Containers
Creating Kubernetes Auto Scaling Groups for Multiple Availability Zones
Kubernetes is a scalable container orchestrator that helps you build fault-tolerant, cloud native applications. It can handle automatic container placement, scale up and down, and provision resources for your containers to run.
While Kubernetes can take care of many things, it can’t solve problems it doesn’t know about. Usually these are called unknown unknowns and come from things out of scope for applications and APIs. Examples include natural disasters and human error.
There are some things that systems like Kubernetes can’t control, but if you know constraints of your environment you can architect clusters to work within those constraints. In AWS, you need to consider failure domains and service boundaries when building clusters that cross multiple Regions or multiple Availability Zones.
AWS treats Regions and Availability Zones as failure domains that should be accounted for when running infrastructure that needs to be highly available. If you need a website to remain up when a single Region is unavailable then you need to deploy your application to multiple Regions. Each Region where your application is deployed should run in multiple Availability Zones (AZ) to ensure routing traffic across two or more failure domains.
Some of those failure domains are built into AWS services as constraints to help you design systems without unforeseen dependencies. For example, if you need an Amazon Elastic Block Storage (EBS) volume to be available to an EC2 instance, you can only mount that EBS volume from a specific Availability Zone. While EBS volumes are available in a single Availability Zone Amazon Elastic File System (EFS) is available in multiple Availability Zones in each Region. Other services such as IAM and Route 53 are available globally per account and have different trade-offs for performance and availability.
Running Kubernetes in a single Availability Zone can make your application highly available with EC2 instance failures, but it will not protect against outages that affect the entire AZ. It is best practice to make your cluster highly available in multiple AZs so your applications will still be available in case of zone failures.
However, a single Kubernetes cluster should not run across multiple AWS Regions or over a VPN or WAN connection. This was a design consideration early with Kubernetes that the API server(s) and the nodes that run workloads should be within a reliable, low-latency network connection to avoid network partitions and the need to replicate state across unreliable connections.
In AWS, the recommended way to run highly available Kubernetes clusters is using Amazon Elastic Kubernetes Service (EKS) with worker nodes spread across three or more Availability Zones. For globally available applications, you should run separate clusters in different Regions with multi-zone worker nodes.
There are lots of ways to make multiple Availability Zone worker nodes. Here we will consider the most reliable methods to run your clusters and stateful applications in multiple AZs.
It’s important to note that stateless containers do not have the same restrictions around AZ failure domains, but there is still some benefit to setting up your worker nodes in Availability Zone aware Auto Scaling groups.
If your containers store all of their state in an external database such as Amazon DynamoDB and send their logs and metrics to external collectors such as Amazon CloudWatch it is much easier to deal with AZ outages. Your load balancer (ELB, ALB, or NLB) attached to your Kubernetes services can already route traffic to multiple zones and DynamoDB has regional endpoints (e.g. https://dynamodb.us-west-2.amazonaws.com) so a single zone failure may require pods to be re-scheduled and new worker nodes to be created (via cluster autoscaler) but should not have downtime for your application.
The three common options for running multi-AZ worker nodes are:
- Availability Zone bounded Auto Scaling groups
- Region bounded Auto Scaling groups
- Individual instances without Auto Scaling groups
The Kubernetes cluster autoscaler is an important component to make sure your cluster does not run out of compute resources. This article will not address tuning the autoscaler for performance or optimizing your cluster for cost.
