Containers
GPU sharing on Amazon EKS with NVIDIA time-slicing and accelerated EC2 instances
In today’s fast-paced technological landscape, the demand for accelerated computing is skyrocketing, particularly in areas like artificial intelligence (AI) and machine learning (ML). One of the primary challenges the enterprises face is the efficient utilization of computational resources, particularly when it comes to GPU acceleration, which is crucial for ML tasks and general AI workloads.
NVIDIA GPUs hold the leading market share for ML workloads, setting them apart as the top choice in high-performance and accelerated computing. Their architecture is specifically designed to handle the parallel nature of computational tasks, making them indispensable for ML and AI workloads. These GPUs excel at matrix multiplication and other mathematical operations, significantly speeding up computations and paving the way for quicker and more precise AI-driven insights.
While NVIDIA GPUs deliver impressive performance, they are also expensive. For organizations, the challenge lies in maximizing the utilization of these GPU instances to get the best value for their investment. It’s not just about harnessing the full power of the GPU; it’s about doing so in the most cost-effective manner. Efficient sharing and allocation of GPU resources can lead to significant cost savings, allowing enterprises to reinvest in other critical areas.
What is a GPU?
A Graphical Processing Unit (GPU) is a specialized electronic circuit designed to accelerate the processing of images and videos for display. While Central Processing Units (CPUs) handle the general tasks of a computer, GPUs take care of the graphics and visual aspects. However, their role has expanded significantly beyond just graphics. Over the years, the immense processing power of GPUs has been harnessed for a broader range of applications, especially in areas that require handling vast amounts of math operations simultaneously. This includes fields like artificial intelligence, deep learning, scientific simulations, and, of course, machine learning. The reason GPUs are so efficient for these tasks is their architecture. Unlike CPUs that have a few cores optimized for sequential serial processing, GPUs have thousands of smaller cores designed for multi-tasking and handling parallel operations. This makes them exceptionally good at performing multiple tasks at once.
GPU concurrency choices
GPU concurrency refers to the ability of the GPU to handle multiple tasks or processes simultaneously. Different concurrency choices are available to users, each with its own set of advantages and ideal use cases. Let’s delve into these approaches:
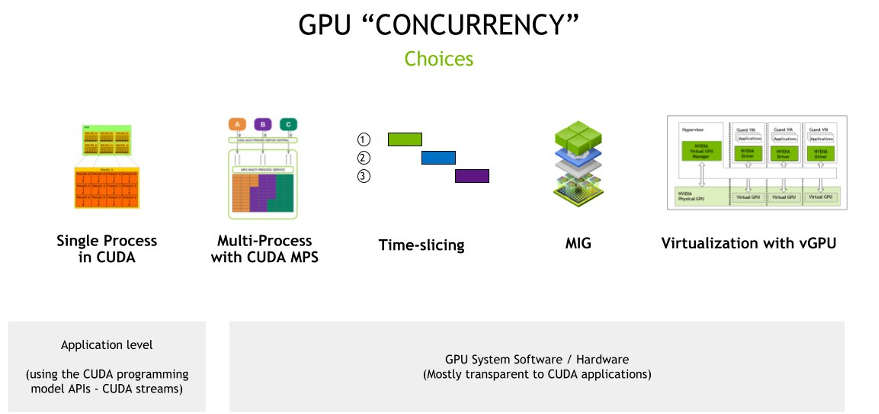
Single Process in CUDA
- This is the most basic form of GPU utilization, where a single process accesses the GPU using CUDA (Compute Unified Device Architecture) for its computational needs.
- Ideal for standalone applications or tasks that require the full power of the GPU.
- When the GPU is exclusively allocated for a specific high-compute task and there is no need for sharing.
Multi-process with CUDA Multi-Process Service (MPS)
- CUDA MPS is a feature of CUDA that allows multiple processes to share a single GPU context. This means multiple tasks can access the GPU simultaneously without significant context-switching overhead.
