AWS for Industries
Part 1: Introducing Amazon Omics—from sequence data to insights, securely and at scale
This is the first installation of a two-part series detailing the launch of Amazon Omics. The second installation provides deeper technical details.
We are excited to launch the general availability of Amazon Omics–a purpose-built service that will help bioinformaticians, researchers, and scientists store, query, analyze, and generate insights from genomic, transcriptomic, and other omics data.
Our life sciences customers want to accelerate drug discovery and development to create cures for patients. Our healthcare customers want to transform care by identifying the best treatment or prevention for their patients. A great example is how genomic data is being leveraged to profile individual patients’ tumors or circulating markers in blood to help clinicians make decisions at the point of care. This has generated a fourfold increase in personalized treatment options for cancer patients over the past decade. Work done by Stanford, Philips, Roche, and Genomics England further demonstrates the benefits of facilitating more personalized insights and developing a more holistic view of a patient or area of research.
The era of precision medicine
We’re approaching an inflection point in health to provide highly personalized and precisely targeted diagnostics and treatments to people, known as precision medicine. The development of precision medicine is fueled by:
- Digitalization and sharing of medical data with over 98% of medical records in digital form
- Steep decline in the cost of sequencing with a 100,000-fold reduction in cost since the human genome was first sequenced in 2001, reaching an all-time low of approximately $200
- Growth of cloud computing across healthcare and life sciences
It’s not just DNA sequences, but also RNA and protein sequences that are more easily measured than ever. This explosion of omics data, such as genomic, transcriptomic, and proteomic data, is driving a new understanding of biology at the molecular level. For example, advances in newer and more accurate sequencing techniques, such as next generation sequencing for characterizing complex areas of the genome are accelerating the growth of omics data with a 2.5-fold increase in daily throughput. The combination of clinical and omics information is being used in drug discovery, vaccine development, and to predict an individual’s genetic predisposition to disease—delivering more personalized treatments across therapeutic areas like cancer, infectious diseases, and rare diseases.
The explosion of data about the biology of disease has far outpaced human ability to consume and understand it. This is a major challenge for scientists and clinicians who are working to translate omics data into new treatments and diagnostics for patients. The size, rapid accumulation, complexity, and heterogeneity of omics data pose difficulties for our customers in tapping them with existing tools and systems. This data also creates challenges in privacy, security, data ownership and stewardship, governance, and fairness.
Customers must efficiently store, index, and secure petabytes of raw sequence data. Next, they must provision, manage, and operate the compute infrastructure required to process this data into analytics and interoperability-ready formats with reproducible and scalable pipelines. As part of their analysis workflow, customers often need to combine an individual’s genome data with other data such as their medical records or reference genome datasets, which requires significant manual data processing. This data processing consumes engineering resources and is error-prone and hard to implement for omics data at petabyte scale.
Introducing Amazon Omics
 With Amazon Omics, you can devote more time to science and improving health while knowing that the underlying service supports your security and compliance posture (learn more about AWS’ healthcare and life sciences compliance.) Amazon Omics supports large-scale analysis and collaborative research, without customers needing to worry about provisioning the underlying infrastructure. It enables customers to reduce time spent on setting up and running complex Extract-Transform-Load (ETL) pipelines by natively storing data in optimized query-ready formats (for example, Apache Parquet) with just a few API calls.
With Amazon Omics, you can devote more time to science and improving health while knowing that the underlying service supports your security and compliance posture (learn more about AWS’ healthcare and life sciences compliance.) Amazon Omics supports large-scale analysis and collaborative research, without customers needing to worry about provisioning the underlying infrastructure. It enables customers to reduce time spent on setting up and running complex Extract-Transform-Load (ETL) pipelines by natively storing data in optimized query-ready formats (for example, Apache Parquet) with just a few API calls.
Customers can bring their own bioinformatics workflows and Amazon Omics manages the infrastructure to run it. This further reduces undifferentiated heavy lifting, enables customers to operate in a secure environment with built-in access control, logging and audit trails, while still complying with HIPAA, GDPR, and other regulations.
A great example of this is how organizations like Children’s Hospital of Philadelphia, G42 Healthcare, and C2i are already using Amazon Omics to power their omics workflows.
“Amazon Omics allows G42 to accelerate a competitive and deployable end-to-end service with globally leading data governance. We’re able to leverage the extensive omics data management and bioinformatics solutions hosted globally on AWS, at our customers’ fingertips. Our collaboration with AWS is much more than data – it’s about value.”
—Ashish Koshy, CEO, G42 Healthcare
“In C2i Genomics, we empower our data scientists by providing them cloud-based computational solutions to run high-scale, customizable genomic pipelines, allowing them to focus on method development and clinical performance, while the company’s engineering teams are responsible for the operations, security and privacy aspects of the workloads. Amazon Omics allows researchers to use tools and languages from their own domain, and considerably reduces the engineering maintenance effort while taking care of cost and resource allocation considerations, which in turn reduce time-to-market and NRE costs of new features and algorithmic improvements.”