Availability Zone bounded Auto Scaling groups
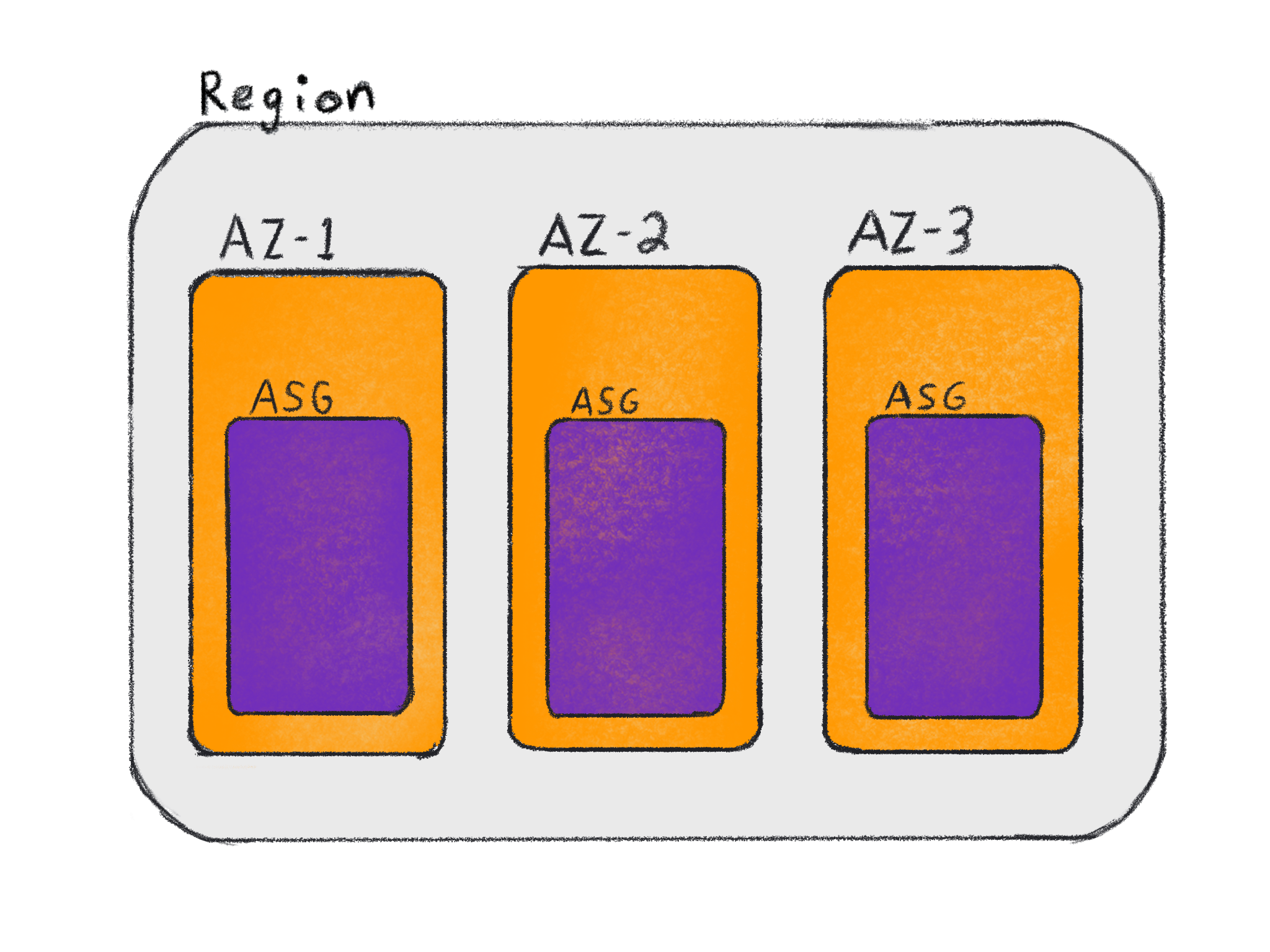
If your Kubernetes pods use EBS volumes, then you should set up your Auto Scaling groups to have one for every Availability Zone where you want to run workloads. This will allow you to define failure domains on worker node groups (e.g. topology.kubernetes.io/zone=us-west-2b) and then schedule pods to nodes in that Availability Zone.
These labels will automatically be added to your nodes via the Kubernetes cloud provider and automatically added to your PersistentVolumes via the AWS EBS CSI driver. This means that the initial pod placement and EBS volume provisioning is transparent to you when the pod is initially scheduled. If a pod using an EBS volume is rescheduled or the instance is terminated, you will need to make sure your pod has a nodeSelector that matches your topology label and you may need to run separate Kubernetes deployments for each AZ.
The reason you need an ASG per AZ is in cases where you do not have enough compute capacity in a specific AZ. For example, if your ASG in us-west-2b is at maximum capacity and a pod needs to run with access to an EBS volume in that AZ. The cluster autoscaler needs to be able to add resources to that AZ in order for the pod to be scheduled.