- When multiple applications or tasks require concurrent access to the GPU.
- Ideal for scenarios where tasks have varying GPU demands and you want to maximize GPU utilization without significant overhead.
Time-slicing
- Time-slicing involves dividing GPU access into small time intervals, allowing different tasks to use the GPU in these predefined slices. It’s akin to how a CPU might time-slice between different processes.
- Suitable for environments with multiple tasks that need intermittent GPU access.
- When tasks have unpredictable GPU demands, ensuring fair access to the GPU for all tasks is desired.
Multi-Instance GPU (MIG)
- MIG, specific to NVIDIA’s A100 Tensor Core GPUs, allows a single GPU to be partitioned into multiple instances, each with its own memory, cache, and compute cores. This ensures guaranteed performance for each instance.
- When you aim to guarantee a specific level of performance for particular tasks.
- In multi-tenant environments where the goal is to ensure strict isolation.
- To maximize GPU utilization in cloud environments or data centers.
Virtualization with virtual GPU (vGPU)
- NVIDIA vGPU technology allows multiple virtual machines (VMs) to share the power of a single physical GPU. It virtualizes the GPU resources, allowing each VM to have its own dedicated slice of the GPU.
- In virtualized environments, the objective is to extend GPU capabilities to multiple virtual machines.
- For cloud service providers or enterprises, the aim is to offer GPU capabilities as a service to clients.
- When the goal is to ensure data isolation between different tasks or users.
Importance of time-slicing for GPU-intensive workloads
Time-slicing, in the context of GPU sharing on platforms like Amazon EKS, refers to the method where multiple tasks or processes share the GPU resources in small time intervals, ensuring efficient utilization and task concurrency.
Here are scenarios and workloads that are prime candidates for time-slicing:
Multiple small-scale workloads:
- For organizations running multiple small-to medium-sized workloads simultaneously, time-slicing ensures that each workload gets a fair share of the GPU, maximizing throughput without the need for multiple dedicated GPUs.
Development and testing environments:
- In scenarios where developers and data scientists are prototyping, testing, or debugging models, they might not need continuous GPU access. Time-slicing allows multiple users to share GPU resources efficiently during these intermittent usage patterns.
Batch processing:
- For workloads that involve processing large datasets in batches, time-slicing can ensure that each batch gets dedicated GPU time, leading to consistent and efficient processing.
Real-time analytics:
- In environments where real-time data analytics is crucial, and data arrives in streams, time-slicing ensures that the GPU can process multiple data streams concurrently, delivering real-time insights.
Simulations:
- For industries like finance or healthcare, where simulations are run periodically but not continuously, time-slicing can allocate GPU resources to these tasks when needed, ensuring timely completion without resource waste.
Hybrid workloads:
- In scenarios where an organization runs a mix of AI, ML, and traditional computational tasks, time-slicing can dynamically allocate GPU resources based on the immediate demand of each task.
Cost efficiency:
- For startups or small-and medium-sized enterprises with budget constraints, investing in a fleet of GPUs might not be feasible. Time-slicing allows them to maximize the utility of limited GPU resources, catering to multiple users or tasks without compromising performance.
In essence, time-slicing becomes invaluable in scenarios where GPU demands are dynamic, where multiple tasks or users need concurrent access, or where maximizing the efficiency of GPU resources is a priority. This is especially true when strict isolation is not a primary concern. By identifying and implementing time-slicing in these scenarios, organizations can ensure optimal GPU utilization, leading to enhanced performance and cost efficiency.
Solution overview: Implementing GPU sharing on Amazon EKS
Amazon EKS users can enable GPU sharing by integrating the NVIDIA Kubernetes device plugin. This plugin exposes the GPU device resources to the Kubernetes system. By doing so, the Kubernetes scheduler can now factor in these GPU resources when making scheduling decisions, ensuring that workloads requiring GPU resources are appropriately allocated without the system directly managing the GPU devices themselves.
