConsumerRedshiftCluster2ARN >, the association fails.

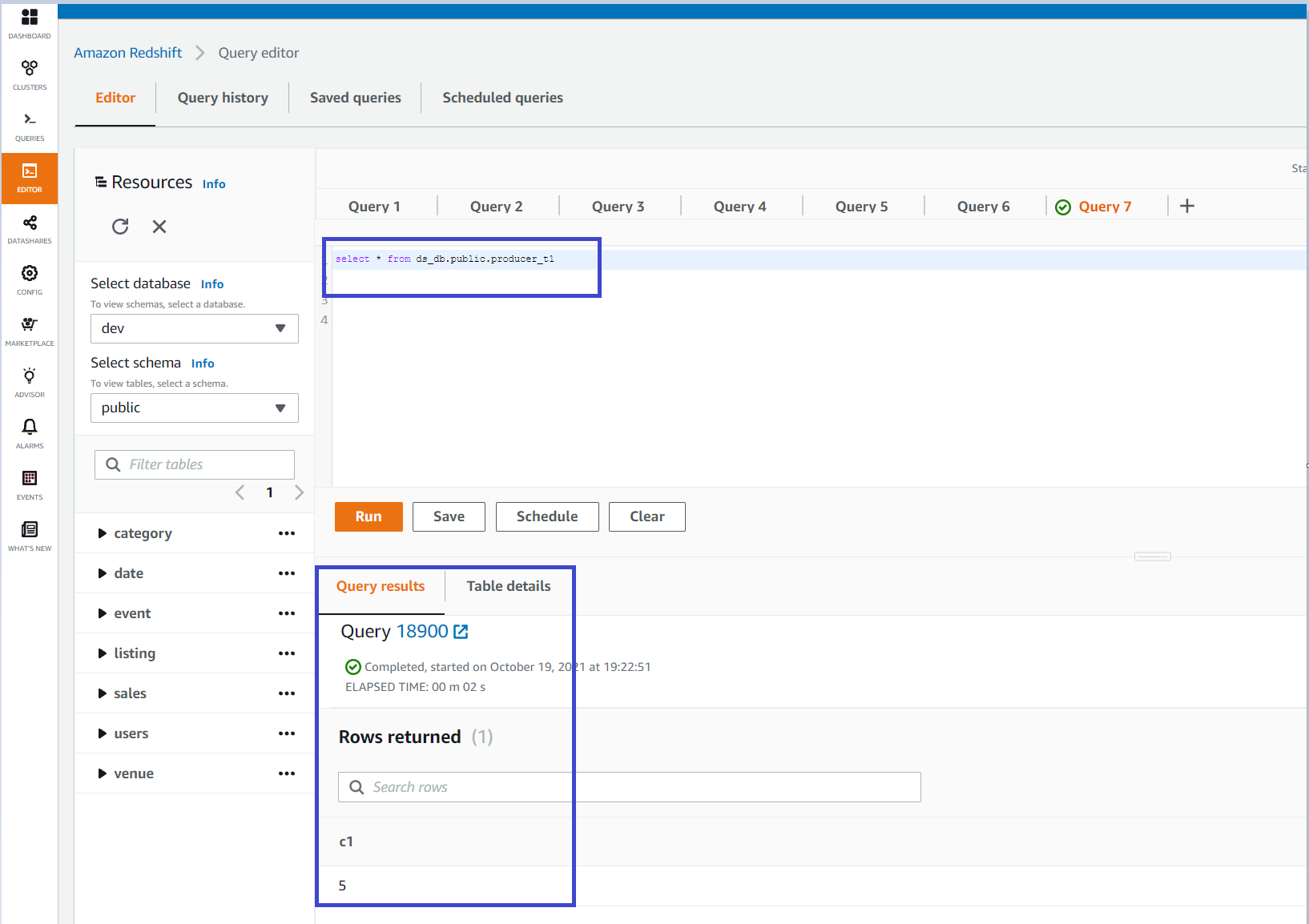
- After associating the Consumer Redshift cluster 1 to the producer data share, from the Amazon Redshift console in the Consumer AWS Account, choose Query Editor V2 and connect to the consumer cluster using temporary credentials.
