Artificial Intelligence
Defect detection and classification in manufacturing using Amazon Lookout for Vision and Amazon Rekognition Custom Labels
Defect detection during manufacturing processes is a vital step to ensure product quality. The timely detection of faults or defects and taking appropriate actions are essential to reduce operational and quality-related costs. According to Aberdeen’s research, “Many organizations will have true quality-related costs as high as 15 to 20 percent of sales revenue.”
The current method of either in-line or end-of-line manual checks is a time-consuming and expensive task. You require trained human experts to perform visual inspections. As a result, the feedback loop is slower and can cause production bottlenecks and impact market timelines. Furthermore, the process is subjective and costly to scale effectively.
A robust, effective, and scalable anomaly detection mechanism is required to provide objective decisions on visual inspection with a quick feedback loop and at low cost to maximize the quality of manufactured goods. In this post, we provide an automated inspection workflow for pinpointing types of defects, which can enable plant operators to take targeted product disposition and process control decisions.
Solution overview
In the post Amazon Lookout for Vision – New ML Service Simplifies Defect Detection for Manufacturing, we used Amazon Lookout for Vision to provide a binary classification of a product as normal or anomalous. In this post, you learn to identify the type of defects using a combination of Lookout for Vision and Amazon Rekognition Custom Labels. For example, in a manufacturing line of a printed circuit board, several types of defects can be introduced, including damaged boards, bent pins, solder defects, and scratches. This ability to provide a multi-classification of defects gives plant operators a granular view of the types of defects occurring during the production process. In turn, the plant operators can take precise corrective actions to fix the issues contributing to these anomalies. We also demonstrate the following:
- Augmentation techniques to increase the number of images used for training and improve results
- Using Lookout for Vision for manufacturing defect detection followed by Amazon Rekognition Custom Labels for defect classification provides better results than just using Amazon Rekognition Custom Labels
With Lookout for Vision and Amazon Rekognition Custom Labels, you don’t need expertise in machine learning. All you need is a training dataset to get started.
The workflow uses a combination of Lookout for Vision to detect defects and Amazon Rekognition Custom Labels for multi-label classification of defects, as shown in the following diagram.

Initial dataset
We use the printed circuit board dataset to demonstrate the solution. This dataset contains normal and anomalous images.
The following image shows a normal circuit board.

The following image shows a circuit board with a bent pin.

The following image shows a damaged circuit board with missing components

The following image shows a circuit board with scratches.

The following image shows a circuit board with a soldering defect.

We have reorganized the original circuit board dataset to meet the needs of this use case. Download the amazon-lookout-for-vision-rekognition-multiclassification zip package and unzip it. This folder contains all the datasets, code files, and instruction sets relevant to this post.
In this post, we walk you through the following steps:
- Train the models with Lookout for Vision for anomaly detection.
- Train the models with Amazon Rekognition Custom Labels for defect classification.
- Show data augmentation techniques to increase the number and diversity of training datasets and improve Amazon Rekognition Custom Labels model performance.
- Demonstrate that using the combination of Lookout for Vision and Amazon Rekognition Custom Labels has better model performance for manufacturing defect detection and classification than using just Amazon Rekognition Custom Labels.
Lookout for Vision model training
We start by training the model in Lookout for Vision to learn the differences between normal and anomalous circuit board images. We use the dataset in the circuitboard-lkv folder of the downloaded .zip package. This folder contains train and test datasets for normal and anomalous images. There are 60 train and 20 test images for training the Lookout for Vision Model. The steps for training the model as follows:
- Prepare the images for the dataset.
- Create a project.
- Create a dataset from images in an Amazon Simple Storage Service (Amazon S3) bucket.
- Train your model.
You can find specific steps for training the Lookout for Vision Model for the circuitboard-lkv dataset in the Amazon Lookout for Vision Model Training PDF located in the downloaded zip package.
When the training is complete, you can see the performance metrics of the test images against the trained model.


You can review the following model performance metrics:
- Precision – The number of defects that were correctly predicted out of the total predictions
- Recall – The number of defects that were correctly predicted out of the total number of defects
- F1 score – The average of precision and recall
In this case, the model quality is excellent, with 10 out of 10 defects correctly predicted for a recall score of 1.0, a precision score of 0.909 with 1 false positive, and an overall F1 score of 0.952. You can directionally improve model performance by adding more images to your training dataset.
Amazon Rekognition Custom Labels model training
In this section, we use Amazon Rekognition Custom Labels multi-label classification to train the model on different types of defects for circuit boards such as solder defects, bent pins, damaged boards, and scratches using the dataset in the circuitboard-rekcl-default folder of the zip package. The circuitboard-rekcl-default folder contains the train and test dataset for Amazon Rekognition Custom Labels model training. The anomalous images are divided into folders of their custom labels: bent pins, damaged board, scratch, and solder defect. This is a challenging training dataset with a low number of images for each of the custom labels: 2 bent pins, 3 damaged boards, 3 scratches, and 25 solder defects. To train the model with this dataset, complete the following steps:
- Prepare the images for the dataset.
- Create a project.
- Create a dataset from images in an S3 bucket.
- Train the model.
You can find specific steps for training the Amazon Rekognition Custom Labels Model for the dataset circuitboard-rekcl-default in the Amazon Rekognition Custom Labels Model Training PDF located in the .zip package.
The following screenshot shows the model training results. The key metrics are F1 score, precision, and recall. A score closer to 1.0 indicates good model performance during inference. The overall F1 score here is 0.725. Some custom labels like solder defect and damaged board have better F1 scores than other labels.