—Ury Alon, VP Engineering, C2i Genomics
Amazon Omics also lets you import and easily combine your own data with other publicly available reference datasets in the Registry of Open Data on AWS, such as the 1000 Genomes Project that can be used as a control to understand disease risk; the Genome Aggregation Database (gnomAD) to bring in population allele frequencies to unlock the door to disease detection; and more than 60 other genomic datasets.
Amazon Omics provides customers with three components (Figure 1). The first component is Omics-aware object storage to store, discover, and share raw sequence data efficiently, securely, and at low cost. The second component is Omics Workflows, which allows customers to run reproducible bioinformatics workflows to process raw sequence data at scale either in the Omics Storage or in S3, removing all the undifferentiated heavy lifting associated with running these workflows. And the third component is Omics Analytics, which simplifies analytics through query-ready variants (or mutations) and annotations. While these components will often be used together, customers can also leverage them in a standalone manner. We cover each of these components in detail in the sections below.
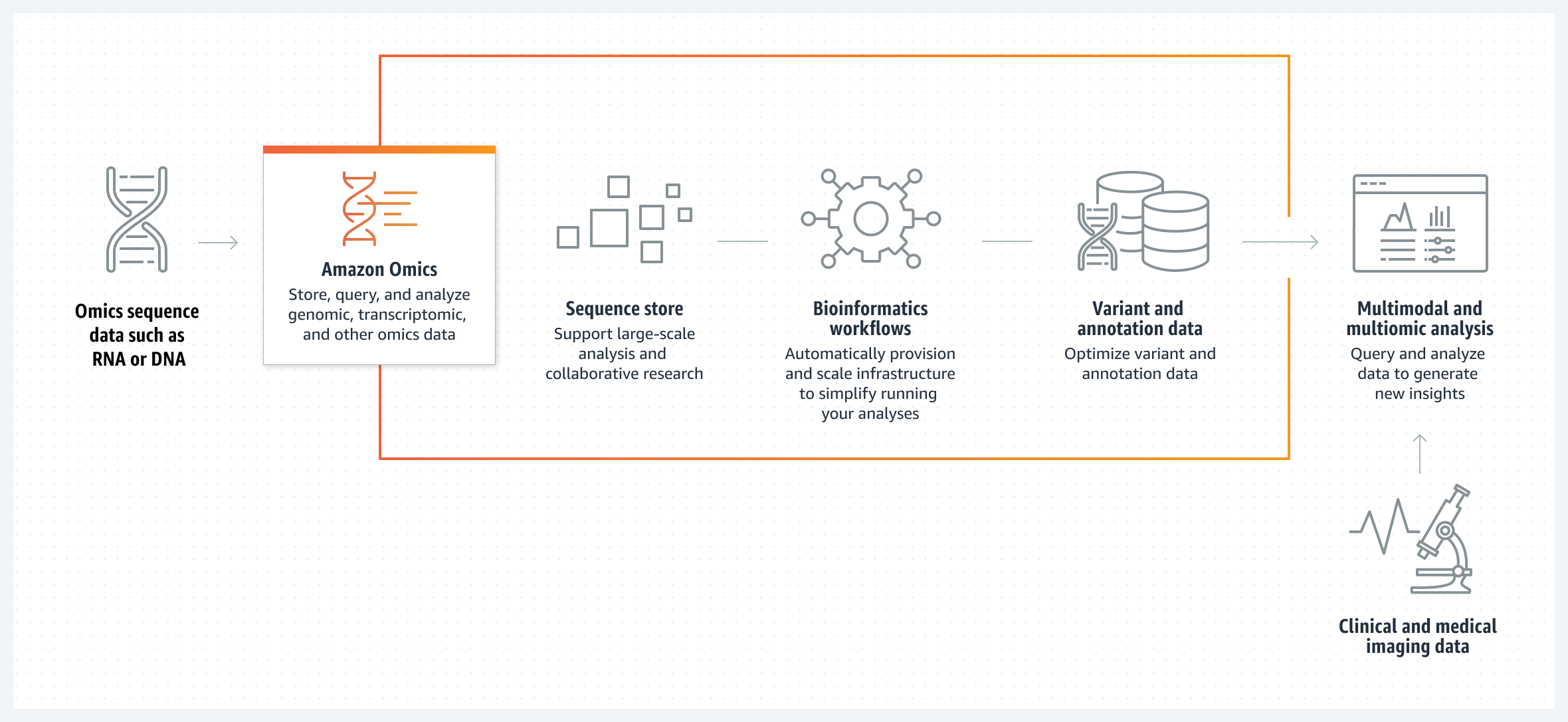
Figure 1. Amazon Omics: How it works across storage, workflows, and analytics
Cost-effective, omics-aware object storage
Amazon Omics provides a cost-effective, omics-aware storage option for reference and sequence data, that can reduce the Total Cost of Ownership (TCO) for storing raw sequence data (for example, BAMs, CRAMs, FASTQs). It also facilitates data sharing and governance through a combination of attribute-based access control and domain-specific searchable metadata.
