AWS Cloud Operations Blog
Understanding AWS Systems Manager Inventory Metadata
In July of 2017, we posted an entry on this blog about how to use AWS Systems Manager, Amazon S3, Amazon Athena, and Amazon QuickSight to gather inventory metadata from managed EC2 instances and aggregate it for the purpose of centralized reporting and visualization of the data. When determining how to report on this data, it’s important to understand how the data is structured in the Amazon S3 bucket and where the data comes from. This information can help you decide how to use our services to report on and visualize the collected inventory data.
When you create the Resource Data Sync in the Systems Manager console, you specify a Bucket Name and optionally a Bucket Prefix. Within that Amazon S3 bucket and prefix, you will see a prefix for each inventory plug-in that has gathered data and has been synchronized to the bucket via the Resource Data Sync as shown in the following list:

Where does this data come from?
In the following table, the first column lists each of the AWS Systems Manager Inventory plug-ins. Each subsequent column contains groupings of actions that can cause inventory data to be generated. This table helps you identify which actions trigger which plug-ins that create the data that gets pushed to the S3 bucket:
| Inventory Plug-in | Register new, gracefully terminate, or update the AWS Systems Manager Agent | Patch Baseline Operations (AWS-RunPatchBaseline, AWS-ApplyPatchBaseline) | AWS-GatherSoftwareInventory (Linux) | AWS-GatherSoftwareInventory (Windows) |
| AWS:InstanceInformation | ||||
| AWS:Tag | ||||
| AWS:ComplianceItem | ||||
| AWS:ComplianceSummary | ||||
| AWS:PatchSummary | ||||
| AWS:AWSComponent | ||||
| AWS:Application | ||||
| AWS:File | ||||
| AWS:InstanceDetailedInformation | ||||
| AWS:Network | ||||
| AWS:WindowsRegistry | ||||
| AWS:WindowsRole | ||||
| AWS:WindowsUpdate | ||||
| Custom:<InventoryName> |
The AWS:Tag plug-in is triggered by one additional action that is not listed on the table. The AWS Systems Manager Agent periodically goes through a process called tag expansion on instances. When this happens, the AWS:Tag data is gathered and will synchronize to Amazon S3 using the Resource Data Sync.
When is this data collected?
You need to understand which services in AWS Systems Manager are used to gather this data. This is because each service works differently, so there might be a variation in collection times. Let’s start by looking at the document AWS-GatherSoftwareInventory.
The AWS-GatherSoftwareInventory policy document must be applied as an association by AWS Systems Manager State Manager. There are several situations where an association will run outside of the scheduled time:
- The association is applied at the time of creation.
- The association is applied when the association has been edited.
- The association is applied as soon as a targeted instance becomes available after being unavailable at the time of creation or the last application of the association.
- The association is applied if a user calls the AWS-RefreshAssociation document and targets an instance that is part of an association.
- The association is created using a rate expression instead of a cron expression. In these situations, the association applies at the interval specified in the rate expression based on the time of last application rather than the time of creation.
Due to the sensitive nature of patching operating systems, it’s common to run AWS-RunPatchBaseline and AWS-ApplyPatchBaseline through the use of AWS Systems Manager Maintenance Windows. In this situation, the registered tasks in the Maintenance Window will be run at the time scheduled in the cron expression or at the interval specified by the rate expression. These tasks will run as scheduled and won’t apply to instances that are offline at the time of the maintenance window.
File structure in S3 bucket
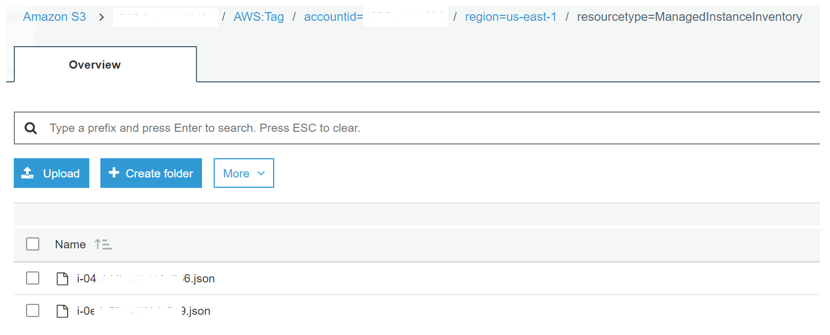
Within each of the Inventory plug-in prefixes, there will be a prefix for each account that is using Resource Data Sync with this S3 bucket. This is followed by a prefix for each Region that is reporting inventory, and then a prefix for the resource type, which will generally be ManagedInstanceInventory. Then within that prefix, there will be a JSON file for each instance that reports Inventory data. The following is an example of this structure:

Summary
Knowing when this data is gathered should help you make decisions about how you will report on it once you ingest it into Amazon Athena and Amazon QuickSight. For example, if you are reporting on the capturetime field for each JSON file, it’s helpful to understand why the value from AWS:InstanceInformation might not align with values in AWS:PatchSummary and AWS:Network. Each of these plug-ins are triggered by different events and even different services, which leads to the disparity in capture time for the data.
About the Author
 Dan Hammel is a Cloud Support Team Lead in AWS Premium Support. He specializes in Amazon EC2 Windows, AWS Systems Manager, and Microsoft PowerShell. Outside of AWS, he has a passion for cooking, enjoys a wide variety of music, and has been writing the first 15 pages of a novel for over a decade.
Dan Hammel is a Cloud Support Team Lead in AWS Premium Support. He specializes in Amazon EC2 Windows, AWS Systems Manager, and Microsoft PowerShell. Outside of AWS, he has a passion for cooking, enjoys a wide variety of music, and has been writing the first 15 pages of a novel for over a decade.