If you run one ASG that spans multiple AZs, then the cluster autoscaler has no control over which AZ new instances will be created. The cluster autoscaler can add capacity to the ASG, but it may take multiple tries before an instance is created in the correct AZ.
In the case of an AZ outage, the EBS volumes in that AZ will be unavailable and the pods that request those volumes will not be scheduled.
The following is an example StatefulSet that requires a PersistentVolume in us-west-2b. Note, this example shows a storage class being mounted into a MySQL container but is not a complete example of a StatefulSet. To run a complete example of StatefulSets on Kubernetes check out the EKS workshop.
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: mysql
name: mysql
spec:
selector:
matchLabels:
app: mysql
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: mysql-gp2
resources:
requests:
storage: 10GiIn general, the Kubernetes scheduler will initially schedule pods to the correct AZ for EBS volumes. The main benefit of multiple ASGs is the interaction with the cluster autoscaler and making sure you scale up compute resources in the same Availability Zones as your storage resources.
With an ASG per AZ, you will also need to make sure you configure the cluster autoscaler to scale each ASG. An example of how to configure that can be found in the Kubernetes examples on GitHub.
To create an EKS cluster with one ASG per AZ in us-west-2a, us-west-2b, and us-west-2c, you can use a config file and create the cluster with eksctl like the example below.
cat <<EOF | eksctl create cluster --file -
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: multi-asgs
region: us-west-2
nodeGroups:
- name: ng1
instanceType: m5.xlarge
availabilityZones:
- us-west-2a
- name: ng2
instanceType: m5.xlarge
availabilityZones:
- us-west-2b
- name: ng3
instanceType: m5.xlarge
availabilityZones:
- us-west-2c
EOFFor more information on zone-aware auto scaling and eksctl, you can reference the documentation here.
Running an ASG per AZ includes additional overhead of managing more ASGs and more Kubernetes deployments (one per AZ). If you can avoid using EBS volumes in your pods a much simpler approach is to use a single ASG that spans multiple AZs with EFS for local state storage.
