AWS Open Source Blog
Building a series deletion API in Cortex
In this post, Ilan Gofman, an intern on the Amazon Managed Service for Prometheus team, shares his experience of designing and implementing the series deletion feature inside of the Cortex open source project. This new API will provide the ability to delete series from Cortex using the blocks storage engine. This blog post details the work done as part of an internship project. The feature is still under review and not yet available in Cortex.
Cortex is a distributed system that allows for a horizontally scalable, highly available, and long-term storage solution for Prometheus metrics. It is a Cloud Native Computing Foundation (CNCF) incubation project with an open source community working to continuously improve and make the software better for its users. Using Cortex, Amazon Managed Services for Prometheus (AMP) aims to provide its customers with a Prometheus-compatible monitoring service that simplifies the process of monitoring containerized applications at scale.
Currently, Cortex provides a tenant deletion API, which allows the full deletion of a user; however, this feature is limited to deleting all the series and samples of a user and does not offer selective deletion. Having the ability to delete specific samples will allow for a few use cases that are currently not actionable in Cortex. In this article, I’ll describe the design and implementation of a new series deletion feature inside the open source Cortex project.
Background
Customers have mentioned that they need a way to delete confidential and PII information that may have been accidentally pushed as metrics. Furthermore, high-cardinality dimensions may need to be deleted if they are causing inefficient queries. Without a deletion API, customers would be stuck with the personal identifiable information (PII) security risk or with slow queries.
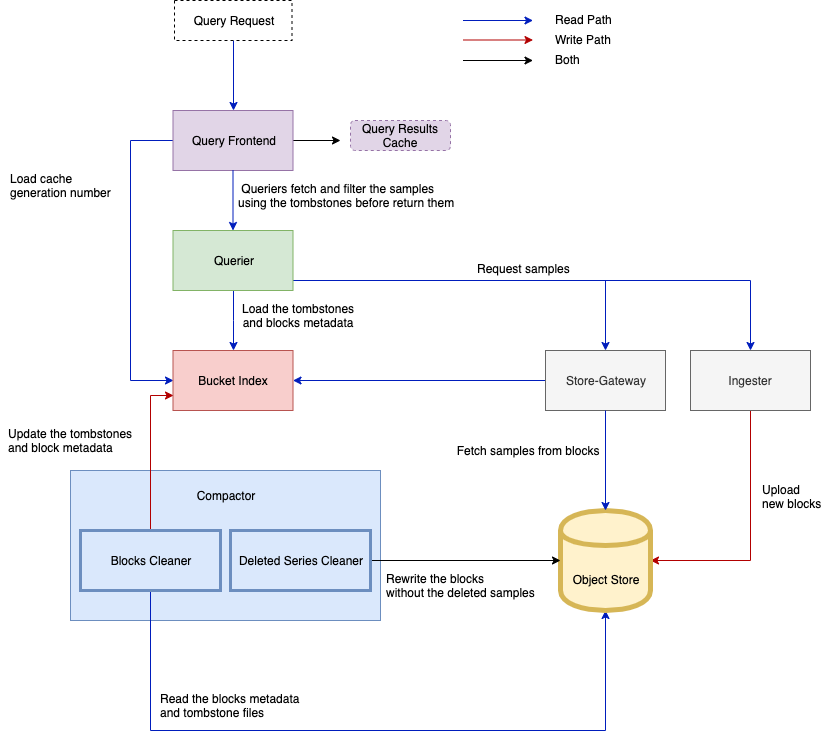
To better understand how the series deletion API is designed, it is helpful to know how the metrics are written to and retrieved from Cortex. Learning how the Cortex system is designed to handle data will allow for a better understanding of where the data exists and which components need to have samples deleted from. If you already know how Cortex works, you can skip to the API requirements section.
How metrics are collected in Cortex
Metrics are originally collected in Cortex using a Prometheus-compatible agent, such as a Prometheus server, AWS Distro for OpenTelemetry, or Grafana agent. Using Prometheus’s remote write API, the metrics are sent to Cortex. The incoming samples are first sent to the distributor service, which validates the correctness of the incoming samples.
