Containers
Fast NLP model development with containers on AWS Fargate
This post is contributed by Efi Gazarov, Cloud Infrastructure Team Leader at Amenity Analytics
NLP: the key to unlocking the full potential of data sources
NLP, or natural language processing, is used to understand, interpret, and process language the way a human would by using computational methods. It sits under the umbrella of AI, along with machine learning, deep learning, and other technologies used in data science. NLP is what allows voice assistants (Siri, Alexa, Google Assistant, etc.) to understand your commands or your email client to filter spam messages. Although NLP has been around since the 1950s, advancements in AI have made NLP tasks such as speech processing, natural language generation, and text analysis faster and more accurate.
NLP’s superpower lies in its ability to provide contextual understanding and insights from inherently complex human language within paragraphs of text—parsing, analyzing, and scoring words found in previously untapped data sources. All language conveys meaning: people, places, things, abstract concepts, sentiment, expectations, and intent. A powerful NLP solution can systematically capture, categorize, and store this meaning from valuable documents to be used in business functions that matter to you most.
NLP takes all text elements from a page and translates them into relevant keywords, entities, concepts, categories, and sentiment. These elements include not just paragraphs, but also headers, sentences, and fragments. NLP carries out this process for millions of documents, quickly and systematically.
Any organization that deals with large quantities of documents can benefit from a text analytics program that uses NLP. NLP can process and extract key information from virtually any form of digital text including online news, PDFs, transcripts, e-mails, forums, customer reviews, and surveys.
Development cycle: from idea to production
Amenity’s developers will create an NLP model and upload it to the system. The model will then analyze millions of documents and examines the findings. This process repeats until the results fulfill the business requirements with high precision and recall.

The development cycle for an NLP model is critical. To be able to deliver results fast, the cycle has to be fast. It has to be cost efficient, too.
Amenity uses AWS Fargate and Spot to compress this creativity cycle—reducing the time from idea to production in a cost-effective way.
Going serverless
A disclaimer
Amenity’s previous generation system was built with Amazon Elastic Container Service (Amazon ECS) on EC2, which was capable of analyzing millions of documents. Yet, we realized that scaling it up to analyze hundreds of millions of documents would not be cost effective for us. Had we gone ahead with the previous design, it would have resulted in an almost linear increase in cost. Also, the idea of managing a cluster with 1000 EC2 machines was daunting. Moreover, for us to get enough CPU performance, we would have had to pay extra for all types of instances. This meant paying even more for unutilized RAM. Ultimately, we decided to switch to something that was better at scaling but without increasing DevOps and operational overhead.
When we rewrote a majority of the system, we used the serverless model, leaving the NLP engine as the only component to run in a container environment, yet switching to run ECS on Fargate instead of ECS on EC2. We favor a serverless methodology and mindset. We love to code more than we like tweaking servers and managing environments. The ideas reflected in code are what deliver value for our customers.
The majority of our current system is serverless, relying heavily on AWS Lambda functions. The core of our system contains our current generation, custom, and monolithic NLP engine, implemented in Java. It’s a flexible engine that uses sophisticated models (crafted by our NLP specialists) to address any business requirements for our customers.
Fargate enables us to run serverless container images
Analyzing a hundred documents is easy; analyzing hundreds of millions of documents is hard. The task requires a really big cluster of computing power. For example, we require 2000 vCPUs to analyze 200 million articles quickly.
The “on-demand” and “pay-as-you-go” properties and qualities of AWS (Amazon Web Services) help with cost efficiency. Yet, maintaining such a cluster is a complex task, even in the cloud. This is where AWS Fargate becomes such a game changer for Amenity. AWS Fargate removes the need to maintain the infrastructure and allows us to concentrate on our business requirements.
With very few changes, we have the ability to run our containerized NLP engine at scale.
There is no need to manage EC2 instances as with Amazon ECS on EC2. There is also no need to bid for Spot instances or use some third-party solution to do the bidding on your behalf. We just tell Fargate how much power (container instances) we want, and we have it at our disposal. AWS assumes responsibility for provisioning and managing the resources we need to meet our demand.
How we use AWS Fargate in the core of our system
System description
At the core of Amenity’s solution, we have the NLP engine, which is versioned, packed, and published to Amazon Elastic Container Registry (Amazon ECR) as a container image by the dev team.
We have hundreds of NLP models for each business requirement, which are bundled and uploaded to an S3 bucket by the NLP model creators.
Every aspect of our system is automated and accessible through a dedicated web interface.
AWS CloudFormation stack for each NLP model
For every NLP model uploaded by the creators, Amenity automatically deploys a CloudFormation stack. The stack contains everything needed for an analysis job, including the Amazon ECS and AWS Fargate configurations. We “translate” an NLP model into everything needed for that model to process huge amounts of documents with AWS Fargate.
