AWS Big Data Blog
Amazon Redshift continues its price-performance leadership
Data is a strategic asset. Getting timely value from data requires high-performance systems that can deliver performance at scale while keeping costs low. Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. We continue to add new capabilities to improve the price-performance ratio for our customers as you bring more data to your Amazon Redshift environments.
This post goes into detail on the analytic workload trends we’re seeing from the Amazon Redshift fleet’s telemetry data, new capabilities we have launched to improve Amazon Redshift’s price-performance, and the results from the latest benchmarks derived from TPC-DS and TPC-H, which reinforce our leadership.
Data-driven performance optimization
We relentlessly focus on improving Amazon Redshift’s price-performance so that you continue to see improvements in your real-world workloads. To this end, the Amazon Redshift team takes a data-driven approach to performance optimization. Werner Vogels discussed our methodology in Amazon Redshift and the art of performance optimization in the cloud, and we have continued to focus our efforts on using performance telemetry from our large customer base to drive the Amazon Redshift performance improvements that matter most to our customers.
At this point, you might ask why does price-performance matter? One critical aspect of a data warehouse is how it scales as your data grows. Will you be paying more per TB as you add more data, or will your costs remain consistent and predictable? We work to make sure that Amazon Redshift delivers not only strong performance as your data grows, but also consistent price-performance.
Optimizing high-concurrency, low-latency workloads
One of the trends that we have observed is that customers are increasingly building analytics applications that require high concurrency of low-latency queries. In the context of data warehousing, this can mean hundreds or even thousands of users running queries with response time SLAs of under 5 seconds.
