AWS Open Source Blog
Announcing Gluon Time Series, an Open-Source Time Series Modeling Toolkit
Today, we announce the availability of Gluon Time Series (GluonTS), an Apache MXNet-based toolkit for time series analysis using the Gluon API. We are excited to give researchers and practitioners working with time series data access to this toolkit, which we have built for our own needs as applied scientists working on real-world industrial time series problems both at Amazon and on behalf of our customers. GluonTS is available as open source software on Github today, under the Apache license, version 2.0.
Time series applications are everywhere
We can find time series data, i.e. collections of data points indexed by time, across many different fields and industries. The time series of item sales in retail, metrics from monitoring devices, applications, or cloud resources, or time series of measurements generated by Internet of Things sensors, are only some of the many examples of time series data. The most common machine learning tasks related to time series are extrapolation (forecasting), interpolation (smoothing), detection (such as outlier, anomaly, or change-point detection), and classification.
Within Amazon, we record and make use of time series data across a variety of domains and applications. Some of these include forecasting the product and labor demand in our supply chain, or making sure that we can elastically scale AWS compute and storage capacity for all AWS customers. Anomaly detection on system and application metrics allows us to automatically detect when cloud-based applications are experiencing operational issues.
With GluonTS, we are open-sourcing a toolkit that we’ve developed internally to build algorithms for these and similar applications. It allows machine learning scientists to build new time series models, in particular deep-learning-based models, and compare them with state-of-the-art models included in GluonTS.
GluonTS highlights
GluonTS enables users to build time series models from pre-built blocks that contain useful abstractions. GluonTS also has reference implementations of popular models assembled from these building blocks, which can be used both as a starting point for model exploration, and for comparison. We’ve included tooling in GluonTS to alleviate researchers’ burden of having to re-implement methods for data processing, backtesting, model comparison, and evaluation. All of these are a time-sink and a source of error — after all, a bug in evaluation code leading to mischaracterization of a model’s actual performance can be much more severe than a bug in an algorithm (which would be detected before it is deployed).
Building blocks for assembling new time series models
We have written GluonTS such that many components can be combined and assembled in different ways, so that we can come up with and test new models quickly. Perhaps the most obvious components to include are neural network architectures, and GluonTS offers a sequence-to-sequence framework, auto-regressive networks, and causal convolutions, to name just a few. We’ve also included finer-grained components. For example, forecasts should typically be probabilistic, to better support optimal decision making. For this, GluonTS offers a number of typical parametric probability distributions, as well as tools for modeling cumulative distribution functions or quantile functions directly, which can be readily included in a neural network architecture. Further probabilistic components such as Gaussian Processes and linear-Gaussian state-space models (including a Kalman filter implementation) are also included, so that combinations of neural network and traditional probabilistic models can easily be created. We’ve also included data transformations such as the venerable Box-Cox transformation, whose parameters can be learned jointly with other model parameters.
Easy comparison with state-of-the-art models
GluonTS contains reference implementations of deep-learning-based time series models from the literature, which showcase how to use the components and can be used as starting points for model exploration. We’ve included models from our own line of research, such as DeepAR and spline quantile function RNNs, but also sequence models from other domains such as WaveNet (originally for speech synthesis, adapted here for the forecasting use case). GluonTS makes it easy to compare against these reference implementations, and also allows easy benchmarking against other models from other open-source libraries, such as Prophet and the R forecast package.
Tooling
GluonTS includes tooling for loading and transforming input data, so that data in different forms can be used and transformed to meet the requirements of a particular model. We have also included an evaluation component that computes many of the accuracy metrics discussed in the forecasting literature, and we look forward to contributions from the community in adding more metrics. As there are subtleties around how exactly the metrics are computed, having a standardized implementation is invaluable for making meaningful and reproducible comparisons between different models.
While metrics are, of course, important, the work of exploring, debugging, and continuously improving models often starts with plotting results on controlled data. For plotting, we rely on Matplotlib, and we’ve included a synthetic data set generator that can simulate time series data with various configurable characteristics.
How does GluonTS relate to Amazon Forecast?