Region bounded Auto Scaling groups
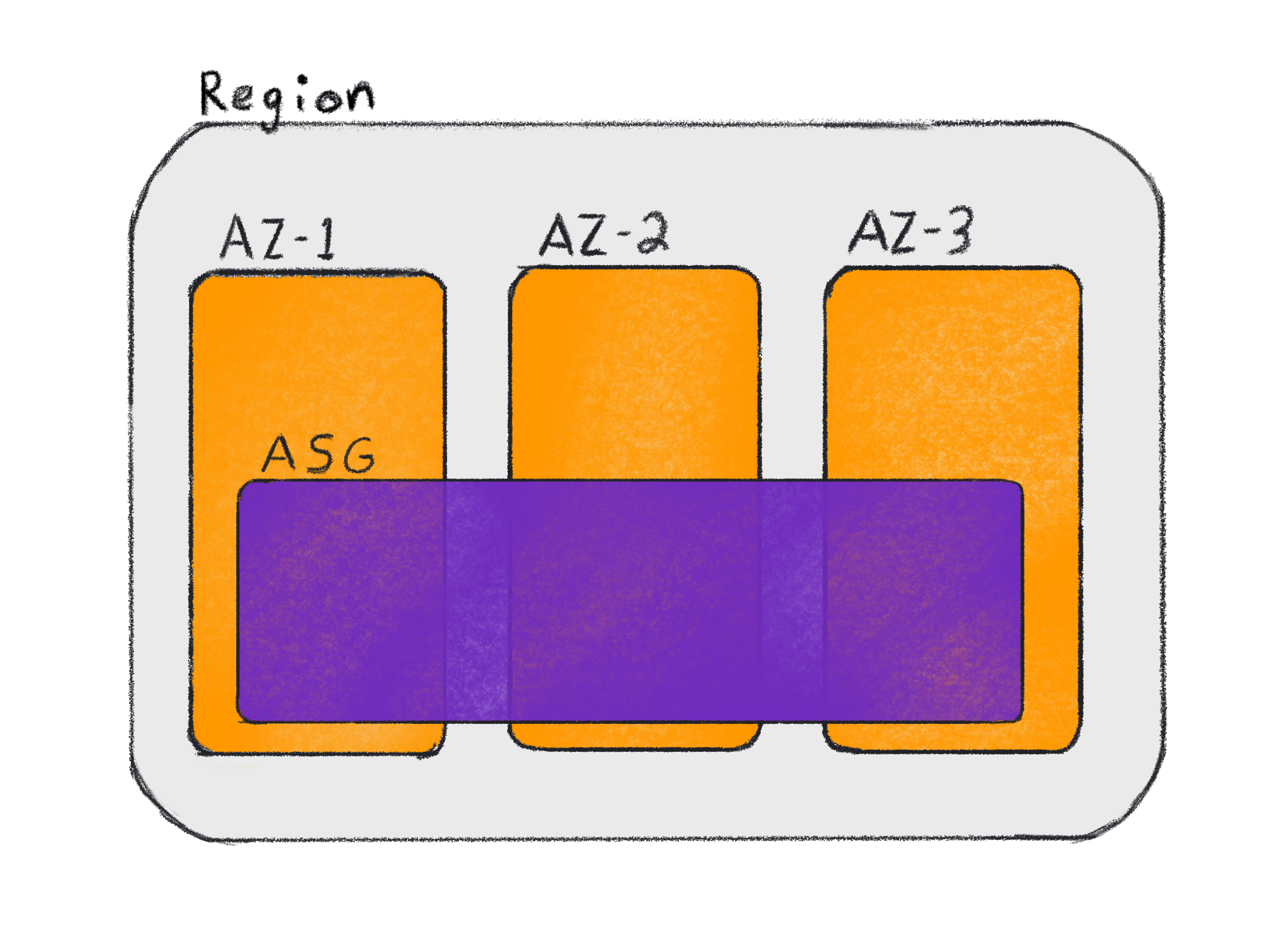
A major reason to use Auto Scaling groups in Kubernetes is so you can use the Kubernetes cluster autoscaler to add compute resources to a cluster. Region specific Auto Scaling groups allow you to spread compute resources across multiple Availability Zones, which help applications be resilient to zone specific maintenance.
An ASG spread across multiple AZs can still take advantage of the cluster autoscaler as well as any auto scaling trigger AWS provides. This includes scaling clusters from internal metrics as well as external sources like Amazon EventBridge.
An ASG that spreads across multiple AZs cannot be scaled on a per-AZ basis, but if you are not using services where resources bound to an AZ (e.g. EBS volumes), it may not be a concern for you. If you can store your container state in EFS or RDS instead of EBS volumes, you should use ASGs that span AZs.
Having a single ASG simplifies your architecture, configuration, and interactions between components, which can make your systems easier to understand and debug. It allows you to simplify your Kubernetes deployments (1 per Region) and more easily troubleshoot if something breaks because there are less moving parts to consider.
To create an EKS cluster with a single Auto Scaling Group that spans three AZs you can use the example command:
eksctl create cluster --region us-west-2 --zones us-west-2a,us-west-2b,us-west-2cIf you need to run a single ASG spanning multiple AZs and still need to use EBS volumes you may want to change the default VolumeBindingMode to WaitForFirstConsumer as described in the documentation here. Changing this setting “will delay the binding and provisioning of a PersistentVolume until a pod using the PersistentVolumeClaim is created.” This will allow a PVC to be created in the same AZ as a pod that consumes it.
If a pod is descheduled, deleted and recreated, or an instance where the pod was running is terminated then WaitForFirstConsumer won’t help because it only applies to the first pod that consumes a volume. When a pod reuses an existing EBS volume there is still a chance that the pod will be scheduled in an AZ where the EBS volume doesn’t exist.