A common scenario is an Amazon Redshift-powered business intelligence dashboard that serves analytics to a very large number of analysts. For example, one of our customers processes foreign exchange rates and delivers insights based on this data to their users using an Amazon Redshift-powered dashboard. These users generate an average of 200 concurrent queries to Amazon Redshift that can spike to 1,200 concurrent queries at the open and close of the market, with a P90 query SLA of 1.5 seconds. Amazon Redshift is able to meet this requirement, so this customer can meet their business SLAs and provide the best service possible to their users.
A specific metric we track is the percentage of runtime across all clusters that is spent on short-running queries (queries with runtime less than 1 second). Over the last year, we’ve seen a significant increase in short query workloads in the Amazon Redshift fleet, as shown in the following chart.
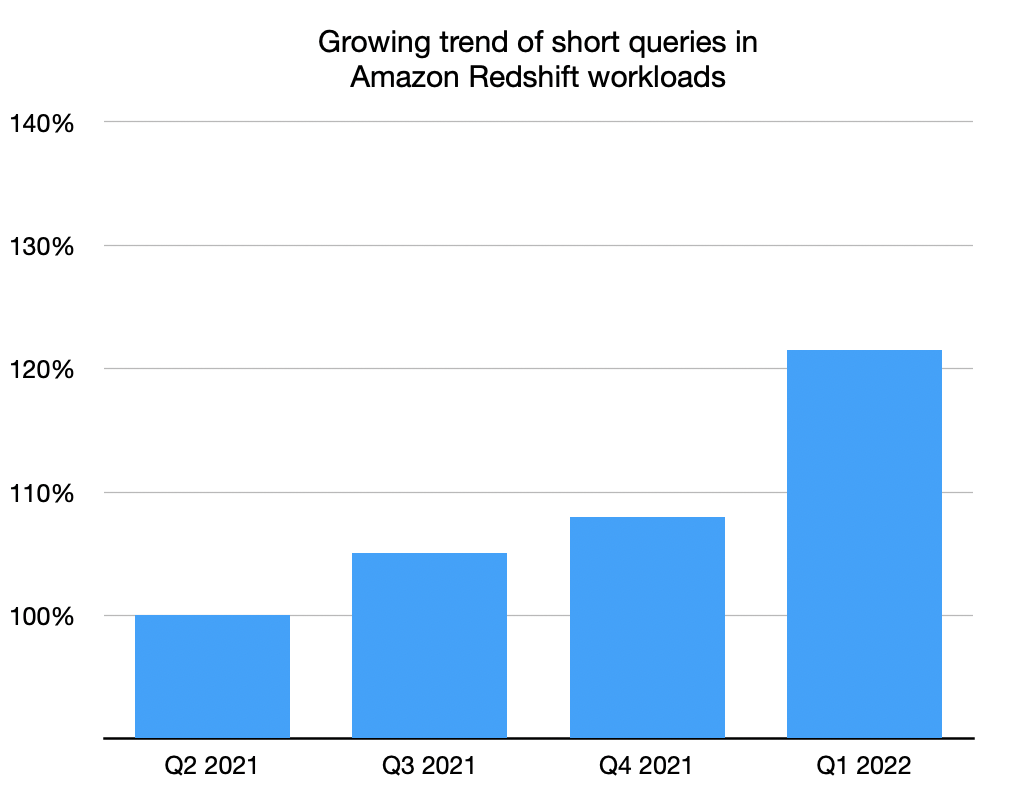 As we started to look deeper into how Amazon Redshift ran these kinds of workloads, we discovered several opportunities to optimize performance to give you even better throughput on short queries:
As we started to look deeper into how Amazon Redshift ran these kinds of workloads, we discovered several opportunities to optimize performance to give you even better throughput on short queries:
- We significantly reduced Amazon Redshift’s query-planning overhead. Even though this isn’t large, it can be a significant portion of the runtime of short queries.
- We improved the performance of several core components for situations where many concurrent processes contend for the same resources. This further reduced our query overhead.
- We made improvements that allowed Amazon Redshift to more efficiently burst these short queries to concurrency scaling clusters to improve query parallelism.
To see where Amazon Redshift stood after making these engineering improvements, we ran an internal test using the Cloud Data Warehouse Benchmark derived from TPC-DS (see a later section of this post for more details on the benchmark, which is available in GitHub). To simulate a high-concurrency, low-latency workload, we used a small 10 GB dataset so that all queries ran in a few seconds or less. We also ran the same benchmark against several other cloud data warehouses. We