To illustrate GPU sharing, we’ll deploy a TensorFlow application that trains a convolutional neural network (CNN) on the CIFAR-10 dataset. Initially, we’ll launch five replicas of the application, with each pod consuming one GPU by default, without time-slicing enabled. Subsequently, we’ll activate GPU sharing and scale the deployment to 20 replicas, all taking advantage of the single available GPU on the node.
Pre-requisites:
- Install eksdemo, an easy option for learning, testing, and demoing Amazon EKS.
- Install helm.
- Install AWS CLI.
- Install kubectl.
- Install jq.
Solution walkthrough
Create an EKS cluster with NVIDIA GPU-backed EC2 instances
Note: All EC2 instances powered by NVIDIA GPUs support time-slicing. However, it’s essential to verify device and driver versions and any specific GPU type constraints when implementing time-slicing.
The following commands will create the required resources for our testing:
Note: Replace the Instance type and Region with your desired options
This command creates a new EKS cluster named gpusharing-demo. The cluster will have instances of type t3.large and will consist of two nodes. The cluster will be created in the US West (Oregon) AWS Region.
This command creates a new node group named gpu within the gpusharing-demo cluster. The node group will have instances of type p3.8xlarge, which are GPU-optimized instances. There will be one node in this node group.

If you’re interested to learn more about eksdemo , you can refer to the GitHub repo.
Deploying the NVIDIA GPU device plugin on Amazon EKS
The NVIDIA GPU device plugin enhances the capability of kubernetes to manage GPU resources similarly to how it handles CPU and memory. This is achieved by exposing the GPU capacity on each node, which the Kubernetes scheduler then uses to allocate pods that request GPU resources. This device plugin runs as a daemonset on every node in your cluster and communicates with the Kubernetes API server to advertise the node’s GPU capacity. This ensures that when a pod needs GPU resources, it’s placed on a node that can fulfill that requirement.
Note: The device plugin treats the GPU as an extended resource. This approach, while integrating seamlessly with the Kubernetes API, does come with certain limitations, especially when using tools like Karpenter. By understanding that this allocation is done through the Kubernetes API and not any physical alteration on the node, users can better navigate and potentially troubleshoot any related challenges.
In this step, I am manually adding a label to the node that has GPUs so that we can schedule GPU workloads to this node. Also, the NVIDIA device plugin daemonset will run only on the node that has GPU to advertise them to the kubelet.
Note: Replace <nodename> with the node that has GPUs.
Install the NVIDIA Kubernetes device plugin using the Helm chart on the GPU node with the label eks-node=gpu.
The Helm nvdp-values.yaml file can be found in eks-gpu-sharing-demo repo.
Once the device plugin is deployed, you can verify it by running this command:
![]()
We have one GPU node, so we have the NVIDIA device plugin running as a daemonset on that node.
To request GPU resources, you can include a resources field in your deployment specification that includes a requests field for `nvidia.com/gpu`.
For example, take a look at the sample deployment manifest where a pod is requesting an entire GPU:
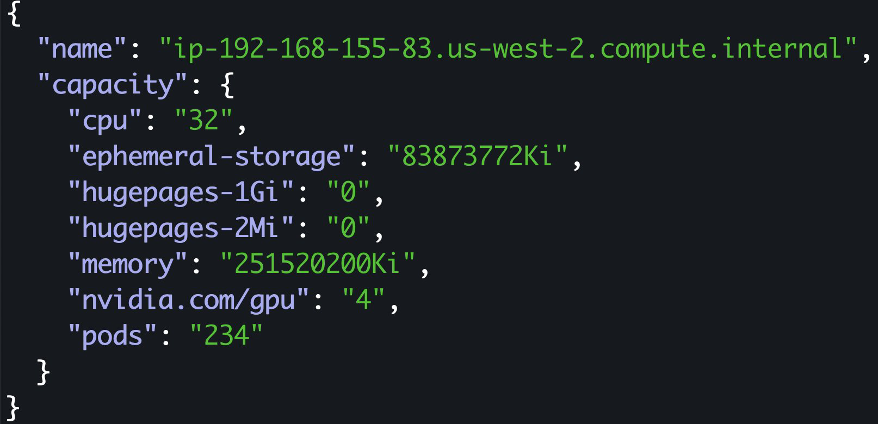
Run this command to see the GPUs available on one of the nodes. We currently have four GPUs available on p3.8xlarge and the GPUs are advertised by the kubernetes NVIDIA device plugin.