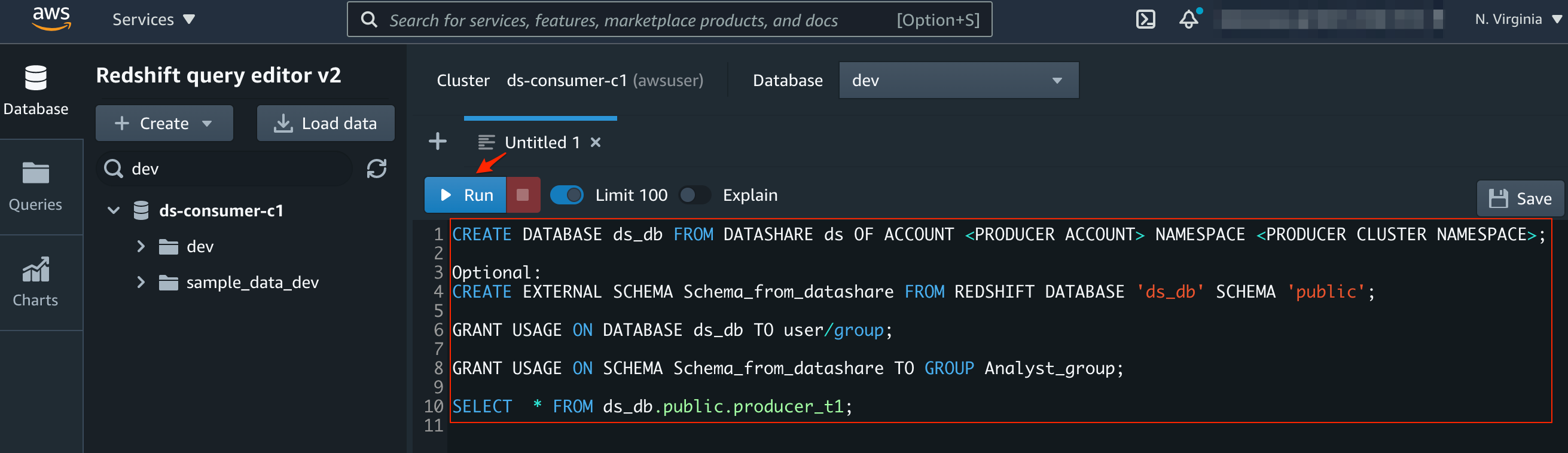
- After connecting to the consumer cluster, you can create a database referencing the data share on the producer cluster, and then start querying the data.
You can use the query editor or the new Amazon Redshift Query Editor V2 to run the statements above to read the shared data from the producer by creating an external database reference from the consumer cluster.
Conclusion
We have demonstrated how you can restrict access to the data share created on the producer cluster to specific consumer accounts by listing approved accounts in the IAM policy.
On the consumer side, we have also demonstrated how you can restrict access to a particular Redshift cluster on the consumer account for the data share created on the producer cluster by listing approved Redshift cluster(s) in the IAM policy. Enterprises and businesses can use this approach to control the boundaries of Redshift data sharing at account and cluster granularity.
We encourage you to try cross-account data sharing with these additional security controls to securely share data across Amazon Redshift clusters both within your organizations and with your customers or partners.
About the Authors
 Rajesh Francis is a Senior Analytics Customer Experience Specialist at AWS. He specializes in Amazon Redshift and focuses on helping to drive AWS market and technical strategy for data warehousing and analytics. Rajesh works closely with large strategic customers to help them adopt our new services and features, develop long-term partnerships, and feed customer requirements back to our product development teams to guide the direction of our product offerings.
Rajesh Francis is a Senior Analytics Customer Experience Specialist at AWS. He specializes in Amazon Redshift and focuses on helping to drive AWS market and technical strategy for data warehousing and analytics. Rajesh works closely with large strategic customers to help them adopt our new services and features, develop long-term partnerships, and feed customer requirements back to our product development teams to guide the direction of our product offerings.
 Kiran Sharma is a Senior Big Data Consultant for AWS Professional Services. She works with our customers to architect and implement Big Data Solutions on variety of projects on AWS.
Kiran Sharma is a Senior Big Data Consultant for AWS Professional Services. She works with our customers to architect and implement Big Data Solutions on variety of projects on AWS.
 Eric Hotinger is a Software Engineer at AWS. He enjoys solving seemingly impossible problems in the areas of analytics, streaming, containers, and serverless.
Eric Hotinger is a Software Engineer at AWS. He enjoys solving seemingly impossible problems in the areas of analytics, streaming, containers, and serverless.