The distributor then selects an ingester and sends the samples to it in batches. The ingester stores the recent data received from the distributors. Next, the ingester groups together all the samples for a particular tenant and creates a block of data, which is then uploaded to the long-term object storage. By default, the blocks are written from the ingester to the object storage, with each block containing two hours worth of samples.
After the blocks have been uploaded to the object storage, the compactor service merges and deduplicates the existing blocks to minimize the total number of blocks. By reducing the number of blocks, this step enables for more efficient queries. The compactor reduces the number of blocks by combining several smaller blocks into one larger block that contains the collection of samples from all blocks. Using the default configuration in Cortex, the compactor will merge multiple two-hour blocks into a single 12-hour block. This process is later repeated to combine the 12-hour blocks into a single, more optimized 24-hour block.
Additionally, inside the compactor the blocks-cleaner service periodically scans the storage bucket and updates the bucket-index accordingly. The bucket-index is a per-tenant file containing the metadata about all the blocks that are available for querying in the object store. After a new block has been added by the ingester or through the compaction of older blocks, the bucket-index is periodically updated with a new list of all available blocks.
How metrics are retrieved from Cortex
When a query is made to retrieve samples from Cortex, the request goes to either the querier service or the query front end if it is enabled. The query front end allows for greater optimization by splitting the incoming query among multiple queriers and then aggregating the querier responses. The query front end can cache the results for quicker retrieval during future requests.
The querier service receives requests made using PromQL and returns the relevant samples. Because the samples can be stored in both the ingesters and the long-term object storage, the results must be fetched from both. To know which blocks to query from the object store, the queriers read the bucket-index file for all the available blocks. Once the required blocks have been identified, the queriers use the store-gateway service to retrieve the samples from the object store.
API requirements
When deleting time series data, it is critical that the deleted data not reappear in any queries once the user expects it to be deleted. One challenge of implementing the time series deletion API is that time series data exists in multiple Cortex services. When the deletion request is received, the time series data is present in at least one of following:
- Object store for long-term storage of blocks.
- Ingesters containing the recently pushed data. This is eventually transferred to the object store.
- Compactors in the midst of processing blocks for greater compaction.
- The store-gateway and bucket index might contain block metadata that have data requested for deletion. These determine which blocks the queriers read from.
- Various cached data such as the query front end results cache.
Having data in many places allows the Cortex system to work efficiently and return queries fast; however, it also makes deleting data more difficult because it could exist in various services.
Design and implementation
To facilitate deletions, a deletion lifecycle was created outlining the three possible states that a particular request can take.
- When a request is made for deletion, the initial state of the request is Pending. A tombstone file is created in the object store outlining the deletion information. Afterwards, queriers use the tombstones to perform query time filtering to remove any of the to-be-deleted data. There is a cancellation period in which users can cancel any pending request, before any data has been deleted. Once the cancellation period is over, however, the data is processed for permanent deletion and the decision cannot be reversed.
- Once all the time series data relevant to a request has been deleted, the state of the request becomes Processed. Now the data requested for deletion no longer exists in the object storage. For a short time after the data has been deleted, query time filtering is still required until the queriers load the updated bucket-index containing new blocks without the deleted data.
- The last state is Deleted and occurs if the request is cancelled before the cancellation grace period has passed.
- Each tombstone is stored in the object store in a newly created tombstones folder per tenant. The file name will be
/<tenantId>/tombstones/<request_id>.<state>.json.
Query time filtering
Using the tombstone files, the queriers iterate over the samples fetched, using the store-gateway and ingesters, to filter out any samples requested for deletion before returning the results. The biggest challenge is determining how to load the tombstones into the queriers. The proposed solution was to load them through the bucket index. Because this approach is already how the block metadata is loaded into the queriers, the number of extra calls to the object store will be minimized.
In the compactor, the block-cleaner is responsible for updating the bucket index to have the most up-to-date view of the object store. Now, it will also write all the tombstones requiring query time filtering to the bucket index. Periodically, the queriers load the newly updated bucket index containing the tombstones.