Note: We have not enabled time-slicing configuration
Deploy a sample workload to demonstrate time-slicing functionality
We will deploy a sample workload to demonstrate the time-slicing functionality, where a Python script trains a CNN on the CIFAR-10 dataset using Tensorflow and Keras. This dataset, comprising 60,000 images across 10 categories, will be automatically downloaded in the container. The script also features real-time data augmentation to enhance model performance.
The Python code is available in the eks-gpu-sharing-demo repo.
Create a kubernetes namespace:
Create a deployment
The deployment will run five pods to train a CNN model on the CIFAR-10 dataset.
The code is available in this eks-gpu-sharing-demo repo.

We are using a P3.8xlarge instance with four GPUs, and each pod requests one GPU. Observing the pods, one is in a pending state due to a lack of available GPUs.

Time-slicing GPUs in EKS
GPU time-slicing in Kubernetes allows tasks to share a GPU by taking turns. This is especially useful when the GPU is oversubscribed. System administrators can create “replicas” for a GPU, with each replica designated to a specific task or pod. However, these replicas don’t offer separate memory or fault protection. When applications on EC2 instances don’t fully utilize the GPU, the time-slicing scheduler can be employed to optimize resource use. By default, Kubernetes allocates a whole GPU to a pod, often leading to underutilization. Time-slicing ensures that multiple pods can efficiently share a single GPU, making it a valuable strategy for varied Kubernetes workloads.
Enable time-slicing configuration
Create a ConfigMap and run the Helm upgrade command referencing it.
In the preceding manifest, we set 10 virtual GPUs per physical GPU, so a pod could request one virtual GPU unit, equating to 10 percent of the physical GPU’s resources.
Update your NVIDIA Kubernetes device plugin with the new ConfigMap that has time-slicing configuration:
The Helm nvdp-values.yaml file can be found in eks-gpu-sharing-demo repo.
Now that we have patched the daemonset with the new time-slicing configuration, let’s validate the number of GPU’s available:
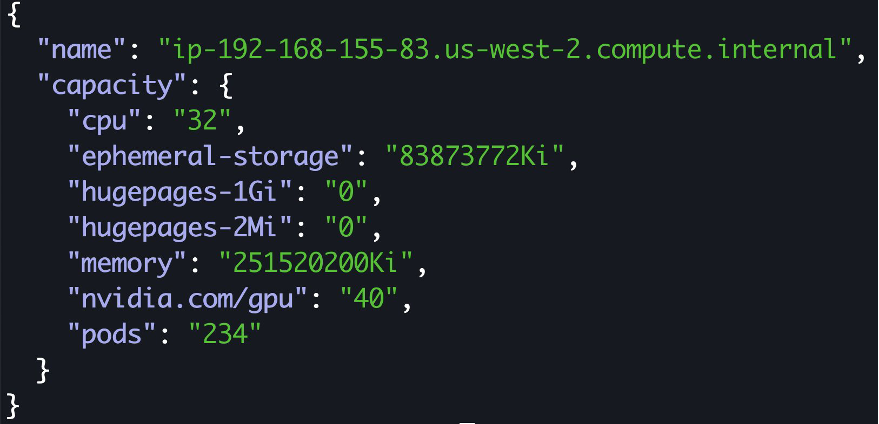
Now 40 GPUs are available for training the models.