GluonTS is targeted towards researchers, i.e. machine learning, time series modeling, and forecasting experts who want to design novel time series models, build their models from scratch, or require custom models for special use cases. For production use cases and users who don’t need to build custom models, Amazon offers Amazon Forecast, a fully-managed service that uses machine learning to deliver highly accurate forecasts. With Amazon Forecast, no machine learning expertise is required to build accurate, machine learning-based time series forecasting models, as Amazon Forecast employs AutoML capabilities that take care the heavy lifting of selecting, building, and optimizing the right models for you.
Getting started with GluonTS
GluonTS is available on GitHub and on PyPi. After you’ve completed installation, it’s easy to arrive at your first forecast using a pre-built forecasting model. Once you have collected your data, training a model and producing the following plot takes about ten lines of Python.
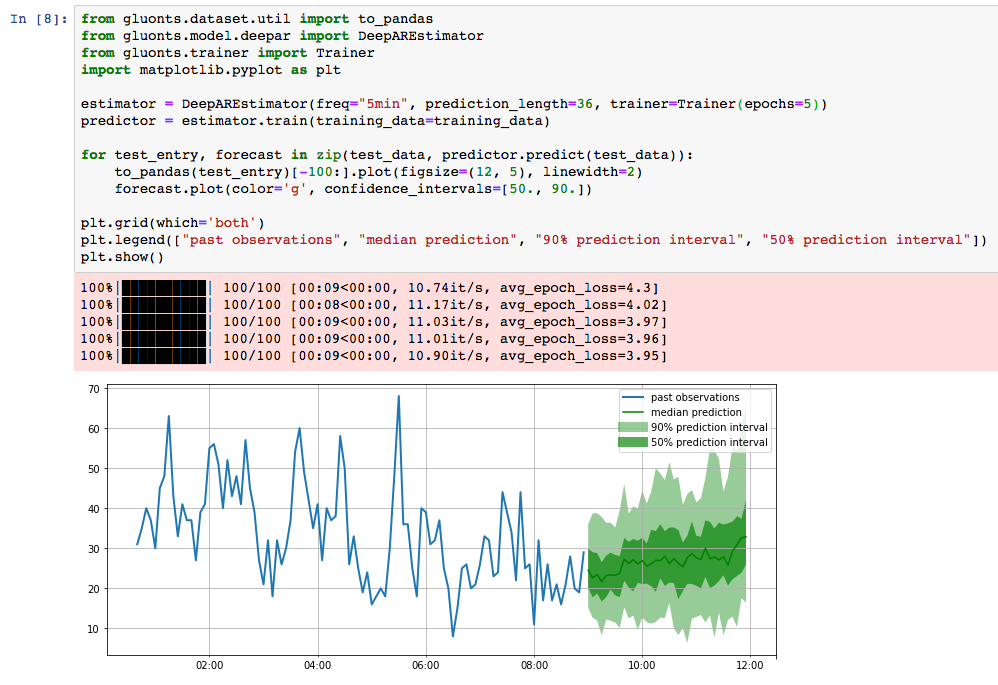
The figure above shows the forecast for the volume of Tweets (every five minutes) mentioning the AMZN ticker symbol. This was obtained by training a model on data from the Numenta Anomaly Benchmark dataset.
It is early days for us and GluonTS. We expect GluonTS to evolve over time, and we will add more applications beyond forecasting. Some more work is needed to reach a 1.0 version. We look forward to feedback and contributions to GluonTS in the form of bug reports, proposals for feature enhancements, pull requests for new and improved functionality, and, of course, implementations of the latest and greatest time series models.
Related literature and upcoming events
We have a paper on GluonTS at the ICML 2019 Time Series workshop and we will be giving tutorials at SIGMOD 2019 and KDD 2019 on forecasting, where we will feature GluonTS.
A sub-selection of publications featuring models in GluonTS:
- Probabilistic Forecasting with Spline Quantile Function RNNs
- A Multi-Horizon Quantile Recurrent Forecaster
- DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
Also see, on the AWS Machine Learning blog: Creating neural time series models with Gluon Time Series.
Lorenzo Stella, Syama Rangapuram, Konstantinos Benidis, Alexander Alexandrov, David Salinas, Danielle Maddix, Yuyang Wang, Valentin Flunkert, Jasper Schulz, and Michael Bohlke-Schneider also contributed to this post as well as to GluonTS.