The number of training images are low—2 bent pins, 3 damaged boards, 3 scratches, and 25 solder defects. In the next section, we use data augmentation techniques to increase the amount of training images and their diversity to improve model performance.
Data augmentation
We can use data augmentation to increase the number of anomaly training images. A key best practice is to increase the number and diversity of the training dataset. The test dataset shouldn’t contain any augmented images.
Our training dataset is a good candidate for augmentation. It has a low number of images for multi-label classification with Amazon Rekognition Custom Labels. You can perform the data augmentation in an Amazon SageMaker Jupyter notebook using the Keras API available with TensorFlow 2. Use the following code to set up the parameter ranges for data augmentation:
Next, to generate the desired number of augmented images per original training image, use the following code snippet:
The Jupyter notebook with the full code to perform data augmentation on the training images is called Augmentation.ipynb and is located in the zip package.
The following are some sample outputs of anomalous circuit board images before and after data augmentation. You can observe the differences in the original image and the augmented image with multiple changes like rotation, shear, and zoom.
The following image shows a damaged circuit board with missing components.

The following shows an augmented image of the damaged circuit board with a slight rotation

The following image shows a circuit board with scratches.

The following image shows a zoomed in augmented image of a circuit board with scratches

You can find the dataset with the augmented images in the circuitboard-rekcl-augmented folder of the .zip package. The training images for different defect labels has gone up to 32 bent pins, 48 damaged boards, 48 scratches, and 50 solder defects. The number of images in the test dataset remains the same.
With this new augmented training dataset, repeat the Amazon Rekognition Custom Labels model training following the same steps shown in the previous section.
The results of training the model using the augmented dataset are shown in the following screenshot.

The overall F1 score of the model using the augmented training dataset has improved from 0.725 to 0.831. You can observe precision scores of 1.0 for multiple labels. This demonstrates that data augmentation improved the performance of the Amazon Rekognition Custom Labels model.
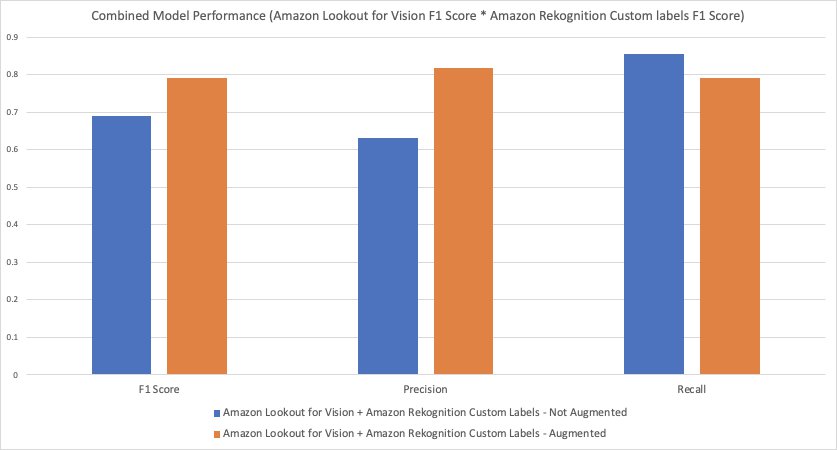
The following chart highlights the performance of the three models we have trained so far.

