Containers
Load balancing Amazon ECS services with a Kubernetes Ingress Controller style approach
Introduction
A common approach to traffic routing in a Kubernetes cluster is to employ an Ingress Controller. The Ingress Controller is an application that runs in a cluster in conjunction with a load balancer and routes incoming HTTP/HTTPS/TCP requests to proxied servers according to routing rules specified in Ingress resources. When deploying to either a self-managed Kubernetes cluster or an Amazon EKS cluster, running an NGINX Ingress Controller paired with a Network Load Balancer has been proven to work very well for large scale deployments.
Amazon ECS provides several load balancing options to distribute traffic evenly across the tasks in a service. Many AWS customers that are running applications on Amazon ECS provision an Application Load Balancer to perform HTTP/HTTPS load balancing. While Application Load Balancers offer several features that make them attractive for use with Amazon ECS services, there are some use cases where they are not the most optimal choice.
For example, some customers want to build Amazon API Gateway REST APIs and setup API Gateway private integrations to expose HTTP/HTTPS endpoints within their Amazon ECS services. This requires a Network Load Balancer which connects to the gateway through a pre-configured VPC Link. However, a Network Load Balancer can make routing decisions only at the transport layer (TCP), thus necessitating an Application Load Balancer behind it to make routing decisions at the application layer (HTTP/HTTPS) and then forward traffic to services under Amazon ECS. This adds complexity to the deployment architecture. In some large-scale systems, customers employ multiple instances of Application Load Balancers because it limits the number of routing rules per listener to 100.
Drawing motivation from the Kubernetes Ingress Controller architecture, the approach outlined in this blog post addresses these scenarios and proposes a deployment architecture that uses a single instance of a Network Load Balancer to route traffic to a set of Amazon ECS services. AWS Cloud Map is used in conjunction with AWS Lambda to discover services deployed under Amazon ECS and an instance of NGINX service acts as an “ingress controller,” performing Layer 7 routing of requests to the backend services. The proposed approach can be used route traffic to Amazon ECS services running on AWS Fargate but the NGINX service itself should be deployed using EC2 launch type.
Architecture
The architecture used to implement the proposed load balancing strategy for Amazon ECS services is comprised of the following key elements:
- A Network Load Balancer with a TCP listener that is associated with a single target group. This target group is configured to register its targets using IP mode and perform health checks on its targets using HTTP protocol.
- An NGINX service deployed under Amazon ECS which registers its tasks with the aforementioned target group. NGINX performs the role of a reverse-proxy – forwarding requests to other backend services – also deployed under Amazon ECS within the same VPC.
- A set of backend of services deployed under Amazon ECS, which have registered themselves with an AWS Cloud Map service registry and, therefore, can be reached from the NGINX service using their private DNS names.
- An AWS Lambda function that is triggered on a schedule in Amazon EventBridge. It discovers backend services registered under service registries in AWS Cloud Map and then updates proxy configurations for the NGINX service.
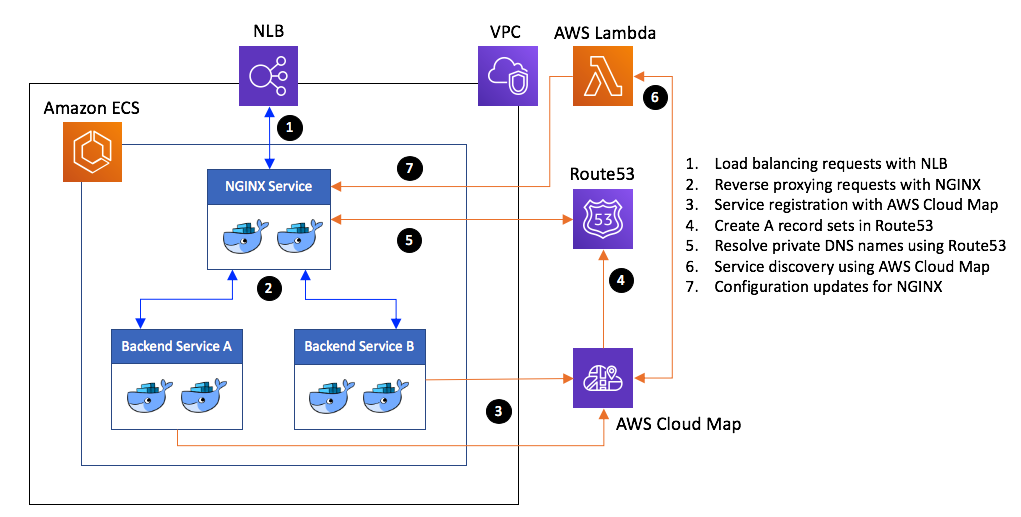
Deployment architecture for load balancing Amazon ECS services
Amazon ECS service discovery with AWS Cloud Map
AWS Cloud Map is a fully managed service that you can use to map backend services as well as resources like RDS database instances to logical names. Subsequently, applications that depend on these resources may discover them using DNS queries or API calls, referencing the resources using their logical names. Service discovery with AWS Cloud Map consists of three key components.