Here are a few essential components:
- ECS service configuration
- ECS task definition with the appropriate NLP engine version (container image) and NLP model object key/path
- Input queue for the references to documents this model will process
- Output S3 bucket for the analysis results to be saved
- Auto scaling rule *
- Capacity provider strategy *
* Has a direct impact on the cost of operation
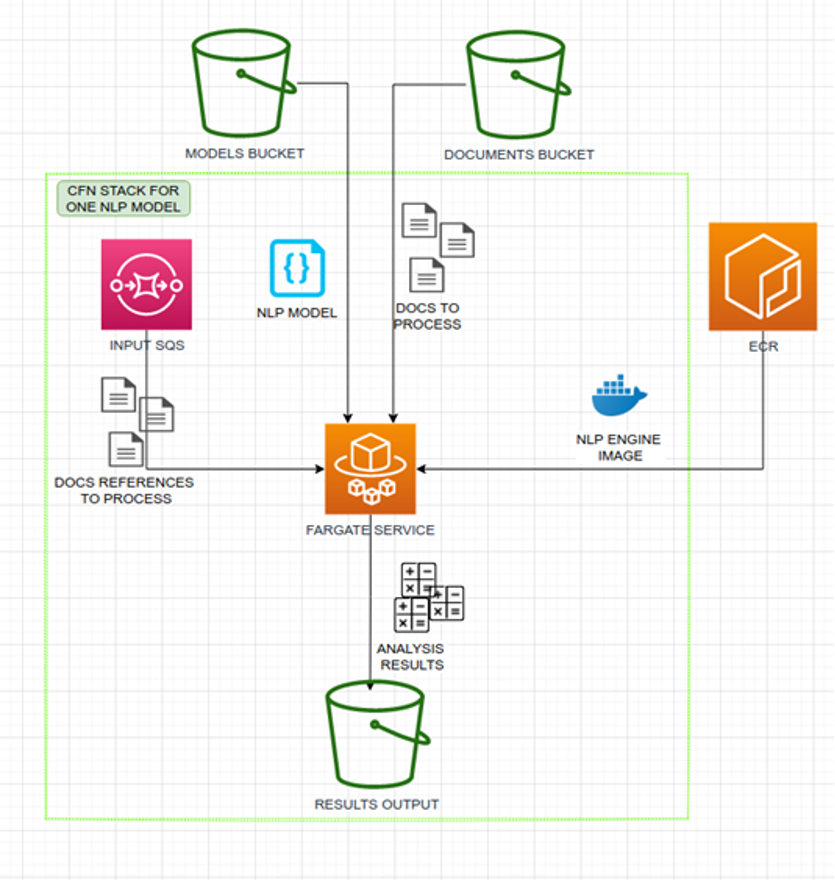
Figure 4 shows a simplified example of one NLP model deployed to the system. We have hundreds of these models deployed at any moment.
The Java application wrapping the NLP engine is a simple queue worker/processor. The worker will perform these steps:
- Init the NLP engine with configured NLP model (download model from S3 into memory)
- Pass the control of execution to SQS listener and wait for a message in dedicated queue
- On message received, download (to memory) document from S3 bucket by the reference key received in the message
- Process the document with the NLP engine
- Store results in dedicated S3 bucket
- Go to step 2
Once the CloudFormation stack is deployed, our NLP model is fully operational and ready to analyze hundreds of millions of documents. The only thing left is to populate the input queue with the document references (S3 keys) and wait for the workers (tasks) swarm to process it.
Autoscaling rules
Autoscaling rules make sure that our service (NLP model) is scaled up or down depending on the amount of documents waiting to be processed.
We use the “step-scaling” type of rule in conjunction with a custom metric that tracks the amount of visible messages in a particular SQS queue.
The messages to tasks ratio is manually tuned for our needs. For example, for 1,000 messages (which are documents waiting to be processed), we want the “desired count” of tasks to be 20. For 10,000 messages, it will be 300 tasks.