Instances without Auto Scaling groups
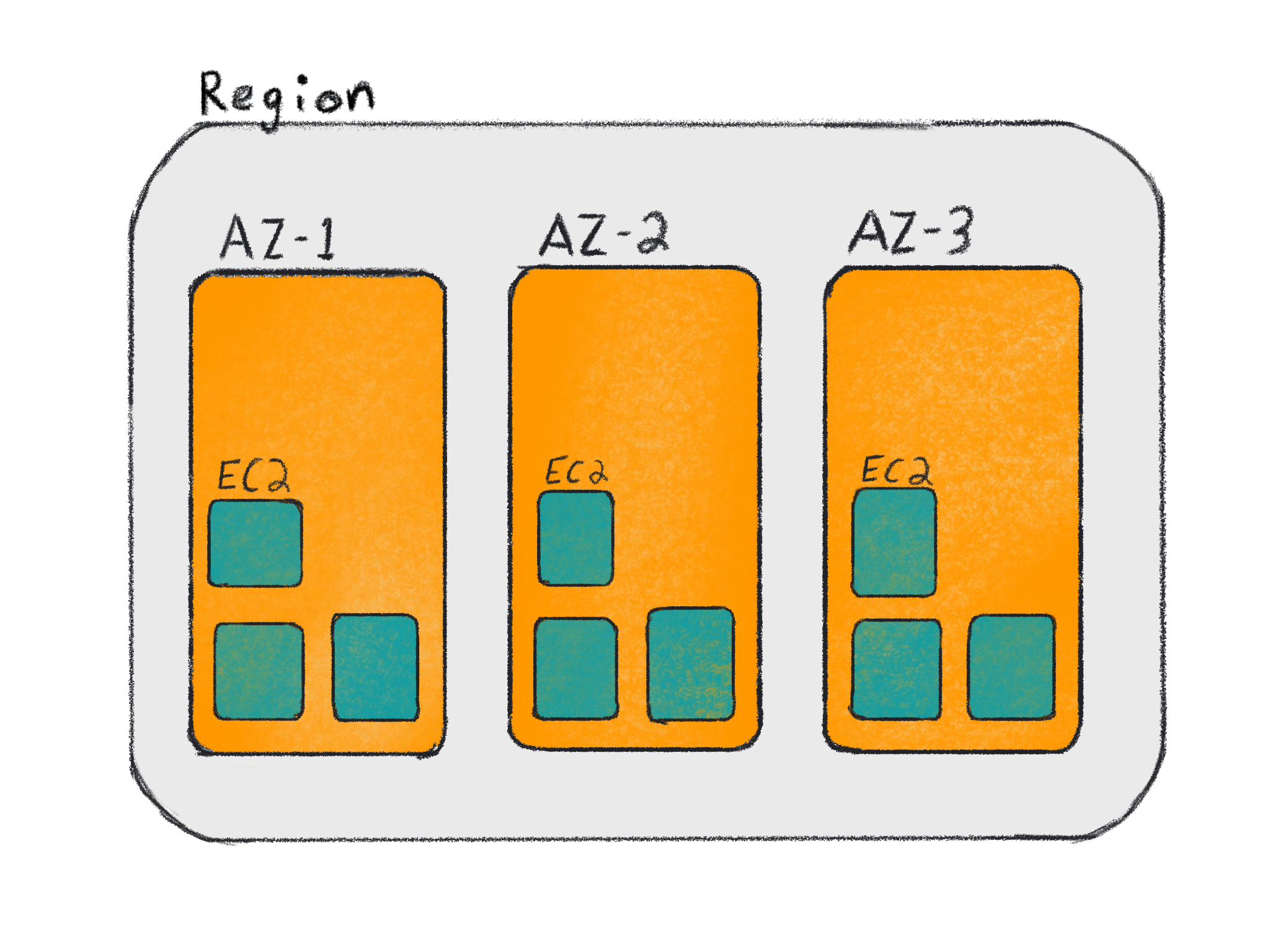
While you can run instances without an Auto Scaling group, you cannot use the cluster autoscaler with the AWS provider. You can still use the cluster autoscaler if you have a different provider such as cluster-api, but you may lose some AWS capabilities with managing individual EC2 instances instead of with an ASG (e.g. CloudWatch scaling).
It is not generally recommended to run an EKS cluster with instances outside of an ASG unless you have a provisioning service that scales and tracks your instances. If you’re interested in using cluster-api with Auto Scaling groups, then you should contribute to the proposal for MachinePools.
You should also be aware that some installers (e.g. kops) will create an ASGs with a minimum, maximum, and desired count of 1 for control plane instances. This is not intended to be used to scale the control plane, but it allows an unhealthy instance to be replaced easily without the concern of data loss due to the use of EBS volumes for state storage.