There are two storage classes within Amazon Omics: active, for data that is readily accessed, and archive, for low-cost, long-term archival of omics data. Auto-archival is on by default, meaning that Amazon Omics will automatically move data to the cheaper storage class if they are not regularly accessed (for more than 30 days), similar to the Amazon Simple Storage Service (Amazon S3) Intelligent-Tiering storage class, leading to cost savings for customers.
Importantly, since all sequencing instruments are rated in gigabases per run (for example, a human genome contains three billion bases or three gigabases), where customers typically design their clinical panels in gigabases per test, we designed Amazon Omics storage to be domain-specific per number of gigabases ingested. This ensures optimal storage of raw sequencing data at scale, which can reach hundreds of thousands of genomes per year. Further, it gives customers the flexibility to pick any sequencing platform or technology (for example, short reads or long reads), and price predictability without worrying about variability of storage costs across sequencing platforms.
Scalable compute to run reproducible workflows
Amazon Omics provides managed compute resources to run reproducible bioinformatics workflows, which contain scripts of a series of coordinated tasks to distill large amounts of raw sequence data, from Amazon Omics storage or Amazon S3, to small amounts of analytic data (such as genome mutations, known as variants, or gene expression counts). In turn, this removes all the undifferentiated heavy lifting associated with running and managing these workflows at scale.
Customers can run scripts written in a variety of bioinformatics workflow languages, such as Nextflow or Workflow Description Language (WDL), and corresponding Docker images. Customers then specify the compute resources (vCPUs and memory) needed for each task. Amazon Omics manages the scheduling and provisioning of resources to run the workflow, manages retries, and provisions shared file systems.
Amazon Omics allows customers to define Run Groups to limit the maximum concurrent runs for a specific workflow and user, enabling customers to manage costs and track multiple projects. Run metrics and logs are accessible through Amazon Cloud Watch or the Amazon Omics Console. Amazon Omics also enables tracking of provenance and lineage of data by keeping track of which workflow was run for a given input, and the outputs that were generated from that run.
Simplifying analytics through query-ready variants and annotations
The output of DNA sequencing analysis are raw genomic variants in the form of Variant Call Files (VCF) and Genomic Variant Call Files (gVCF). Customers want to query these variants and identify their clinical significance by assigning meaning to them through annotations (for example, identifying a variant that results in a faulty gene which produces a cancer-causing protein). These text-based VCF, however, are not optimized for querying given their semi-structured nature. While genomes may be analyzed on an individual level, many customers are looking at querying thousands of variants (if not more) across many genes at once to understand how genomic variation, joined with corresponding clinical data, may affect human health or predict clinical outcomes.
Amazon Omics addresses these challenges by enabling customers to import their VCF into a Variant Store and seamlessly transform them into a query-ready schema that is available as an Apache Iceberg Table. It also supports the import of variant annotations into an Annotation Store. Customers can govern access through AWS Lake Formation and apply fine-grained access control to filter out individual patients. This helps define custom patient cohorts and manage patient consent for compliance regimes, like GDPR, without having to copy the data. This also enables query and analysis of these variants using Amazon Athena and to join data from other modalities, such as clinical data in Amazon HealthLake or in the customer’s AWS Glue Data Catalog.
Amazon QuickSight can be used as a visual interface to define a cohort of patients based on various attributes, such as a particular mutation or clinical observations in Amazon HealthLake. Amazon SageMaker can be used to build and deploy many machine learning models on this cohort, quickly and efficiently, for AI-driven predictions such as a patient’s disease risk or overall effectiveness of a particular drug.
Accelerating with AWS Partners
AWS Partner solutions and services can help customers leverage Amazon Omics to build scalable, multi-modal solutions for genomic, transcriptomic, and other omics data. AWS Partner, Lifebit, is on a mission to connect the world’s biomedical data for novel therapeutic insights. With Amazon Omics, Lifebit will be able to provide even more scalable bioinformatics solutions, providing access to optimized analytics and storage for large-scale data.
For other AWS Partners such as Ovation, using the Amazon Omics variant store helps researchers get access to their genomics data faster and at scale.
Learn more about Amazon Omics Partners.
Conclusion
Together with our customers and partners, we have a great opportunity to enable researchers, data scientists, and clinicians to target diseases and improve human health with more precise therapy, modernizing care for generations to come with purpose-built capabilities. Amazon Omics enables end-to-end omics storage, processing, and analysis by removing the need for organizations to setup and maintain specialized tools, workflows, and infrastructure. By natively integrating with analytics services like AWS Lake Formation and Amazon Athena, Amazon Omics enables customers to maintain management and governance over their omics data that is part of their multi-modal data lake. With a few API calls, customers can deploy a reproducible, production-grade infrastructure to accelerate innovation and time to derive medical insights. In part two of this blog, we present a reference architecture to do this.
You can get started with the Amazon Omics documentation or learn more on our webpage.