In the following graph, we can see that the combination of the Lookout for Vision model with the Amazon Rekognition Custom Labels model with the augmented dataset resulted in better model performance compared to the non-augmented dataset.
The combined F1 score is obtained by multiplying the individual F1 scores of the Lookout for Vision and Amazon Rekognition Custom Labels models.
For example:
- Lookout for Vision F1 score = 0.952
- Amazon Rekognition Custom Labels F1 score – Not Augmented = 0.725
- Combined F1 score = 0.952 x 0.725 = 0.69
Amazon Rekognition Custom Labels standalone model performance
In this section, we look at the performance of a standalone Amazon Rekognition Custom Labels model performance.
We train two Amazon Rekognition Custom Labels models using datasets (augmented and not augmented) located in the circuitboard-rekcl-only folder of the .zip package provided initially. This folder contains three datasets: rekcl_only_train_default, rekcl_only_train_augmented, and rekcl_only_test. Each of these folders contains an additional folder with normal images of the circuit board along with the individual defects folders. We use the test folder with both the augmented and non-augmented datasets for each model.
Repeat the steps earlier to train two models with the augmented and non-augmented datasets.
The following screenshot shows the model performance of the non-augmented dataset using Amazon Rekognition Custom Labels only.
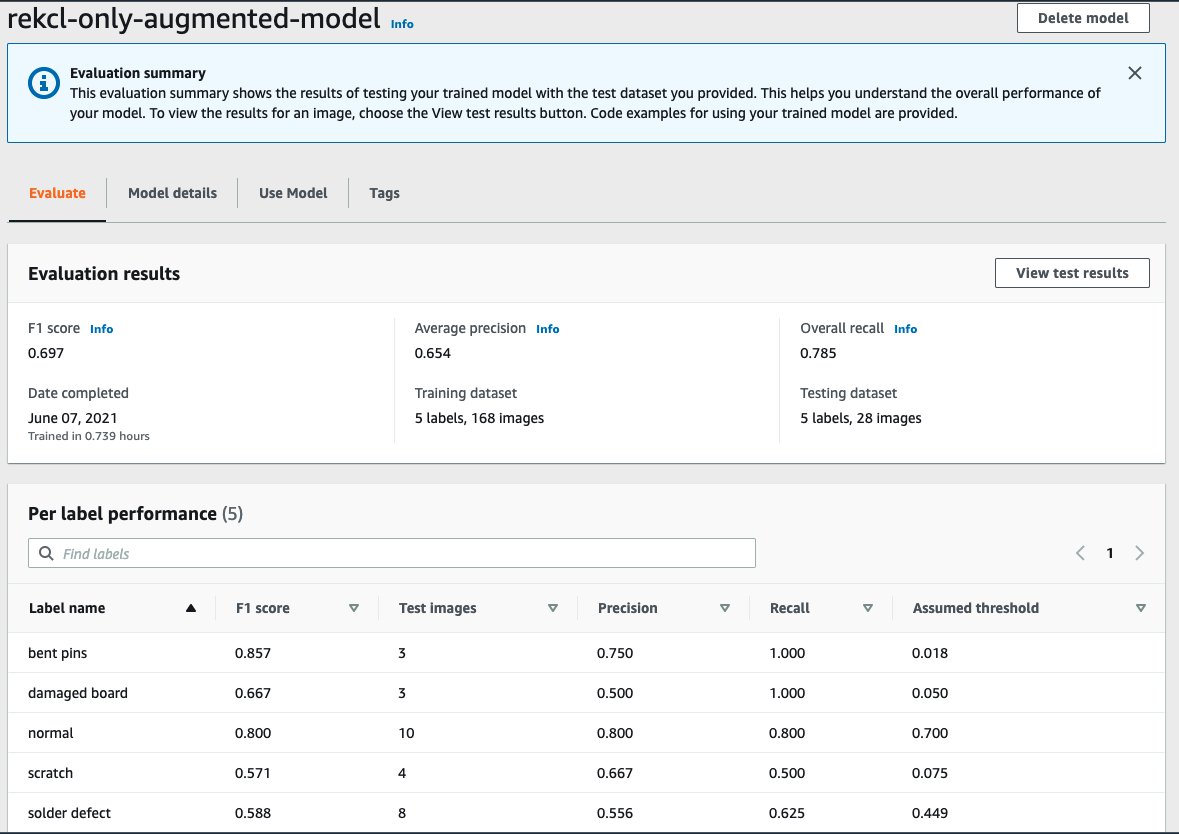
The following screenshot shows the model performance of the augmented dataset using Amazon Rekognition Custom Labels only.

When we compare the F1 scores of the two Amazon Rekognition Custom Labels standalone models with the F1 scores of the earlier models, we see that using a combination of Lookout for Vision with Amazon Rekognition Custom Labels for manufacturing detection and classification gives better model performance. The following chart highlights this conclusion.

Conclusion
With Lookout for Vision, we can automate the detection of defective products in industrial and manufacturing processes. By adding Amazon Rekognition Custom Labels to the workflow, we can further reduce costs and resource overheads by automating the identification of the specific defects. This multi-classification of defects gives plant operators a granular view of the types of defects occurring during the production process. In turn, the plant operators can take precise corrective actions to fix the issues contributing to these anomalies. This results in higher efficiency in manufacturing lines and improves the business outcomes of customers.
Start your journey towards industrial anomaly detection and identification by visiting the Lookout for Vision and the Amazon Rekognition Custom Labels resource pages.
About the Authors
 Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helps customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel and trying out different cuisines.
Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helps customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel and trying out different cuisines.
 Amit Gupta is an AI Services Solutions Architect at AWS. He is passionate about enabling customers with well-architected machine learning solutions at scale.
Amit Gupta is an AI Services Solutions Architect at AWS. He is passionate about enabling customers with well-architected machine learning solutions at scale.