First, a service discovery namespace is created as follows and associated with a VPC.
VPC_ID=vpc-0bef82d36d4527eb6
SERVICE_DISCOVERY_NAMESPACE=ecs-services
OPERATION_ID=$(aws servicediscovery create-private-dns-namespace \
--vpc $VPC_ID \
--name $SERVICE_DISCOVERY_NAMESPACE \
--query "OperationId" --output text)
CLOUDMAP_NAMESPACE_ID=$(aws servicediscovery get-operation \
--operation-id $OPERATION_ID \
--query "Operation.Targets.NAMESPACE" --output text)Next, a service discovery service, which encapsulates a service registry, is created within this namespace using the JSON file shown below which contains request parameters pertaining to Amazon Route 53 routing policy, DNS record type and health checks for the service discovery service.
{
"Name": "recommender-svc",
"NamespaceId": "ns-dlog72qycbiksuia",
"Description": "CloudMap service for discovering ECS service",
"DnsConfig": {
"NamespaceId": "ns-dlog72qycbiksuia",
"RoutingPolicy": "WEIGHTED",
"DnsRecords": [
{
"Type": "A",
"TTL": 30
}
]
},
"HealthCheckCustomConfig": {
"FailureThreshold": 1
}
}This JSON file is referenced in the –cli-input-json argument when invoking the CreateService API using AWS CLI.
AWS_REGION=us-east-1
CLOUDMAP_SERVICE_ARN=$(aws servicediscovery create-service \
--cli-input-json file://cloudMapService.json \
--region $AWS_REGION \
--query "Service.Arn" --output text)One or more service discovery instances exist within this service registry and represent the resources that clients within the VPC can discover using a private DNS name constructed with the format {service-discovery-service}.{service-discovery-namespace}. In this example, the DNS name would be recommender-svc.ecs-services.
AWS Cloud Map is tightly integrated with Amazon ECS, enabling services to register themselves with a service registry. Service discovery registration can be performed only at the time of creating an Amazon ECS service, using the ARN of a service registry. Each task is registered as a service discovery instance that is associated with a set of attributes, such as ECS_CLUSTER_NAME, ECS_SERVICE_NAME. At the time of writing, the CreateService API does not support adding user-specified attributes for a task. They can only be added manually to a service discovery instance using the AWS Management Console. Custom attributes cannot be associated with a service discovery service either.
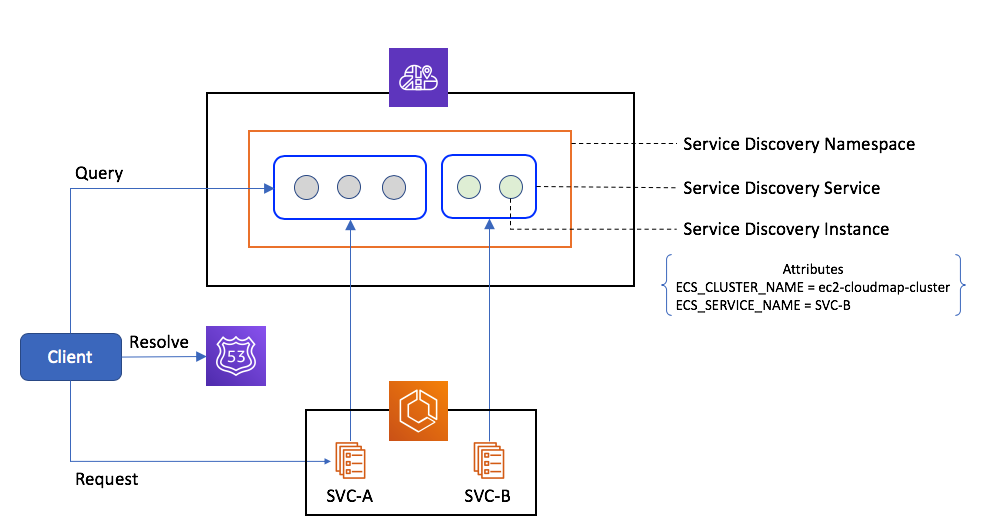
AWS Cloud Map components
An Amazon ECS service enabled for service discovery is launched as shown below, using AWS CLI.
