Containers
MYCOM OSI’s Amazon EKS adoption journey
This post was co-written by Dirk Michel, SVP SaaS and Digital Technology at MYCOM OSI, and Andreas Lindh, Specialist Solutions Architect, Containers at AWS.
In this blog post, we will discuss how MYCOM OSI was able to lower costs and improve the flexibility of their Assurance Cloud Service (ACS) SaaS platform and bring-your-own-cloud (BYOC) option by implementing support for Amazon Elastic Kubernetes Service (Amazon EKS) as the foundational service where their software runs.
MYCOM OSI offers Assurance, Automation & Analytics SaaS applications for the digital era. The Assurance Cloud Service provides critical end-to-end performance, fault and service quality management, and supports AI/ML-driven closed-loop assurance for hybrid, physical, and virtualized networks, across all domains, within a SaaS model.
Challenges and decision made
At MYCOM OSI, our Assurance Cloud Service SaaS offering runs on and supports one specific Kubernetes-based platform distribution. Over time, we saw that customers wanted us to support more platform vendor choices and also provide more choice around compute options. At the same time, customers expected us to improve cost-performance and support those that have existing investments and skillsets with other platform vendors. Equally, we saw Amazon EKS become a popular ask from our direct customer base, coupled with the broadening capability set around Amazon EKS itself. In a nutshell, we needed to:
- Provide more platform vendor optionality for our BYOC customers.
- Enable Amazon EKS support for our SaaS tenants.
- Unlock efficiencies by supporting a broader array of Amazon EC2 instance types.
- Use software from the vast open-source ecosystem.
Assurance Cloud Service (ACS) runs a complex set of telecommunication network and service assurance applications that our communication service provider (CSP) customers use in their mission-critical network/service operations centers (NOC/SOC). On the one hand, the applications collect and ingest tens of billions of data records per hour in real time and near real time. On the other hand, the ingested datasets are then processed online by our analytics and AI/ML engines to derive actionable insights for incident management and triaging use cases within NOCs, SOCs, and other customer departments that depend on them.
Equally, we develop our applications with a microservices approach and they are designed to deploy as containerized stateful and stateless workloads that use the full spectrum of Kubernetes workload resources, including Deployments, StatefulSets, and DaemonSets. In aggregate, the application is composed of hundreds of microservices, and at runtime, we typically see thousands of containers.
On top of that, given the regulatory constraints and requirements of most of our CSP customers, the ACS runtime needs to be deployed in a cell-based architecture with fully isolated zero-trust tenants for each subscriber. This means that every tenant is run in distinct AWS accounts, VPCs, compute, and storage domains. The application is thus deployed by an in-house, complex deployment framework that is managed by a combination of tenant activation pipelines, templating engines, and processing scripts.
With these challenges and complexities in mind, the journey towards offering support for multiple Kubernetes-based platforms would require us to adapt our own application software as well. After assessing effort and working backward from our customer requirements, we decided to embark on this path and build support for EKS.
The journey towards Amazon EKS
With the background and motivation briefly explained, let’s discuss the steps involved in the journey toward building an application platform on top of Amazon EKS.
Starting off, we needed to understand our current state and assess the requirements of the new platform and what features and functionality we actually needed. We then needed to decide on which specific platform services we can replace, improve upon, or indeed drop entirely. Equally, we decided early on to lean towards the Kubernetes operator way of implementation wherever possible and practical, allowing us to declaratively describe resources and infrastructure.
To achieve the goal of building a new platform for our ACS to run on, we divided the effort into different phases, each with its own complexities and challenges.
Platform initialization
Historically, the platform had been initialized and deployd using a complex customized pipeline. The pipeline was responsible for executing various steps and stages, including spinning up temporary EC2 instances from where a series of imperative shell commands were executed to run preparatory steps and deploy both platform components and applications for each tenant.
While we were able to quickly get started with Amazon EKS by using the eksctl CLI tool, which proved to be a capable tool with excellent abstractions, additional lower-level flexibility was required. We evaluated options and quickly decided to adopt AWS Cloud Development Kit (AWS CDK). On the one hand, AWS CDK gave us a way of declaring a wide range of AWS resources we needed, using well-known general-purpose programming languages. On the other hand, it gave us access to the relevant CDK constructs for EKS and CDK Pipelines. The CDK EKS construct, in particular, provided us with the flexibility we needed for managing Kubernetes manifests on the cluster, allowing for configuration of certain add-ons such as GitOps controllers straight from the IaC tool. The initial inspiration for this setup was taken from the aws-samples/aws-cdk-eks-fluxv2-example GitHub repository but tailored to our needs and rewritten in Python as that is the preferred language of the team.
Adopting GitOps to complete the platform initialization with cluster add-on deployment was a key step for us. This choice allowed us to initialize the EKS control plane with CDK, followed by GitOps-bootstrapping the tenant add-ons and platform services in a day-1 setting, and then use the same developer-centric approach and tooling for its day-2 lifecycle management.
