AWS for Industries
Cromwell on AWS: A simpler and improved AWS Batch backend
The latest release of Cromwell (v52) includes a number of major changes and improvements to the AWS Batch backend for Cromwell. Among the numerous changes, we have enabled Cromwell’s Call Caching feature when using AWS Batch with files in Amazon Simple Storage Service (Amazon S3). This allows genomics researchers to efficiently develop and run workflows by reusing previously computed results from computationally expensive tasks. This has been one of the most frequently requested upgrades to the AWS backend and it helps customers better realize the potential of a fully elastic work-scheduler for their genomics workflows. The changes we have made have been contributed back to the Cromwell community code base, meaning all Cromwell users now have these features available to them. You can deploy this solution into your own AWS account right now by following these instructions.
These improvements were developed to meet the needs of customers such as the Fred Hutchinson Cancer Research Center. Throughout the development process, Fred Hutch helped test new features and provided invaluable input and feedback. Fred Hutch researcher Amy Paguirigan said, “We are seeing a drastic improvement in our ability to rapidly move from testing to production work by being able to ‘burst’ to AWS Batch at any time without having to re-write workflows or tasks with the specific backend in mind. Improvements in call caching and output copying among other improvements have made Cromwell with AWS Batch an excellent match for our biomedical workflows.”
To improve scalability, we moved away from a one-to-one mapping from Batch Job Definitions to Cromwell tasks, to a strategy that allows increased re-use of Job Definitions. In this new model, most of the detail of what happens in an AWS Batch job (a Cromwell task) is defined in a shell script that is written by the Cromwell server to Amazon S3. The AWS Batch container responsible for running the task fetches this definition from Amazon S3 and runs it. Tasks in containers are now fully isolated and self-sufficient with no possibility of concurrent (scattered) tasks modifying each others’ inputs or outputs. The new approach has also removed the need for a custom Amazon ECS agent in the cluster’s Amazon Elastic Compute Cloud (Amazon EC2) instances. This allows customers workloads to use the latest Amazon ECS Optimized AMIs and thus use the latest version of the ecs-agent. Because we no longer require a specific AMI, customers can also bring their own custom AMIs. All Amazon EC2 instance dependencies are now all installed using “user data” in a Launch Template. Ultimately, the strategy makes the job definitions that Cromwell creates reusable, requiring fewer API requests, and is thus more scalable.
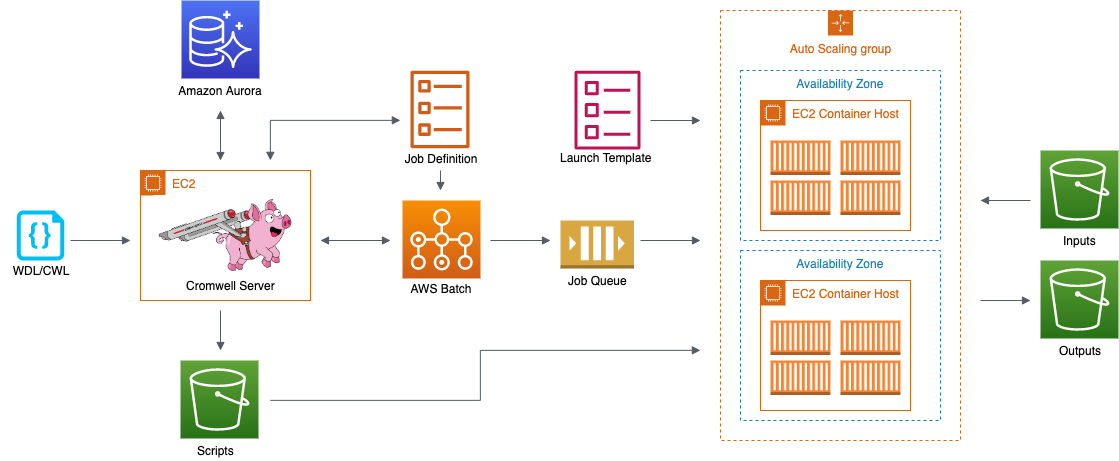
Call caching in Cromwell is the ability to avoid recomputing results that have been generated previously as part of a successful or partially successful workflow. This is especially desirable when a computation is long running. With the new backend, when the Cromwell server detects a “cache hit,” it will direct Amazon S3 to copy the prior result into the path of the new workflow.
Large files are always a challenge in genomics and in our first version of the backend, we included an Amazon Elastic Block Store (Amazon EBS) automatic scaling script. The script allowed EC2 instances in the Batch cluster to automatically mount new Amazon EBS volumes as file sizes grew. Amazon EC2 instances hosting multiple containers where each container can be localizing (or producing) large files mean this process needs to respond rapidly and reliably to ensure disk space is always adequate. In our latest update, we have made this process much more resilient to failure via a number of enhancements to the Amazon EBS automatic scaling script.
In addition, we developed a companion set of AWS CloudFormation templates with the goal of defining a production ready infrastructure to be used by Cromwell. The infrastructure provisioned by AWS CloudFormation also provides the supporting scripts and integrates them with AWS CodePipeline allowing customers to have full control of these scripts in a CI/CD environment. Call caching requires a persistent relational database to store the runs metadata. The supporting infrastructure provides this as an Amazon Aurora MySQL cluster. Server and container logs are fed to Amazon CloudWatch. CloudWatch container insights can be enabled to provide information about cluster and container utilization that helps with allocating the correct amount of resources. The templates also provide all of the IAM policies, roles and Amazon EC2 security groups necessary to fully secure the service while enabling the various components to communicate.
The full Cromwell code base, including the AWS Batch backend, is an open-source project available on GitHub and coordinated by the Broad Institute. The Cromwell development team provided a great deal of valuable feedback and advice in support of this work, and we strongly encourage others to become involved in this community effort to advance genomics research.