CLUSTER_NAME=ecs-cloudmap-cluster
SERVICE_NAME=RecommenderService
TASK_DEFINITION=RecommenderTask:1
HOST_HEADER=recommender.example.io
PORT=8080
aws ecs create-service --service-name $SERVICE_NAME \
--cluster $CLUSTER_NAME \
--task-definition $TASK_DEFINITION \
--service-registries "registryArn=$CLOUDMAP_SERVICE_ARN" \
--desired-count 2 \
--deployment-configuration "maximumPercent=100,minimumHealthyPercent=50" \
--network-configuration "awsvpcConfiguration={subnets=$PRIVATE_SUBNET_IDS,securityGroups=[$SECURITY_GROUP_ID],assignPublicIp=DISABLED}" \
--tags key=host-header,value=$HOST_HEADER key=port,value=$PORT \
--scheduling-strategy REPLICA \
--launch-type EC2The task definition JSON file for the above service is shown below:
{
"family":"RecommenderTask",
"taskRoleArn":"arn:aws:iam::123456789123:role/ECS-Generic-Task-Role",
"executionRoleArn":"arn:aws:iam::123456789123:role/ECS-Task-Execution-Role",
"networkMode":"awsvpc",
"containerDefinitions":[
{
"name":"java-service",
"image":"123456789123.dkr.ecr.us-east-1.amazonaws.com/k8s-recommender:latest",
"portMappings":[
{
"containerPort":8080,
"protocol":"tcp"
}
],
"healthCheck":{
"command":[
"CMD-SHELL",
"curl -f http://localhost:8080/live || exit 1"
],
"interval":10,
"timeout":2,
"retries":2,
"startPeriod":10
},
"essential":true
}
],
"requiresCompatibilities":[
"EC2"
],
"cpu":"256",
"memory":"512"
}AWS Cloud Map creates a private hosted zone under Route 53 for each service discovery namespace and publishes A records for each of the tasks in the service using its private IP address. This can be verified using the set of commands shown below. Creation of A records is supported only if the Amazon ECS service is configured to use awsvpc mode for container networking.
HOSTED_ZONE_ID=$(aws servicediscovery get-namespace \
--id $CLOUDMAP_NAMESPACE_ID \
--region $AWS_REGION \
--query "Namespace.Properties.DnsProperties.HostedZoneId" --output text)
aws route53 list-resource-record-sets \
--hosted-zone-id $HOSTED_ZONE_ID \
--region $AWS_REGIONNGINX reverse proxy implementation
NGINX service is deployed under Amazon ECS so that it proxies requests based on the host header field in an incoming request. This is done using the server_name, and proxy_pass directives within a virtual server definition in the NGINX configuration file, namely, nginx.conf. For example, with following configuration settings, incoming requests that have their host header set to recommender.example.io are proxied to the backend service RecommenderService, which was deployed above and is registered with AWS Cloud Map using the DNS name recommender-svc.ecs-services. If weighted routing policy was used when creating the service discovery service, then Route 53 will respond to DNS queries with the IP address of one of the healthy tasks associated with the service, selected at random. Subsequently, the traffic will be proxied by the NGINX service to that task.
http {
server {
listen 80 default_server;
location /healthz {
return 200;
}
}
resolver 10.100.0.2 valid=10s;
server {
listen 80;
server_name recommender.example.io;
location / {
if ($request_method !~ ^(GET|POST|HEAD|OPTIONS|PUT|DELETE)$) {
return 405;
}
set $recommender recommender-svc.ecs-services; proxy_pass http://$recommender:8080;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_cache_bypass $http_upgrade;
}
}
}Using a variable as in $recommender to specify the DNS name in the proxy_pass directive, forces NGINX to honor the TTL specified in the Route 53 record set and re‑resolve the domain name when its TTL expires. Additionally, adding the valid parameter to the resolver directive makes NGINX ignore the TTL and re‑resolve DNS names at a specified frequency instead. Note that with this approach, we don’t achieve optimal round-robin type load balancing across all the tasks in a service. Lowering the TTL will reduce the client’s stickiness to a task but adds latency, albeit small, due to more frequent Route 53 lookups. This could be deemed as a reasonable approach given that there is no penalty for making frequent requests to Route 53 and the private DNS queries incur no charges.
