AWS Storage Blog
How one AWS Hero uses AWS Storage Gateway for in-cloud backup
Over the course of my 25-year career in IT, including my time as an AWS Community Hero, I’ve developed a passion for data storage and protection. For the last 19 years, I’ve worked for Direct Supply, a provider of products, services, and solutions for the long-term care and acute care industries. In a previous blog, I mentioned that I’ve helped Direct Supply navigate a 30,000% data growth. As part of that work, I’ve architected and operated their data protection environment, expanding from gigabyte scale to writing 100 terabytes of backup data each week.
Part of being responsible for data protection and recovery involves brainstorming new ways that systems can fail and planning accordingly to prevent, remediate, or lessen the impact of unfavorable conditions. It always seems that failures and unfortunate circumstances occur at the least convenient time. Whether a backup tape malfunctions or you lose more drives than your RAID level can tolerate, there are always unfamiliar and unexpected failure modes to test the resiliency of your recovery plans.
In this blog, I provide five recommendations based on my learned experience that you can follow to give your business the best chance of successfully recovering data in the event of a disaster.
Some background
Three years ago, I began working in the cloud, helping Direct Supply move more than 90% of IT resources out of physical data centers. Leaning on my passion for data protection, I started integrating cloud capabilities with proven backup patterns. One such pattern was in use in my data center as a protection plan for Microsoft SQL Servers. I was using SQL Server’s capability to write data to a NAS environment over SMB, and wanted to continue to do so in the cloud. At that time I was working on a migration from on-premises SQL Servers to SQL Servers running in the AWS Cloud on Amazon EC2 instances. By applying a familiar and proven pattern to protect our Microsoft SQL Servers running on EC2, we could focus our attention on safely migrating the data, rather than on building and learning to support new workflows. I started building my first cloud backup environment on AWS, using an AWS Storage Gateway set up as a File Gateway and backed by Amazon S3: 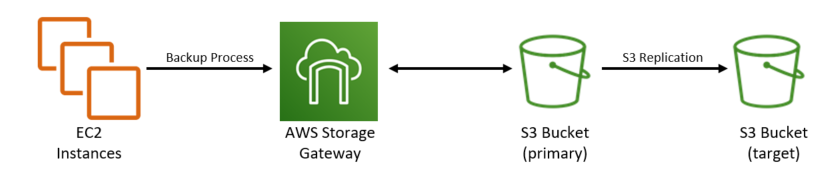
AWS offers a well-rounded portfolio of storage products and capabilities. I chose the AWS Storage Gateway architecture for three reasons: scalability, reliability, and capability. Because AWS Storage Gateway is backed by Amazon S3 storage, I don’t have to worry about scaling the backend storage to accommodate growth in the size of my database backups. Data stored in Amazon S3 is highly durable, so I know my backup data won’t be impacted by data center events. Lastly, Amazon S3 has several data management and governance features that are important to storing backup data in the cloud.
Over time, this in-cloud environment has evolved, taking advantage of new AWS features and capabilities. As I’ve dreamt of new ways my backups can fail, I’ve continued to add additional layers of resiliency. Ultimately, my business depends on me to be able to recover from a disaster using these backups, so it’s critical that I maintain a backup system to keep my business secure and protected. Now, let’s get into some recommendations…
Recommendation 1: Size matters
Backup plans are built with two key metrics in mind: Recovery Point Objective (RPO) and Recovery Time Objective (RTO). RPO defines the point in time to which you intend to recover your data and is a function of how frequently data is protected. RPO answers both “when was my last backup?” and “how much data could I have lost?” RTO is a function of recovery performance – a measurement of the maximum amount of time allowed to complete a restore.

There are several factors that contribute to a backup environment’s ability to meet RPO and RTO requirements. CPU performance on both the instance performing a backup and the instance supporting your AWS Storage Gateway can impact how fast your backup environment can scan and process data. An EC2 instance or AWS Storage Gateway’s network performance directly impacts how much data you can move in a given time window. The bandwidth between an EC2 instance and its AWS Storage Gateway, and the performance capabilities of the storage itself, governs how fast you can commit your backup to disk. Undersizing any of these system characteristics can compromise both RPO and RTO.
In my case, I quickly learned that the instance type I selected for my File Gateway impacted my RPO and RTO goals. Based on your workload, you can select from several different instance types, each having unique network and storage throughput capabilities.