Other considerations
Load balancer endpoints
When running services that span multiple AZs, you should also consider setting the externalTrafficPolicy in your service to help reduce cross AZ traffic. The default setting for externalTrafficPolicy is “Cluster,” which allows every worker node in the cluster to accept traffic for every service no matter if a pod for that service is running on the node or not. Traffic is then forwarded on to a node running the service via kube-proxy.
This is typically fine for smaller or single AZ clusters but when you start to scale your instances it will mean more instances will be backends for a service and the traffic is more likely to have an additional hop before it arrives at the instance running the container it wants.
By setting externalTrafficPolicy to Local, instances that are running the service container will be load balancer backends, which will reduce the number of endpoints on the load balancer and the number of hops the traffic will need to take.
Another benefit of using the Local policy is you can preserve the source IP from the request. As the packets route through the load balancer to your instance and ultimately your service, the IP from the originating request can be preserved without an additional kube-proxy hop.
An example service object with externalTrafficPolicy set would look like this:
apiVersion: v1
kind: Service
metadata:
name: example-service
spec:
selector:
app: example
ports:
- port: 8765
targetPort: 9376
externalTrafficPolicy: Local
type: LoadBalancerIf you set externalTrafficPolicy, you should also consider setting pod anti-affinity for your deployment. Without pod anti-affinity, it is possible for all of your pods to end up on the same node, which could cause problems if the node goes away.
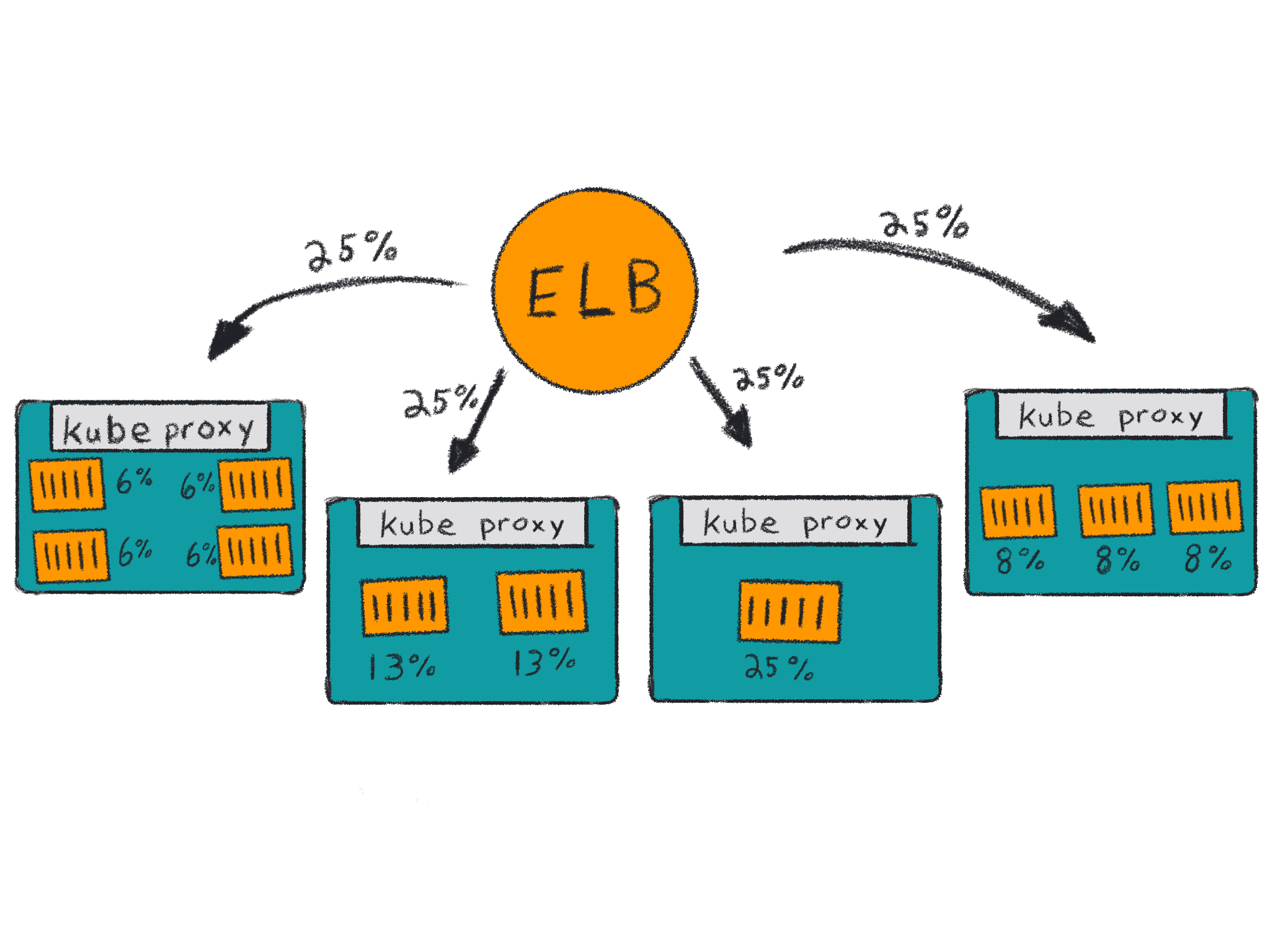
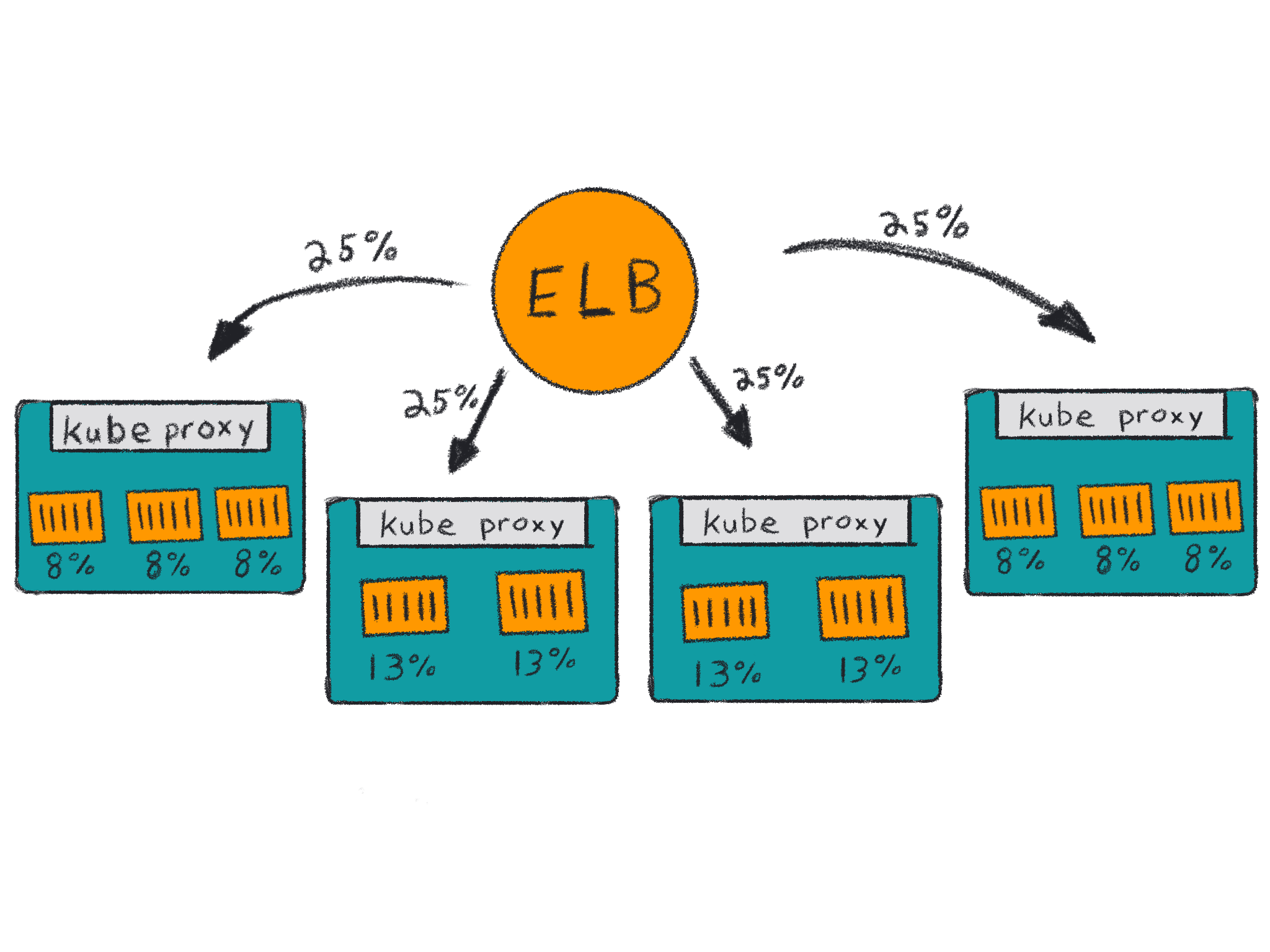