A better solution would be to leverage NGINX’s ability to load balance HTTP traffic to a group of servers. A group is defined using upstream directive and servers in the group are configured using the server directive. When creating a service discovery service, if multivalue routing policy is used, then Route 53 will respond to every DNS query with the IP addresses for all the healthy instances in the service registry. If the server directive in an upstream group points to such a DNS name, then NGINX can monitor changes to these underlying IP addresses in the corresponding DNS record, and automatically apply the changes to load balancing for the upstream group, without requiring a restart. This feature is available only in the commercial version of NGINX. The nginx.conf configuration to leverage this load balancing feature is as shown below:
http {
server {
listen 80 default_server;
location /healthz {
return 200;
}
}
resolver 10.100.0.2 valid=10s;
upstream recommender-backend {
server recommender-svc.ecs-services:8080 resolve;
}
server {
listen 80;
server_name recommender.example.com;
location / {
if ($request_method !~ ^(GET|POST|HEAD|OPTIONS|PUT|DELETE)$) {
return 405;
}
proxy_pass http://recommender-backend;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_cache_bypass $http_upgrade;
}
}
}The NGINX service is deployed under Amazon ECS and registered as a target with a Network Load Balancer using the following set of commands. It makes use of the latest Docker image for NGINX available from the public repository. Note that it takes anywhere from 2-3 minutes for new targets to be fully registered with a target group attached to a Network Load Balancer. Therefore, the health check grace period, set using the –health-check-grace-period-seconds parameter, should be sufficiently large enough (e.g. 300) to prevent the ECS service scheduler from marking tasks as unhealthy and stopping them before they have time to come up.
NETWORK_LOAD_BALANCER_ID=$(aws elbv2 create-load-balancer \
--name nlb-ecs-load-balancer --subnets $PUBLIC_SUBNET_IDS \
--type network --scheme internet-facing --ip-address-type ipv4 \
--query "LoadBalancers[0].LoadBalancerArn" --output text)
TCP_TARGET_GROUP_ID=$(aws elbv2 create-target-group \
--name ecs-nlb-targetgroup \
--protocol TCP \
--port 80 \
--healthy-threshold-count 2 \
--health-check-interval-seconds 10 \
--unhealthy-threshold-count 2 \
--target-type ip \
--vpc-id $VPC_ID \
--query "TargetGroups[0].TargetGroupArn" --output text)
NLB_LISTENER_ID=$(aws elbv2 create-listener \
--load-balancer-arn $NETWORK_LOAD_BALANCER_ID \
--protocol TCP --port 80 \
--default-actions Type=forward,TargetGroupArn=$TCP_TARGET_GROUP_ID \
--query "Listeners[0].ListenerArn" --output text)
TASK_DEFINITION=NginxEfsTask:1
SERVICE_NAME=NginxService
aws ecs create-service --service-name $SERVICE_NAME \
--cluster $CLUSTER_NAME \
--task-definition $TASK_DEFINITION \
--desired-count 2 \
--load-balancers "targetGroupArn=$TCP_TARGET_GROUP_ID,containerName=nginx-service,containerPort=80" \
--deployment-configuration "maximumPercent=100,minimumHealthyPercent=50" \
--network-configuration "awsvpcConfiguration={subnets=$PRIVATE_SUBNET_IDS,securityGroups=[$SECURITY_GROUP_ID],assignPublicIp=DISABLED}" \
--health-check-grace-period-seconds 300 \
--scheduling-strategy REPLICA \
--launch-type EC2With the above setup and after creating a Route 53 CNAME record set to map recommender.example.com to the DNS name of the Network Load Balancer, external requests to that custom domain name will be routed to the RecommenderService.