The pod that was in pending state because of insufficient GPU is now running.
Scale the deployment
Scale the deployment to 20 replicas and we should see each pod getting enough GPU to train the ML model.
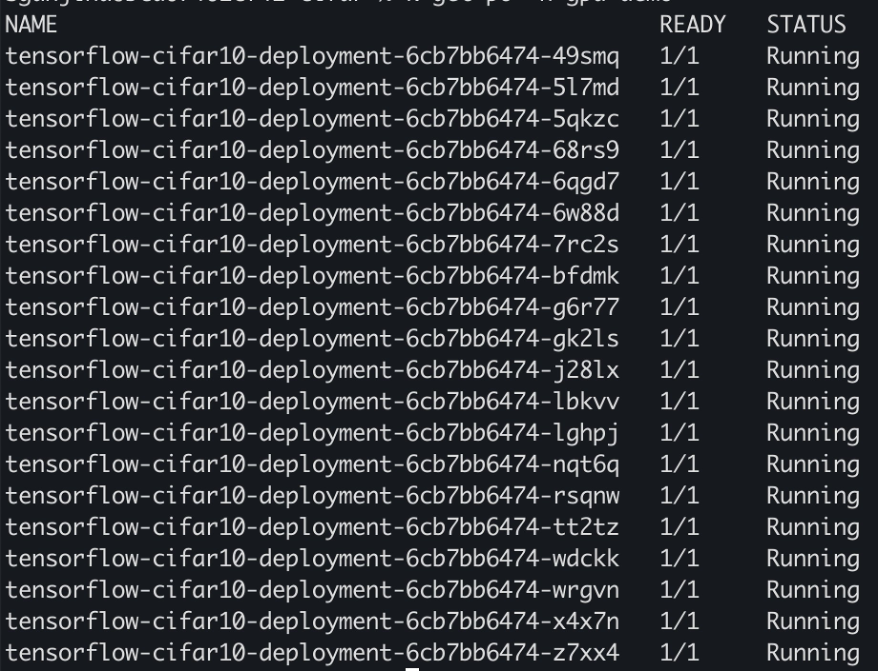
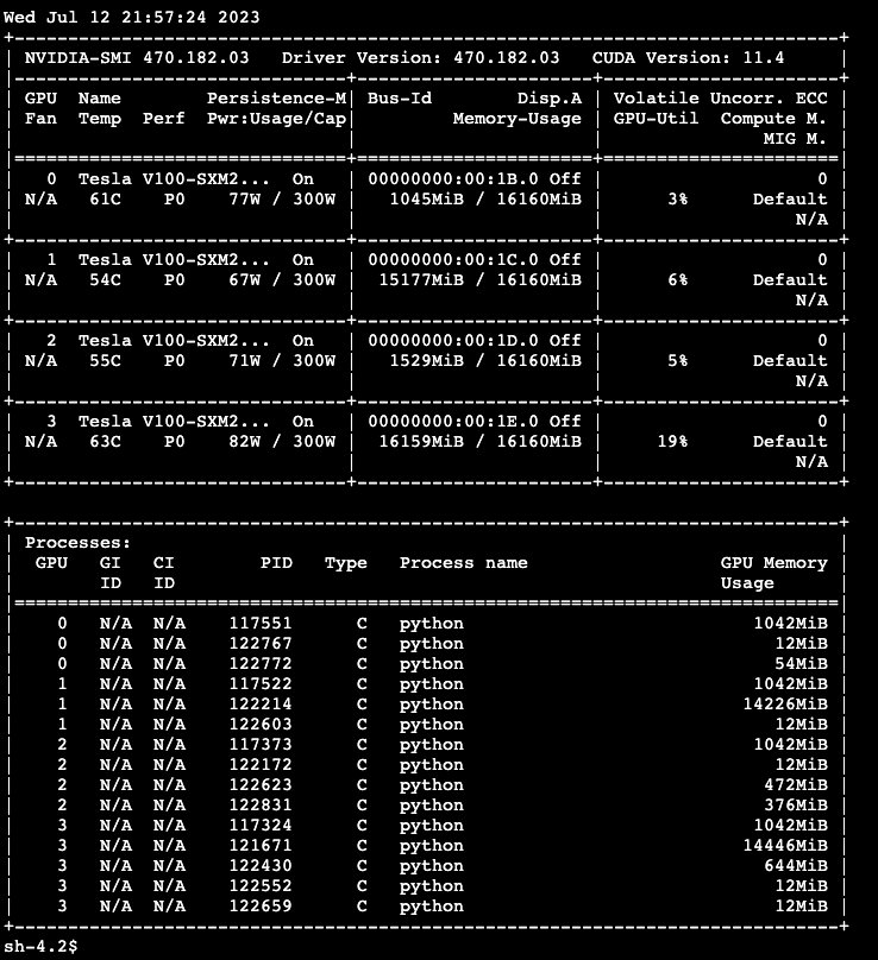
Execute the nvidia-smi command by accessing the GPU EC2 instance via the Session Manager in the AWS Systems Manager console.
In the output, specifically look for multiple processes sharing the GPUs, indicating effective GPU utilization and resource sharing.
Time-slicing benefits
- Improved resource utilization:
- GPU sharing allows for better utilization of GPU resources by enabling multiple pods to use the same GPU. This means that even smaller workloads that don’t require the full power of a GPU can still benefit from GPU acceleration without wasting resources.
- Cost optimization:
- GPU sharing can help reduce costs by improving resource utilization. With GPU sharing, you can run more workloads on the same number of GPUs, effectively spreading the cost of those GPUs across more workloads.
- Increased throughput:
- GPU sharing enhances the system’s overall throughput by enabling multiple workloads to operate at once. This is especially advantageous during periods of intense demand or high load situations, where there’s a surge in the number of simultaneous requests. By addressing more requests within the same timeframe, the system achieves improved resource utilization, leading to optimized performance.
- Flexibility:
- Time-slicing can accommodate a variety of workloads, from machine learning tasks to graphics rendering, allowing diverse applications to share the same GPU.
- Compatibility:
- Time-slicing can be beneficial for older generation GPUs that don’t support other sharing mechanisms like MIG.