You can see in the preceding comparison chart that choosing a C5.2xlarge instance type gives you more than four times the max Amazon EBS bandwidth when compared to a C4.2xlarge instance. This directly impacts the amount of data you can write to the gateway cache, and thus the speed at which your backup completes. The first gateway I deployed was properly sized for my on-premises performance capabilities, but was undersized for my workload running in the cloud. This caused slow data write performance for my backup jobs. Fortunately, updating to a larger and more performant EC2 instance type was a very painless process and helped me meet my RPO.
Recommendation 2: A tale of two copies
As I mentioned before, I strive to be prepared when things fail at the least convenient time. While a move to the cloud might eliminate your concerns over the reliability of physical media, there are chances for data to be impacted by well-intended administrators, misconfigured retention policies, or an accidental service termination. For the same reason that I used to always write my backups to two separate tapes in my data center, I always store my cloud-based backups in two locations.
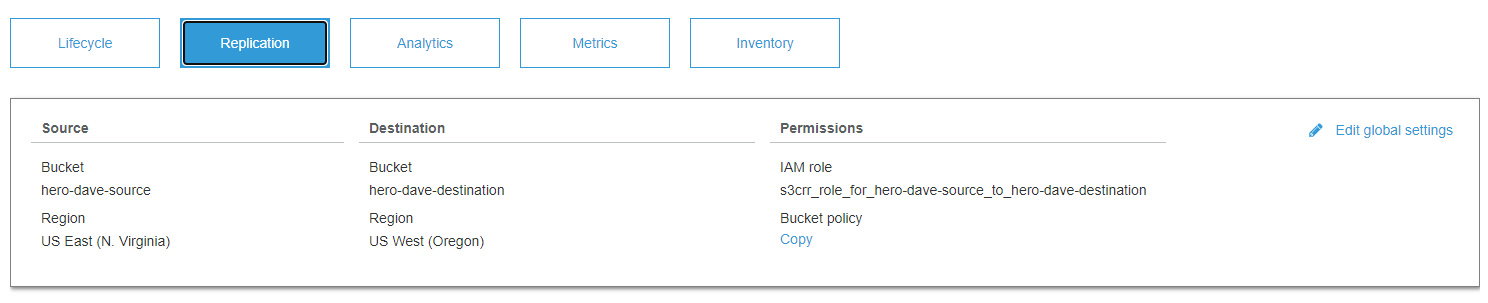
For my File Gateway and Amazon S3 environment, my media duplication plan started as simple as using S3 Replication to mirror my primary S3 bucket to a secondary bucket in another Region in the same account. If there were any issues accessing my data in my primary Region, I always had a second copy of the data on the other side of the continent. It worked out well, and even helped me leverage my backups to stand up some test environments when needed.
Recommendation 3: Separation is better in the cloud
An industry peer of mine confided how he had accidentally committed an API key in an open source contribution he pushed to a popular online code repository. Within minutes, he noticed that new users had been added to his account and very large EC2 instances were being launched in Regions he wasn’t using. AWS also detected the suspicious activity on the account and notified him promptly. In the end, there was no harm done to his account, but it got me thinking – what could have happened?
I quickly realized that having all my backups in the same account as the data they protect was a potential failure mode that I should remedy. While my data lived in two Regions, the leaking of a single API key, or maybe just a single rogue user in my account, could do harm to my backup data. I saw two options for locking this down: Enabling multi-factor authentication (MFA) delete on the S3 Replication target bucket, or moving the S3 Replication target bucket to a different account.
With MFA delete enabled, a secondary authentication would take place before an object could be deleted or a versioning state could be altered. This would have certainly put a significant security barrier in front of my backup data, but I kept thinking back to my days of managing tape backups and the security I had using an offsite vault. With the option of creating a second account, I could further limit the users accessing the data, require separate credentials to access the data, and provide a centralized place to also store backups from other accounts I managed. I chose to move the S3 Replication target to a different account for additional data protection for my backups.
Once this second account was launched, I tackled the user security and permissions within the account. Each user was required to set up a multi-factor authentication token for login and was not issued or allowed to create their own API keys. AWS Identity and Access Management (IAM) policies limited access to just the S3 buckets containing the data the user needed to access. With my security enhancements in place, I updated my S3 Replication policy to send data to a bucket in this new account.