Managing service health checks
As the backend services are not registered as targets with a load balancer, the ECS service scheduler can not rely on the load balancer to report container health status and to restart unhealthy containers. Instead, we rely on the integration between Amazon ECS and Docker container health checks to monitor the health of each container in a task. The container health check command is specified using the healthCheck parameter within the container definition in a task definition. Running tasks will now be assigned a health status in Amazon ECS based on the health of their essential containers. The task’s health status is integrated with the ECS service scheduler to automatically redeploy unhealthy tasks and conduct rolling updates of services. Additionally, Amazon ECS uses information from these health checks to update the health status of tasks that are registered with a service registry in AWS Cloud Map. Consequently, when service discovery clients interact with AWS Cloud Map, Route 53 responds to DNS queries with the IP address(es) of selected service discovery instance(s) from among the healthy ones. Note that in order to support this feature, the service discovery service in AWS Cloud Map should be created with the custom health check option, using the HealthCheckCustomConfig parameter.
AWS Lambda implementation for service discovery
AWS Cloud Map is not integrated yet with Amazon EventBridge. Therefore, there is no mechanism yet to find out in near real time when backend resources are registered with a service registry. Instead, an Amazon EventBridge rule is used that triggers on a regular schedule and executes an AWS Lambda function, which then discovers services using AWS SDKs.
The Lambda function is configured with a list of service discovery namespaces where we want to locate the backend resources that the NGINX service should proxy incoming requests to. Using the attributes associated with a target resource that it discovers, this Lambda function will create the relevant server block that defines a virtual server in the NGINX configuration file. The current implementation resorts to the following workaround to specify user-defined attributes for a service discovery service in AWS Cloud Map. The host header and port number to be used in the server_name and proxy_pass directives respectively within a virtual server definition are supplied in the tags attached to the Amazon ECS service when it is created. Note that tagging an Amazon ECS service requires that you opt in to the new ARN and resource ID format. This approach is not well suited for proxying requests using a more fine-grained set of rules based on URL paths. Akin to a Kubernetes Ingress object, it would be ideal to encapsulate such routing rules in a YAML object that is attached as metadata to the service discovery service in AWS Cloud Map.
A Java implementation of this Lambda function handler is shown below:
public void handle(InputStream in, OutputStream out, Context context) throws IOException {
try {
String csvCloudMapNamespaceIds = AWSConfig.getCloudMapNamespaceIds();
String[] cloudMapNamespaceIds = csvCloudMapNamespaceIds.split(",");
JsonObject discoveredServicesContainer = new JsonObject();
for (String cloudMapNamespaceId : cloudMapNamespaceIds) {
//
// Get a list of service discovery services located under the given service discovery namespace
//
GetNamespaceRequest namespaceRequest = new GetNamespaceRequest().withId(cloudMapNamespaceId);
GetNamespaceResult namespaceResult = cloudMapClient.getNamespace(namespaceRequest);
String cloudMapNamespace = namespaceResult.getNamespace().getName();
logger.info(String.format("Namespace name = %s; ID = %s", cloudMapNamespace, cloudMapNamespaceId));
ServiceFilter namespaceFilter = new ServiceFilter().withName("NAMESPACE_ID").withValues(cloudMapNamespaceId);
ListServicesRequest listServicesRequest = new ListServicesRequest().withFilters(namespaceFilter);
ListServicesResult listServicesResults = cloudMapClient.listServices(listServicesRequest);
int block = 0;
for (ServiceSummary summary : listServicesResults.getServices()) {
String cloudMapService = summary.getName();
String cloudMapServiceId = summary.getId();
logger.info(String.format("Namespace = %s; Service = %s; ID = %s", cloudMapNamespaceId, cloudMapService, cloudMapServiceId));
ListInstancesRequest instancesRequest = new ListInstancesRequest().withServiceId(cloudMapServiceId);
List<InstanceSummary> instanceSummaries = cloudMapClient.listInstances(instancesRequest).getInstances();
if (instanceSummaries.size() == 0) continue;
String instanceId = instanceSummaries.get(0).getId();
//
// Get ECS service name and cluster name from the service discovery instance attributes
//