didn’t enable auto scaling features such as concurrency scaling on Amazon Redshift for this test because not all data warehouses support it. We used an ra3.4xlarge Amazon Redshift cluster, and sized all other warehouses to the closest matching price-equivalent configuration using on-demand pricing. Based on this configuration, we found that Amazon Redshift can deliver up to 8x better performance on analytics applications that predominantly required short queries with low latency and high concurrency, as shown in the following chart.
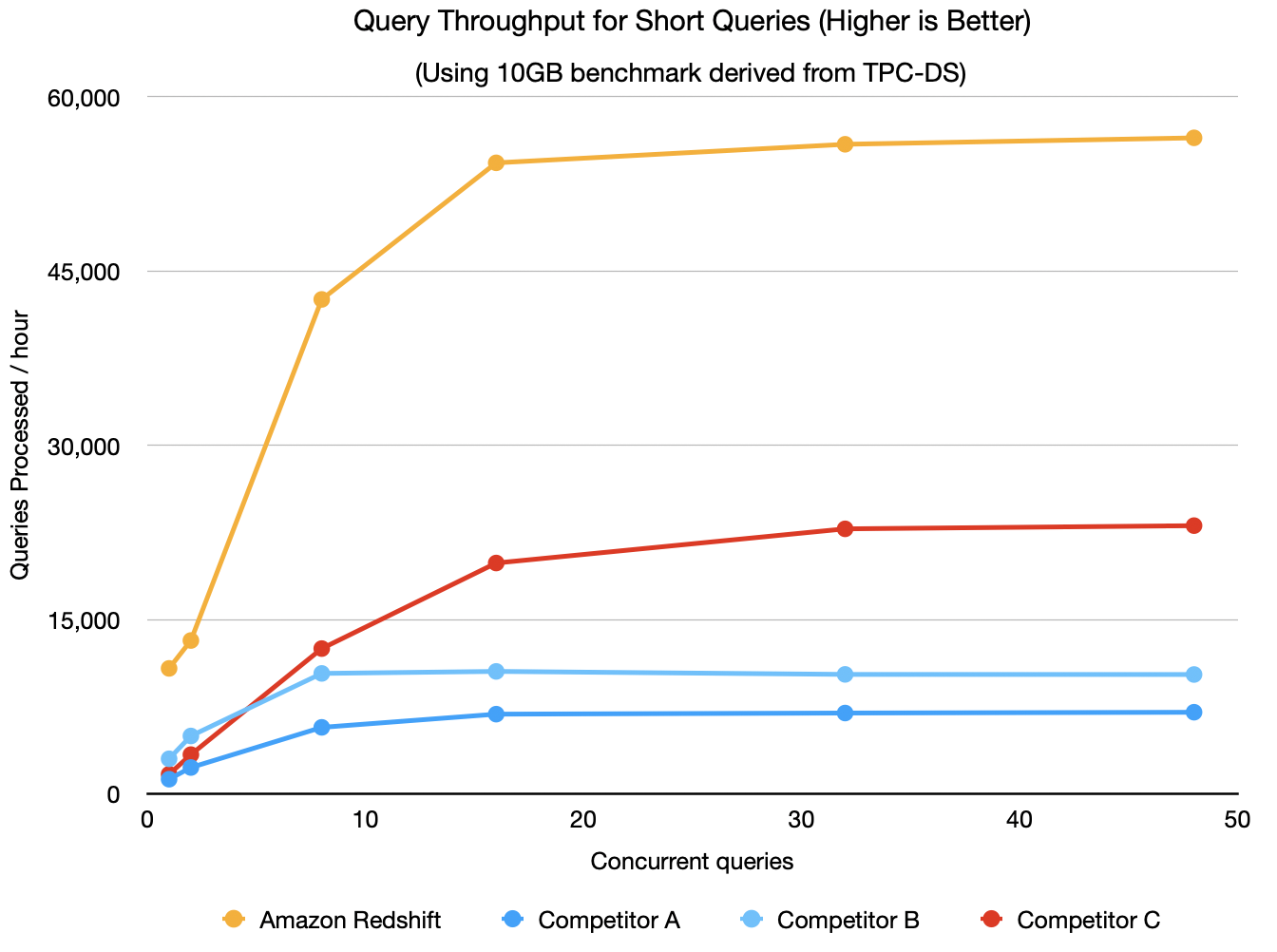
With Concurrency Scaling on Amazon Redshift, throughput can be seamlessly and automatically scaled to additional Amazon Redshift clusters as user concurrency grows. We increasingly see customers using Amazon Redshift to build such analytics applications based on our telemetry data.
This is just a small peek into the behind-the-scenes engineering improvements our team is continually making to help you improve performance and save costs using a data-driven approach.
New features improving price-performance
With the constantly evolving data landscape, customers want high-performance data warehouses that continue to launch new capabilities to deliver the best performance at scale while keeping costs low for all workloads and applications. We have continued to add features that improve Amazon Redshift’s price-performance out of the box at no additional cost to you, allowing you to solve business problems at any scale. These features include the use of best-in-class hardware through the AWS Nitro System, hardware acceleration with AQUA, auto-rewriting queries so that they run faster using materialized views, Automatic Table Optimization (ATO) for schema optimization, Automatic Workload Management (WLM) to offer dynamic concurrency and optimize resource utilization, short query acceleration, automatic materialized views, vectorization and single instruction/multiple data (SIMD) processing, and much more. Amazon Redshift has evolved to become a self-learning, self-tuning data warehouse, abstracting away the performance management effort needed so you can focus on high-value activities like building analytics applications.