Security
Security is a critical component of the ACS platform, and Amazon EKS provides a secure, managed Kubernetes control plane. However, we further secure the control plane with secret encryption, and we further safeguard the Kubernetes API server endpoint with restricted IP address ranges.
We required further controls on top of the Kubernetes data plane as well so as to achieve a strong overall security posture and to ensure that our own applications conform to security standards before they are admitted into the cluster runtime. To achieve this, we evaluated various options and decided to adopt Kyverno as a Kubernetes policy engine, allowing us to audit and enforce policies for Kubernetes objects, for example, declining the admission of privileged pods. With the approach of adopting Kyverno admission controllers early, we are prepared for the upcoming deprecation of the Kubernetes Pod Security Policies (PSP) object.
Pursuing ways to further reduce attack vectors, we decided to use Bottlerocket, a purpose-built operating system for running containers, as opposed to a general-purpose operating system that typically comes with more packages and software preinstalled than strictly necessary for running a container. Bottlerocket also comes with SELinux enabled in enforcing mode.
Following best practices, cluster add-ons and applications running in the EKS clusters that require access to AWS resources, we will be using IAM Roles for Service Accounts. This shifts the scope of permissions from the EC2 instance level to Kubernetes Service Accounts, allowing for a more fine-grained permission model.
Storage
Storage is a core component in the ACS platform, where high-performance storage is required for many data ingestion and analytics application workloads running on the platform. Previously, MYCOM OSI had been using static provisioning of Amazon Elastic Block Store (Amazon EBS) volumes for stateful application components, which then had to be managed and mounted into containers in a specific way.
For block storage, we adopted the Amazon EBS CSI driver, enabling a simpler architecture in which the workloads requiring persistent storage can be scheduled on any worker node and enabling dynamic EBS volume provisioning for pods requiring these volumes. For shared storage, we adopted the EFS CSI driver in dynamic provisioning mode, which completed our move from static, extrinsic storage provisioning towards dynamic Kubernetes workload-driven storage provisioning and consumption. Both controllers expose a rich feature set of their respective AWS storage services to the cluster, and we implemented our compliance and business continuity requirements for data encryption and backup.
Traffic management
As applications get deployed onto the cluster, a mechanism is required for directing incoming traffic to them, preferably in a Kubernetes native way. After evaluating various options around ingress controllers, we decided to use AWS Load Balancer Controller for this purpose so that application developers can define Kubernetes Services and Ingresses and have the load balancer controller automatically provision the Network Load Balancers or Application Load Balancers on their behalf. Key features for us included the ability to load balance traffic directly to the appropriate pods for efficient inter-Availability Zone traffic handling and low latency, as well as use of the IngressClass and ParameterGroups features that enabled us to aggregate many ingresses behind a single AWS load balancer.
We also needed to make the load balancers discoverable at predictable DNS names so that our customers and subscribers can access our applications in a “SaaS-Consumer and SaaS-Provider” setting provided through AWS PrivateLink. To address this need, we opted to use the open-source ExternalDNS Kubernetes controller to handle that use case, which automatically registers DNS records with Amazon Route53 for the provisioned services.
This approach enabled us to shift the responsibility of, for example, load balancer provisioning and defining DNS records in Route53 away from the CDK/CloudFormation codebase and into the actual applications deployed on top of the platform. This is analogous to the theme of dynamic storage provisioning via CSI controllers, where platform engineers can offer dynamic platform services that provision AWS resources on demand and thus no longer have to coordinate with the application engineers to statically provision such components.
Reliability
A foundational area of cluster reliability is its ability to add or remove worker node capacity when appropriate. Today, EKS does not ship with a predetermined mechanism for cluster auto scaling, which gave us the opportunity to work with what we are familiar and have experience with. Thus, we use OIDC federated authentication and IAM roles for service accounts to deploy Cluster Autoscaler with auto-discovery turned on. In combination with managed node groups for Bottlerocket, the Cluster Autoscaler (CA) controller interacts with the underlying Auto Scaling Groups and adjusts the desired number of worker nodes according to our rule definitions and preferences. In our case, we are running several stateful services, which meant ensuring that the CA triggers scaling that is Availability Zone-aware.
Observability
Our approach to platform observability was to adopt AWS native options first, as we aimed at using the graphical user interfaces of the AWS Management Console for Amazon EKS and Amazon CloudWatch. With that decision in hand, we were able to move quickly and include the Kubernetes controllers for CloudWatch metrics and CloudWatch Logs. Both cluster add-ons deploy as DaemonSets, detect and scrape the observability data from the worker nodes and workloads, and push them into CloudWatch. Once the data arrives in CloudWatch, we leverage Container Insights and other available dashboard facilities that are natively available.