GetInstanceRequest instanceRequest = new GetInstanceRequest().withServiceId(cloudMapServiceId).withInstanceId(instanceId);
GetInstanceResult instanceResult = cloudMapClient.getInstance(instanceRequest);
Map<String, String> instanceAttributeMap = instanceResult.getInstance().getAttributes();
String ecsClusterName = instanceAttributeMap.get("ECS_CLUSTER_NAME");
String ecsServiceName = instanceAttributeMap.get("ECS_SERVICE_NAME");
DescribeServicesRequest servicesRequest = new DescribeServicesRequest()
.withCluster(ecsClusterName)
.withServices(ecsServiceName);
//
// Get host header and service port from the tags associated with the ECS service
//
DescribeServicesResult servicesResult = ecsClient.describeServices(servicesRequest);
Service ecsService = servicesResult.getServices().get(0);
ListTagsForResourceRequest tagRequest = new ListTagsForResourceRequest().withResourceArn(ecsService.getServiceArn());
ListTagsForResourceResult tagsResult = ecsClient.listTagsForResource(tagRequest);
List<Tag> serviceTags = tagsResult.getTags();
String hostHeader = null;
int port = -1;
for (Tag serviceTag : serviceTags) {
String key = serviceTag.getKey();
String value = serviceTag.getValue();
logger.info(String.format("Key = %s; Value = %s", key, value));
if (key.equalsIgnoreCase("host-header")) hostHeader = value;
if (key.equalsIgnoreCase("port")) port = Integer.valueOf(value);
}
logger.info(String.format("ECS Service = %s; Cluster = %s", ecsServiceName, ecsClusterName));
logger.info(String.format("Host Header = %s; Port = %d", hostHeader, port));
JsonObject discoveredService = new JsonObject();
discoveredService.put("host-header", hostHeader);
discoveredService.put("service-url", String.format("%s.%s", cloudMapService, cloudMapNamespace));
discoveredService.put("service-port", String.format("%d", port));
discoveredService.put("variable-name", String.format("servers%d", ++block));
discoveredServicesContainer.put(hostHeader, discoveredService);
}
}
//
// Check if the list of services discovered is any different from the one discovered in an earlier execution'
//
if (s3Client.doesObjectExist(AWSConfig.getS3Bucket(), DISCOVERED_SERVICES)) {
String jsonString = S3Store.getObject(s3Client, AWSConfig.getS3Bucket(), DISCOVERED_SERVICES);
JsonObject previousDiscoveredServicesContainer = new JsonObject(jsonString);
if (!checkForDeltas(discoveredServicesContainer, previousDiscoveredServicesContainer)) {
logger.info("No changes were found among the backend services discovered from Cloud Map");
return;
}
}
S3Store.putObject(s3Client, AWSConfig.getS3Bucket(), "discoveredServices", discoveredServicesContainer.encodePrettily());
//
// For each ECS service that was discovered, create a "server" block for a virtual server definition in the NGINX configuration file
//
String nginxServerTemplate = S3Store.getObject(s3Client, AWSConfig.getS3Bucket(), NGINX_SERVER_TEMPLATE);
StringBuilder sBuilder = new StringBuilder();
sBuilder.append(System.lineSeparator());
discoveredServicesContainer.forEach(pair -> {
JsonObject discoveredService = (JsonObject) pair.getValue();
String hostHeader = discoveredService.getString("host-header");
String serviceUrl = discoveredService.getString("service-url");
String servicePort = discoveredService.getString("service-port");
String variableName = discoveredService.getString("variable-name");
logger.info(String.format("Crearing 'server' block for %s from template", serviceUrl));
String nginxServer = nginxServerTemplate
.replaceAll("HOST_HEADER", hostHeader)
.replaceAll("SERVICE_URL", serviceUrl)
.replaceAll("SERVICE_PORT", servicePort)
.replaceAll("VARIABLE_NAME", variableName);
sBuilder.append(nginxServer);
sBuilder.append(System.lineSeparator());
});
String serverConfigurations = sBuilder.toString();
//
// Create a complete NGINX configuration file
//
String nginxConfigurationTemplate = S3Store.getObject(s3Client, AWSConfig.getS3Bucket(), NGINX_CONF_TEMPLATE);
String nginxConfiguration = nginxConfigurationTemplate
.replace("SERVER_CONFIGURATIONS", serverConfigurations)
.replace("DNS_RESOLVER", AWSConfig.getDNSResolver());
logger.info(String.format("NGINX configuration file:\n%s", nginxConfiguration));
//
// Save the file to the EFS file system
//
FileOutputStream outputStream = new FileOutputStream(NGINX_CONF_FILE_PATH);
byte[] strToBytes = nginxConfiguration.getBytes();
outputStream.write(strToBytes);
outputStream.close();
} catch (Exception ex) {
logger.error(String.format("Exception occured when using Service Discovery APIs; %s", ex.getMessage()));
}
}Updating NGINX configuration
When the Lambda function detects that the list of services discovered under a given list of namespaces is different from that of previous execution, it updates the nginx.conf configuration file for the NGINX service deployed under Amazon ECS. This update process can be performed in a couple of different approaches.