This can also be a problem if instances have an imbalanced spread of pods running your service. Loadbalancers don’t know how many pods are running on each instance, only that an instance is accepting traffic on a specific port. If you have two instances and three pods, then both instances will receive 50% of the traffic but two of the containers will only receive 25% of the traffic because the local kube-proxy will evenly balance the requests it receives.

This imbalance may also happen more drastically if you have more instances and containers. Kubernetes doesn’t actively reschedule pods when new instances are added to the cluster unless you run something like the descheduler at regular intervals.
To set pod anti-affinity based on hostname, you should add the following snippet to your deployment.
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- my-app
topologyKey: kubernetes.io/hostnameWith pod anti-affinity, your traffic may not be evenly split, but during placement decisions the scheduler will try to evenly spread your containers on instances. It still may be a good idea to run the descheduler if your cluster size fluctuates, but your pods do not scale up as often.
Service topology
Thanks to the way Kubernetes integrates into AWS via the cloud provider, there is a benefit you can get no matter how your ASGs are set up. Service topology was introduced as an alpha feature in Kubernetes 1.17 and it allows you to take into account AWS failure domains without additional infrastructure management on your part.
EKS does not enable alpha features so you’ll need to manage your own control plane or wait for service topologies to be promoted to beta in a future Kubernetes release.
By default, a pod will discover a service endpoint via DNS round robin and route traffic without consideration for failure domains, latency, or cost. Cross AZ routing shouldn’t add much latency to service calls, but if you’re sending a lot of data you will have to consider data transfer costs.
Service topology is helpful for both stateful and stateless containers by allowing the service owner to specify topologyKeys to consider when discovering endpoints for the service. This works similar to locality load balancing in Istio and is helpful to reduce failures, improve performance, and avoid unnecessary costs.