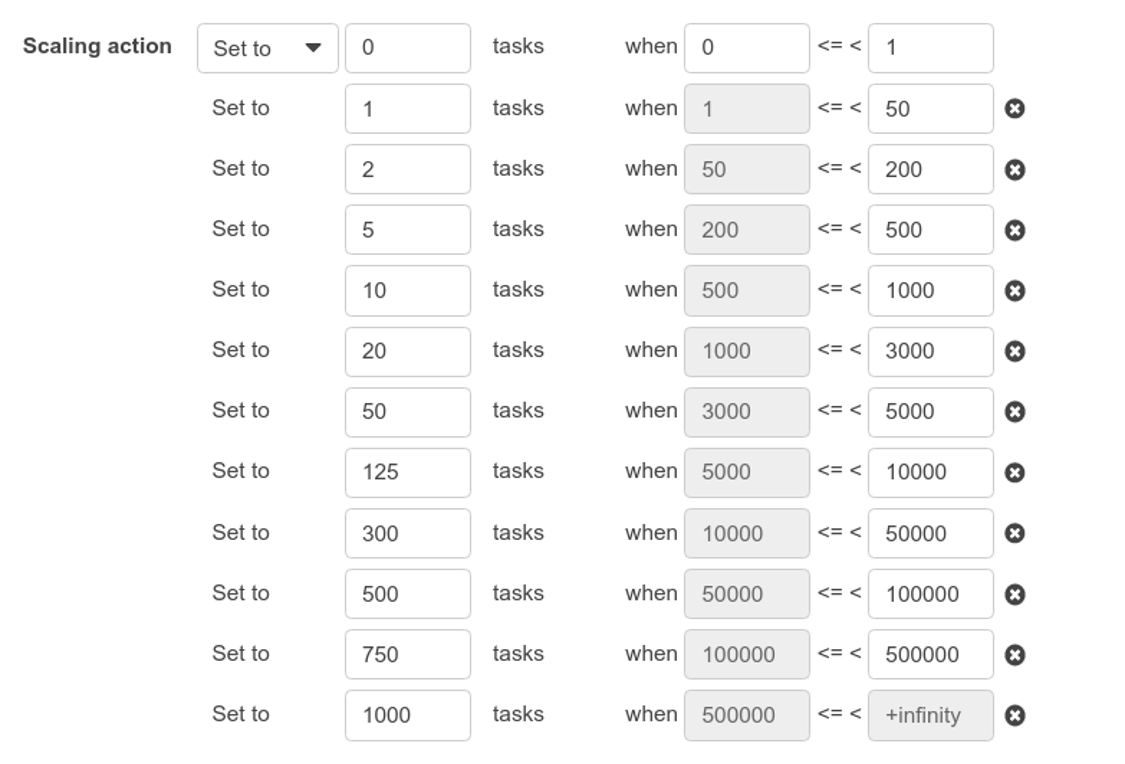
It is essential for the sake of cost efficiency to fine tune the scaling rules in order to find the right balance between the provisioned capacity and the current demand, otherwise, we would be paying for idle resources.
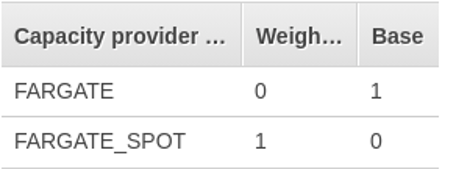
Capacity provider strategy
We use capacity providers to save money. We choose the FARGATE_SPOT provider as our primary capacity provider and use the FARGATE provider to initiate only one task. This is to ensure that at least one task will be started even if there are no FARGATE_SPOT resources currently available.
The configuration in Figure 6 ensures that once one task is initiated by the FARGATE provider, all the others will be provisioned by FARGATE_SPOT (when available).
With FARGATE_SPOT tasks, AWS can reclaim, i.e. kill, a task mid-process. Ordinarily this might cause an issue, but our application can tolerate interruptions like this.
Cost saving example from our real usage
We estimate that the transition from ECS on EC2 (SPOT) to Fargate (SPOT) saves us at least 25 percent of the operational cost for the NLP analysis aspect.
It’s easy to see from the table below (Figure 7) how FARGATE SPOT saves us on the cost of running our workloads on a daily basis.
Example of a typical month’s usage
| Usage Type | Amount Hours | Cost $ |
| FARGATE SPOT Memory | 1,140,543 | 1,586 |
| FARGATE SPOT VCPU | 142,567 | 1,806 |
| FARGATE Memory | 470,044 | 2,089 |
| FARGATE VCPU | 62,043 | 2,361 |
Additional usage for Amazon ECS and AWS Fargate at Amenity
When you manage large amounts of data like we do, you need to modify and update how you handle that data once in a while. We always do so in the fastest, most cost effective way possible.
For example, we have an auxiliary machine-learning (ML) process that allows us to identify companies that are being covered in news articles. Normally it’s executed as a Lambda function. Once a quarter, or after a major upgrade to the ML model, we have to execute that analysis for half a billion articles.
With the exact pattern (queue processor) that we use for NLP processing, we are capable of executing an ML model against half a billion articles. With Amazon ECS and AWS Fargate, it becomes a matter of wrapping our ML engine and model into a container image, parallelizing (splitting) the workload, and letting the Amazon ECS and AWS Fargate services process it.
Conclusions:
There are two major reasons we have chosen AWS Fargate for running containers at scale.
First, is the serverless and maintenance-free nature of the service. It allows us to abstract away the infrastructure and allows our developers to concentrate their efforts on delivering business requirements and value to our customers faster. With AWS Fargate the burden of maintenance is shifted to AWS. We only provide the configurations.
The second benefit is the cost reduction of FARGATE_SPOT. It requires minimal configuration changes to run our workloads on FARGATE_SPOT tasks and we benefit from the reduced price.
This is why AWS Fargate stands out when it comes to running containers at scale.
Check out Amenity’s ESG Spotlight and NLP analysis on other financial trends.
About Amenity Analytics
Amenity Analytics develops enterprise natural language processing platforms for finance, insurance, and media industries that extract critical insights from mountains of documents. With our software solutions, we provide the fastest, most accurate and scalable way for businesses to get human-level understanding of information from text.