Time-slicing drawbacks
- No memory or fault isolation:
- Unlike mechanisms like MIG, time-slicing doesn’t provide memory or fault isolation between tasks. If one task crashes or misbehaves, it can affect others sharing the GPU.
- Potential latency:
- As tasks take turns using the GPU, there might be slight delays, which could impact real-time or latency-sensitive applications.
- Complex resource management:
- Ensuring fair and efficient distribution of GPU resources among multiple tasks can be challenging. For more information, refer to Improving GPU utilization in Kubernetes.
- Overhead:
- The process of switching between tasks can introduce overhead in terms of computational time and resources, especially if the switching frequency is high. This can potentially lead to reduced overall performance for the tasks being executed.
- Potential for starvation:
- Without proper management, some tasks might get more GPU time than others, leading to resource starvation for less prioritized tasks.
Cleanup
To avoid charges, delete your AWS resources.
Conclusion
Using GPU sharing on Amazon EKS, with the help of NVIDIA’s time-slicing and accelerated EC2 instances, changes how companies use GPU resources in the cloud. This method saves money and boosts system speed, helping with many different tasks. There are some challenges with GPU sharing, like making sure each task gets its fair share of the GPU. But the big benefits show why it’s a key part of modern Kubernetes setups. Whether it’s for machine learning or detailed graphics, GPU sharing on Amazon EKS helps users get the most from their GPUs. Stay tuned for our next blog post, which will dive into Multi-Instance GPU (MIG) for even more ways to share GPU resources.