Application considerations
Designing and building effective platforms and platform services can require a sound understanding of the target application workloads that would run on them. This helps with balancing the many trade-offs one makes at the platform level. That said, we took the opportunity to reevaluate the use of third-party custom resource definitions (CRDs) we had adopted over time and how we package and distribute our applications. In an effort to standardize our tooling for deploying applications and modernize the aforementioned in-house deployment framework, we decided to move away from other templating engines and standardize around Helm, which provides a single tool for templating, packaging, and deploying applications with Kubernetes. For complex applications that deploy with tens of charts, Helm proved especially useful with its built-in support for dependency management options.
As a side benefit of moving towards Helm, we now connect our GitOps controllers to our private repository of Helm charts and provide a list of applications and their corresponding version boundaries, which are then reconciled into the clusters. This separates the concerns of application definition via Helm charts and configuration of said Helm charts by providing values via manifests stored in git. We opted for FluxCD, with its rich feature set around its Helm controller and GitOps toolkit.
Summary and outlook
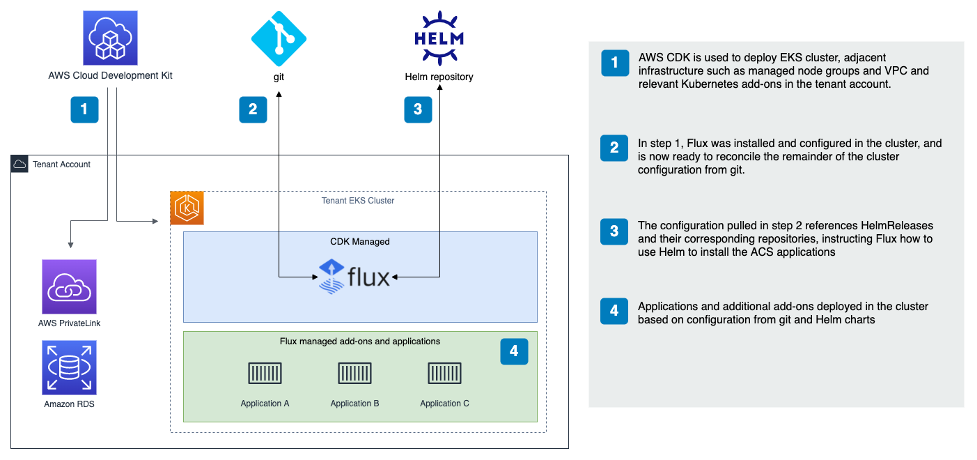
As described above, there are a lot of decisions that have been made along this journey in order to bring it all together. In summary, these are the steps that are performed upon creation of a new tenant:
- Creation of multiple district AWS accounts for each tenant and their environments, such as test, staging, and production.
- Creation of relevant infrastructure via AWS CDK, including an EKS cluster with the bare minimum add-ons for continuing with the bootstrapping of the cluster via the GitOps workflow.
- GitOps controller pulls the relevant manifests from git and applies additional add-ons alongside the ACS applications.
Steps 2 and 3 are illustrated in more detail in the following figure.
But the activity does not stop here. A range of future platform innovations, iterations, and releases is already being planned. We are actively working on evolving some of the highlighted areas. For example, on platform observability, we are starting to evaluate AWS Distro for OpenTelemetry, a very exciting project that aims at standardizing metrics, logs, and traces. In the area of cluster auto scaling, we are evaluating the role that Karpenter can play. And finally, to make AWS resource management easier for developers by surfacing them as Kubernetes objects, we are looking into AWS Controllers for Kubernetes (ACK).
Conclusion
In just a few months, using a small but effective task force team, we were able to build application support for EKS, innovate on behalf of our customers, and create platform choice and optionality. This also enables further customer choices as part of the SaaS and bring-your-own-cloud options. Amazon EKS serves as a key building block of the new platform, providing a production-grade managed Kubernetes service that reduces the operational overhead of running Kubernetes. AWS CDK has proven an efficient way of programmatically creating and managing AWS resources.
Looking ahead, the journey is not over, and one of the next steps for MYCOM OSI is to support Amazon EKS Anywhere, allowing deployment to customers with specific regulatory requirements while still using the same building blocks.
 Dirk Michel is the SVP for SaaS and Digital Technology at MYCOM OSI, a software vendor in the Service Assurance and Observability space.
Dirk Michel is the SVP for SaaS and Digital Technology at MYCOM OSI, a software vendor in the Service Assurance and Observability space.
Dirk has 20 years of experience in the telecommunication industry, focused on SaaS product engineering, infrastructure (cloud-native and Kubernetes), platform engineering, release engineering, and reliability engineering. He works closely with mobile operators that are adopting a cloud-based strategy for service assurance, with a particular focus on cloud architectures, big data analytics, and ML in the 5G era. Dirk leads the strategic technology collaboration with AWS, is an AWS APN Ambassador, and focuses on evolving solution architectures and Well-Architected Framework outcomes. Prior to joining MYCOM OSI, he held wireless engineering roles at Star21, AOL, Bechtel Telecommunications, and Nortel Networks. He holds an MSc in geoinformatics.