To validate the impact of the latest Amazon Redshift performance enhancements, we ran price-performance benchmarks comparing Amazon Redshift with other cloud data warehouses. For these tests, we ran both a TPC-DS-derived benchmark and a TPC-H-derived benchmark using a 10-node ra3.4xlarge Amazon Redshift cluster. To run the tests on other data warehouses, we chose warehouse sizes that most closely matched the Amazon Redshift cluster in price ($32.60 per hour), using published on-demand pricing for all data warehouses. Because Amazon Redshift is an auto-tuning warehouse, all tests are “out of the box,” meaning no manual tunings or special database configurations are applied—the clusters are launched and the benchmark is run. Price-performance is then calculated as cost per hour (USD) times the benchmark runtime in hours, which is equivalent to the cost to run the benchmark.
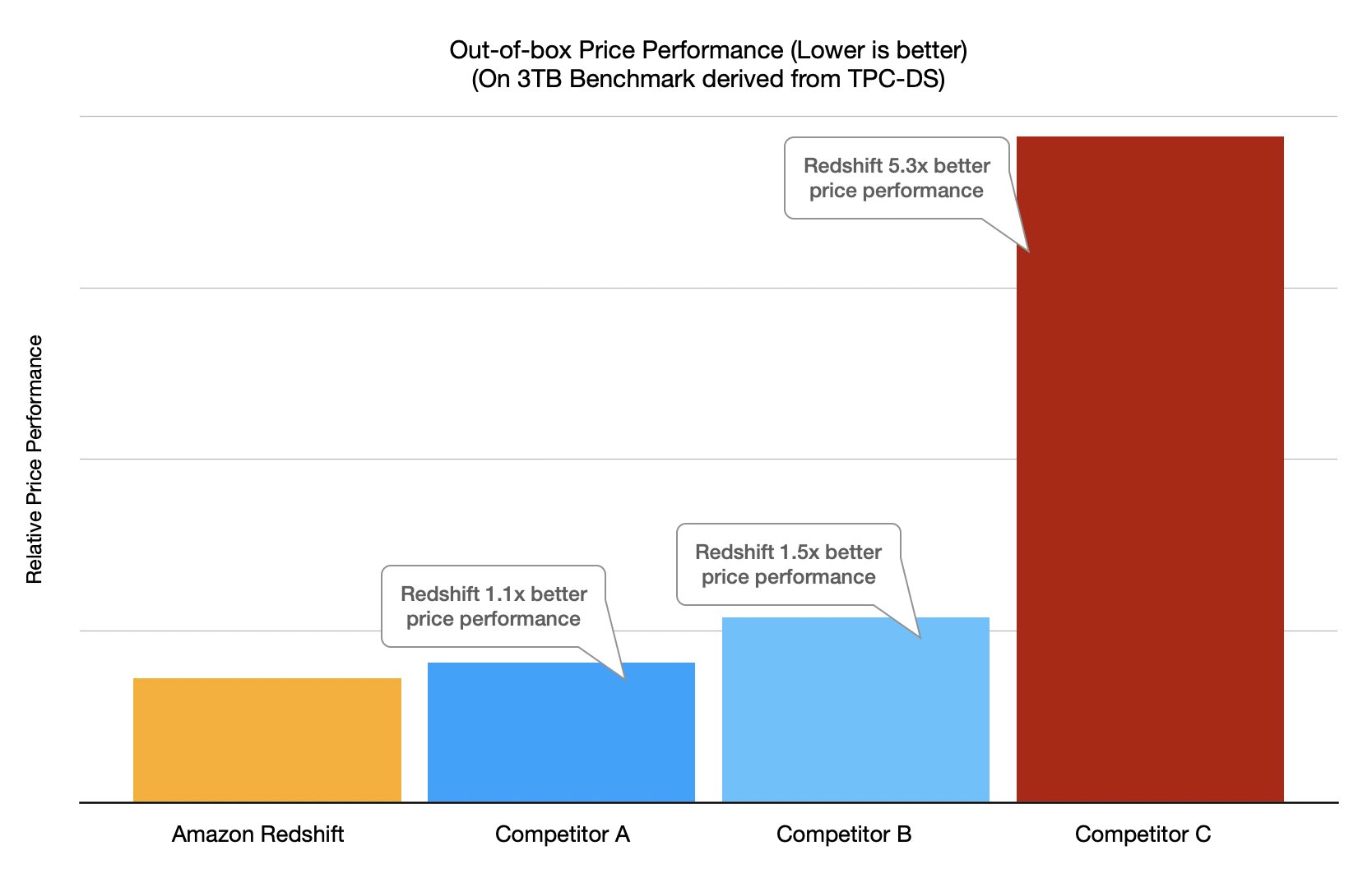
For both the TPC-DS-derived and TPC-H-derived tests, we find that Amazon Redshift consistently delivers the best price-performance. The following chart shows the results for the TPC-DS-derived benchmark.