Recommendation 4: Don’t wear out your welcome
In order to use S3 Replication, S3 Versioning must be enabled on the S3 bucket you’re replicating. Enabling this is as simple as checking a box in the AWS Management Console, but doing so without understanding how versioning works can cause data to grow quickly and unexpectedly. I’m not going to go into all the inner-workings of S3 object versioning; that documentation can be found in the S3 Developer guide. What I am going to cover, are the three S3 settings that I tuned to keep my data safe: retention times, object versioning, and storage tiering.
Retention times
Thinking of the reasons you restore data, it should be no surprise that restores are most likely to be sourced from the most recent backup. The value you get out of backup data declines as the data ages. To ease data management, you want to define a retention policy that makes sense for your data, its requirements, and your user community. In the case of my two-account environment, I have retention policies set on each data copy, scoping the primary copy for immediate restores (30 days), and the secondary copy for restores requiring older backups (90 days).
Object versioning
Second on this list is to understand how your backup process interacts with the objects it creates and how this interacts with object versioning. For example, some applications writing data create copies of pre-existing files and write the objects in a single write. Other applications frequently save and re-open a file as they stream data into the file. The file that copies in a single write will not create a previous version, while the constant updates to an object can create several previous versions – all of which are incomplete versions of the final backup file. If you don’t need the previous versions of the objects, you can set a separate retention policy to clean them up. In my environment, I delete previous object versions in the primary account immediately, and in the second account after 7 days.
Storage tiering
Third on this list is to understand S3 storage classes and how they can be used to create a tiering strategy to reduce the cost of storing backup data. If you’re the type of person who likes to manage all the configuration manually, you can do so. Just be sure you set your tiering policies such that data lives in a given storage class (tier) at least 30 days before deletion. File operations performed against files in the file share may result in early deletion charges. If you prefer to not think about it, you can always use S3 Intelligent-Tiering. S3 Intelligent-Tiering uses behind-the-scenes AI to store your data in the most appropriate storage class. Note that objects that are deleted, overwritten, or transitioned to a different storage class before 30 days will incur the normal storage usage charge plus a pro-rated request charge for the remainder of the 30-day minimum. In my environment, I’m using the S3 Standard storage class on the primary account, and S3 Intelligent-Tiering in the secondary account. You can always refer to the S3 pricing page to learn more about pricing for S3 storage classes. Verify your workflow before using S3 Intelligent-Tiering in production.
Recommendation 5: Pay attention to your backup and recovery workflow
At the end of the day, a good backup is just a tool for recovering data. As with any tool, you must know how to use it properly. The most secured backups in the world are worthless if you forget how to use them. It’s critical that you pay attention to your backup workflow and test your ability to recover often. Do you have a mechanism to alert you when backups fail or exceed your desired RPO?
Do you have a clearly documented process for how to restore data from backup? What if you have to leverage a secondary copy of the data? Is there automation you can create to expedite restores? Do you remember to update your backup process as your environment changes? And most importantly, have you tested your restore process to ensure it works? I’m hoping you’ve answered yes to all of these questions. If not, you’ve got a great opportunity to get things in order before your next critical recovery comes along. For my business, I developed a business continuity plan that answers all of the preceding questions, and I would encourage you to do the same.
Conclusion
In this blog post, I shared five things I recommend doing to get the most out a File Gateway and Amazon S3-based backup environment. AWS Storage Gateway, configured as a File Gateway and backed by Amazon S3, makes a reliable and easily deployed target for storing backup data. With the data governance and storage replication capabilities native to S3, it is easy to turn a single file share into a high-performing, scalable, and resilient backup platform.
My recommendations, summarized:
- Starting with RPO and RTO as requirements, properly size your File Gateway for network throughput, storage throughput, and data processing capability.
- Use S3 Replication to produce a second copy of your backup data – preferably in a second AWS Account.
- Limit the users that can access your backup data and require multi-factor authentication to keep the data as secure as possible.
- Take advantage of the data governance capabilities of Amazon S3 and understand how object versioning, storage tiering, and retention policies work together with S3 Replication.
- Last, and most important, make sure to validate backup and recovery workflows to eliminate any surprises.
Thanks for reading this blog post! If you are building or running a backup environment based on AWS Storage Gateway and Amazon S3, I hope you have found these recommendations helpful. I’d love to hear about your challenges or success protecting data in the cloud – let’s continue the conversation in the comments section!
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.