The configuration file could be saved to an Amazon S3 bucket and then loaded by the NGINX service. While Amazon ECS supports loading a set of environment variables from a file hosted in an Amazon S3 bucket, this feature does not yet support loading configuration files with generic text content. An alternative is to save the configuration file to an access point in Amazon Elastic File System (Amazon EFS) which is mounted into each task in the NGINX service. This is the approach adopted here. AWS Lambda integrates with Amazon EFS to support secure, shared file system access for Lambda applications. The Lambda function shown above is configured to mount the shared NFS file system during initialization within the same VPC where the Amazon ECS services are deployed.
In order for NGINX to reload the configuration file, a HUP signal should be sent to the master process. This will apply the new configuration settings without any downtime as well as guarantee that changes will be rolled back to the old configuration if the reload process were to fail. This is implemented using a sidecar container that shares the same Linux process namespace as that of the NGINX container. This execution mode is enabled by setting the pidMode parameter to task in the task definition. This parameter is only supported for containers or tasks using the EC2 launch type. Both the NGINX and sidecar containers mount the access point where the nginx.conf configuration file resides. When the sidecar detects a new configuration file, it sends a HUP signal to the NGINX master process. The Python code for this sidecar is shown below:
import os
import time
from pathlib import Path
filepath= Path('/etc/nginx/nginx.conf')
lastModified = os.stat(filepath).st_mtime
while (True):
try:
time.sleep(1)
lastModifiedCurrent = os.stat(filepath).st_mtime
if (lastModifiedCurrent > lastModified):
lastModified = lastModifiedCurrent
pidMaster = os.popen("pgrep nginx").read().split("\n")[0]
os.popen("kill -s HUP " + pidMaster)
except:The Python application is containerized using the Dockerfile shown below.
FROM python:3
WORKDIR /app
COPY reload.py /app
CMD ["python", "reload.py"]The task definition JSON file for running an Amazon ECS task with the NGINX and sidecar containers is shown below:
{
"family":"NginxEfsTask",
"taskRoleArn":"arn:aws:iam::123456789012:role/ECS-Generic-Task-Role",
"executionRoleArn":"arn:aws:iam::123456789012:role/ECS-Task-Execution-Role",
"networkMode":"awsvpc",
"pidMode":"task",
"containerDefinitions":[
{
"name":"nginx-service",
"image":"nginx",
"essential":true,
"portMappings":[
{
"containerPort":80,
"protocol":"tcp"
}
],
"mountPoints":[
{
"sourceVolume":"efsVolume",
"containerPath":"/etc/nginx",
"readOnly":false
}
]
},
{
"name":"nginx-reloader",
"image":"123456789012.dkr.ecr.us-east-1.amazonaws.com/nginx:reload",
"essential":true,
"dependsOn": [
{
"containerName": "nginx-service",
"condition": "START"
}
],
"mountPoints":[
{
"sourceVolume":"efsVolume",
"containerPath":"/etc/nginx",
"readOnly":false
}
]
}
],
"volumes":[
{
"name":"efsVolume",
"efsVolumeConfiguration":{
"fileSystemId":"fs-123ab456",
"transitEncryption":"ENABLED",
"authorizationConfig":{
"accessPointId":"fsap-0a12f123456789012",
"iam":"ENABLED"
}
}
}
],
"requiresCompatibilities":[
"EC2"
],
"cpu":"256",
"memory":"512"
}Concluding remarks
The Network Load Balancer is designed to handle tens of millions of requests per second while maintaining high throughput at ultra low latency. NGINX can handle hundreds of thousands of clients simultaneously and can perform the role of an efficient reverse proxy, supporting a number of application load‑balancing methods for HTTP, TCP, and UDP load balancing. The Kubernetes Ingress Controller has successfully paired these two technologies to provide enterprise grade delivery services for microservices deployed using Kubernetes. This blog post discussed the details of adopting a similar approach to distribute traffic to microservices deployed under Amazon ECS in conjunction with AWS Cloud Map for service discovery. Feature enhancements, such as the ability to add custom attributes using AWS Cloud Map APIs at the time of creating a service in Amazon ECS, and the ability to load generic configuration files into an Amazon ECS service from an Amazon S3 bucket can help improve the current implementation to make it more suitable for enterprise grade delivery.