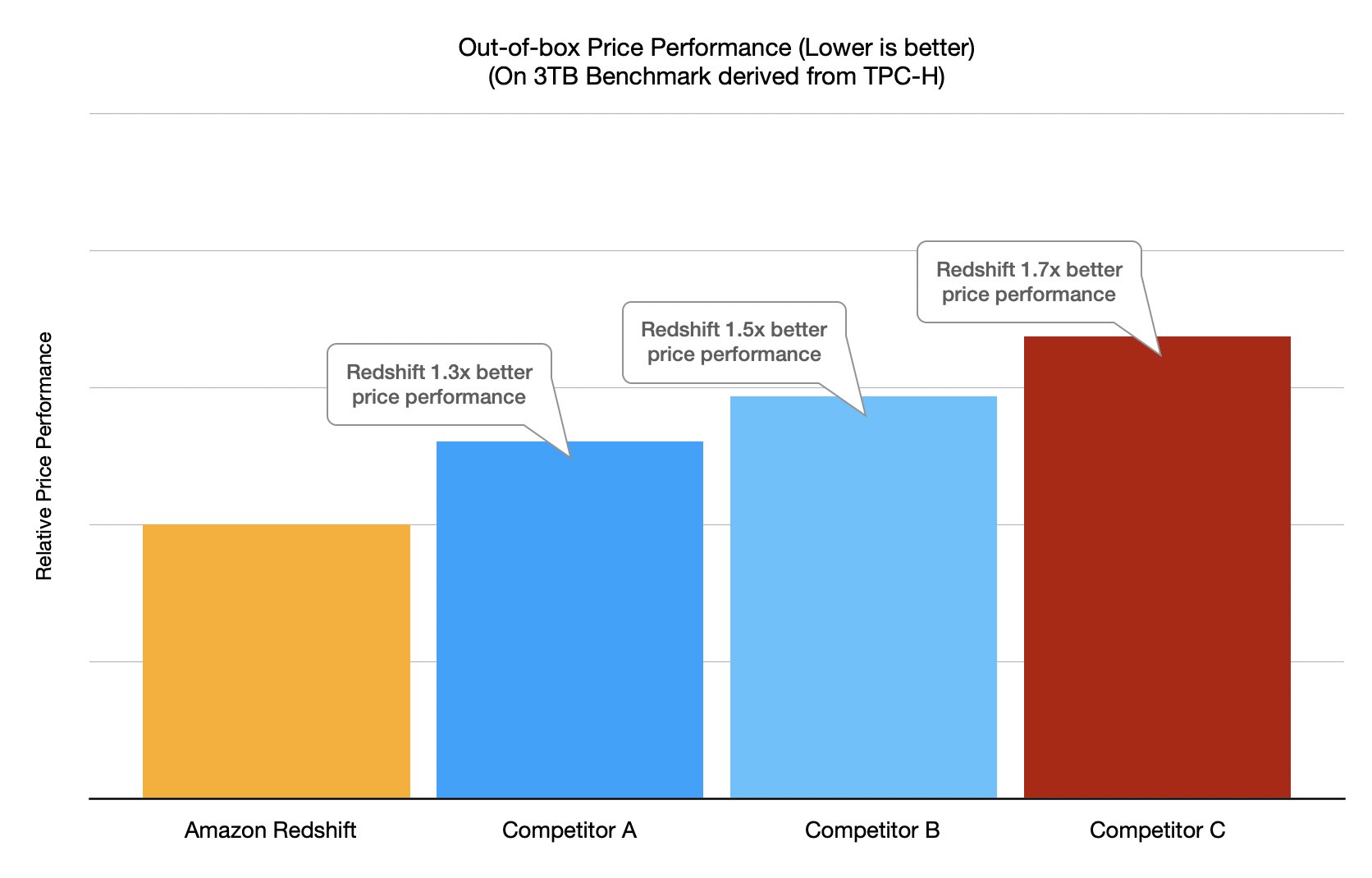
The following chart shows the results for the TPC-H-derived benchmark.