An example service that would first route traffic to an endpoint running on the same host and then route traffic to any endpoint in the same AZ would look like this:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- "kubernetes.io/hostname"
- "topology.kubernetes.io/zone"If no service endpoint is running on a node with the same hostname or the same zone then the service will not be returned a service endpoint from CoreDNS and service discovery will fail. This means service topologyKeys need to be inclusive of all the endpoint labels you want the service to use.
You can control the order service endpoints are discovered by ordering your topologyKeys from top to bottom in your manifest. If you want endpoints in the same Availability Zone and the same Region to be preferred over any other endpoint you should apply these topologyKeys:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- "topology.kubernetes.io/zone"
- "topology.kubernetes.io/region"
- "*"Conclusion
There are lots of things to consider when running highly available Kubernetes. Every company has their own requirements and constraints to consider. If possible, you should make your infrastructure as simple as possible and use services that span AZs such as EFS, RDS, and ELB to make highly available applications easier.
Depending on your workloads, you may also get benefits from not managing nodes at all with managed node groups or EKS on Fargate. You can still have a lot of the benefits described above without any of the complexity of managing it yourself.
If you want more information on running EKS clusters check out the best practices written by engineers who build the EKS service. We encourage you to get involved with the Kubernetes community via the special interest groups (SIGs). You can join sig-aws and talk to other AWS users running Kubernetes or join the slack community at http://slack.k8s.io.