If a particular instance of Cortex is configured with a query front end, then the to-be-deleted data can also be contained within the query result cache. To prevent unwanted data returning from the cache, the cache must be invalidated. This step is required after both the creation and cancellation of deletion requests.
The cache invalidation mechanism is done using cache generation numbers, which are prefixed to the query results cache. The cache is invalidated when the generation number received from the bucket index is greater than the previous one. The generation number is determined using the maximum timestamp of when the tombstone files were created. Thus, when a new tombstone file is created, the generation number is increased resulting in the cache being invalidated.
Permanent deletion processing
The data is not deleted right away, allowing any of the recently pushed data to move from the ingesters to long-term storage before processing deletion. This process begins after the configurable request cancellation period has passed and the data can begin to be deleted.
To process the tombstones for the deletions, a new service was proposed inside of the compactor, called the DeletedSeriesCleaner. This service is responsible for iterating over all the blocks and rewriting the new blocks without the deleted data. It is also responsible for managing the deletion lifecycle and updating the state of the requests once it has been processed. To delete the requested samples, the DeletedSeriesCleaner leverages the logic introduced in the bucket rewrite tool from the Thanos project.
The rewrite process will create a new block without the deleted data, and mark the original block to be deleted. To track which blocks have been processed for deletion, a new field is added within the rewritten block’s meta.json file stating the deletion requests IDs that have been applied to this particular block. When all the blocks with the requested series have been rewritten, the deletion request is moved to the Processed state. Query time filtering is still required until the queriers have picked up the new blocks.
It is important that a block that is being rewritten without the deleted series is not being used as part of compaction, as this can cause the compactor to create additional overlapping blocks containing the samples requested for deletion. To prevent such issues, deletions are only processed once the blocks have reached the final state of compaction.
The proposal describing the entire process in greater detail can be found in the Cortex documentation. The overall deletion process is shown in the following diagram:
API usage
To create the deletion requests, the API in Cortex is similar to the Prometheus Delete Series API. The Prometheus Clean Tombstones API is not supported because Cortex applies the deletions differently. The following examples show how to use the API.
Creating the deletion request
Viewing existing requests
Sample response:
Canceling requests
Further extensions
The work for this API is still in review and awaiting approval from the Cortex maintainers. Once merged, this API could be further extended to improve the experience of Cortex users and AMP customers. A current use case is to remove high-cardinality data to prevent inefficient queries. A possible extension is to incorporate a relabeling feature into the DeletedSeriesCleaner, which will allow users to keep their data while reducing the performance impact.
Explore the possibility of implementing the deletions API in the Thanos project may also be beneficial. Because many of the existing components are reused between Thanos and Cortex, some of the logic for the deletions can be potentially shared. Such an extension would further benefit the open source community and the Thanos users.
Conclusion and experiences
This internship was undoubtedly a huge learning experience for me. At the start of the internship, I had zero to little knowledge about distributed systems, microservices, or the observability space. I thought implementing a deletion feature would be straightforward, but I soon realized the intricacies of the observability use cases, scalability, and eventual consistency of distributed systems. During this internship, I had the opportunity to explore all of those topics and learn something new every day.
I also learned a lot about how Cortex works and the reasoning behind its current architecture. The Cortex system involves many different services, which can make learning how the entire system works more difficult. The main takeaway from this learning process is to start small and look at the individual services. Once I understood how the services work on their own, I increased the scope and learned about how they fit together. Starting at the individual services helps keep the level of abstraction lower and makes the overall process easier to understand.
A unique thing about this internship is being a part of the open source community. It was great to interact with the maintainers and users of Cortex and Thanos. They were welcoming to new contributors and were willing to discuss and help with the issues I was working on. Many of the videos and talks that the maintainers have previously given were helpful in learning how the systems work. Throughout this internship, I gained a better understanding of the open source development process, which involves discussing ideas during community meetings, writing proposal documents, and iterating over the concept until the community approves the ideas.

Ilan Gofman
Ilan is currently a fourth-year undergraduate computer science student at Carleton university. He is interested in learning about all things data, machine learning, and distributed systems.