Although these benchmarks reaffirm Amazon Redshift’s price-performance leadership, we always encourage you to try Amazon Redshift using your own proof-of-concept workloads as the best way to see how Amazon Redshift can meet your data needs.
Find the best price-performance for your workloads
The benchmarks used in this post are derived from the industry-standard TPC-DS and TPC-H benchmarks, and have the following characteristics:
- The schema and data are used unmodified from TPC-DS and TPC-H.
- The queries are used unmodified from TPC-DS and TPC-H. TPC-approved query variants are used for a warehouse if the warehouse doesn’t support the SQL dialect of the default TPC-DS or TPC-H query.
- The test includes only the 99 TPC-DS and 22 TPC-H SELECT queries. It doesn’t include maintenance and throughput steps.
- Three power runs (single stream) were run with query parameters generated using the default random seed of the TPC-DS and TPC-H kits.
- The primary metric of total query runtime is used when calculating price-performance. The runtime is taken as the best of the three runs.
- Price-performance is calculated as cost per hour (USD) times the benchmark runtime in hours, which is equivalent to cost to run the benchmark. Published on-demand pricing is used for all data warehouses.
We call this benchmark the Cloud Data Warehouse Benchmark, and you can easily reproduce the preceding benchmark results using the scripts, queries, and data available on GitHub. It is derived from the TPC-DS and TPC-H benchmarks as described earlier, and as such is not comparable to published TPC-DS or TPC-H results, because the results of our tests don’t comply with the specification.
Each workload has unique characteristics, so if you’re just getting started, a proof of concept is the best way to understand how Amazon Redshift performs for your requirements. When running your own proof of concept, it’s important to focus on the right metrics—query throughput (number of queries per hour) and price-performance. You can make a data-driven decision by running a proof of concept on your own or with assistance from AWS or a system integration and consulting partner.
Conclusion
This post discussed the analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Amazon Redshift’s price-performance, and the results from the latest benchmarks.
If you’re an existing Amazon Redshift customer, connect with us for a free optimization session and briefing on the new features announced at AWS re:Invent 2021. To stay up to date with the latest developments in Amazon Redshift, follow the What’s New in Amazon Redshift feed.
About the Authors
 Stefan Gromoll is a Senior Performance Engineer with Amazon Redshift where he is responsible for measuring and improving Redshift performance. In his spare time, he enjoys cooking, playing with his three boys, and chopping firewood.
Stefan Gromoll is a Senior Performance Engineer with Amazon Redshift where he is responsible for measuring and improving Redshift performance. In his spare time, he enjoys cooking, playing with his three boys, and chopping firewood.
 Ravi Animi is a Senior Product Management leader in the Redshift Team and manages several functional areas of the Amazon Redshift cloud data warehouse service including performance, spatial analytics, streaming ingestion and migration strategies. He has experience with relational databases, multi-dimensional databases, IoT technologies, storage and compute infrastructure services and more recently as a startup founder using AI/deep learning, computer vision, and robotics.
Ravi Animi is a Senior Product Management leader in the Redshift Team and manages several functional areas of the Amazon Redshift cloud data warehouse service including performance, spatial analytics, streaming ingestion and migration strategies. He has experience with relational databases, multi-dimensional databases, IoT technologies, storage and compute infrastructure services and more recently as a startup founder using AI/deep learning, computer vision, and robotics.
 Florian Wende is a Performance Engineer with Amazon Redshift.
Florian Wende is a Performance Engineer with Amazon Redshift.