AWS Compute Blog
Surviving the Zombie Apocalypse with Serverless Microservices
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Run Apps without the Bite!

by: Kyle Somers – Associate Solutions Architect
Let’s face it, managing servers is a pain! Capacity management and scaling is even worse. Now imagine dedicating your time to SysOps during a zombie apocalypse — barricading the door from flesh eaters with one arm while patching an OS with the other.
This sounds like something straight out of a nightmare. Lucky for you, this doesn’t have to be the case. Over at AWS, we’re making it easier than ever to build and power apps at scale with powerful managed services, so you can focus on your core business – like surviving – while we handle the infrastructure management that helps you do so.
Join the AWS Lambda Signal Corps!
At AWS re:Invent in 2015, we piloted a workshop where participants worked in groups to build a serverless chat application for zombie apocalypse survivors, using Amazon S3, Amazon DynamoDB, Amazon API Gateway, and AWS Lambda. Participants learned about microservices design patterns and best practices. They then extended the functionality of the serverless chat application with various add-on functionalities – such as mobile SMS integration, and zombie motion detection – using additional services like Amazon SNS and Amazon Elasticsearch Service.
In this post, I’ll show you how our survivor chat application incorporates some important microservices design patterns and how you can power your apps in the same way using a serverless architecture.
What Are Serverless Architectures?
At AWS, we know that infrastructure management can be challenging. We also understand that customers prefer to focus on delivering value to their business and customers. There’s a lot of undifferentiated heavy lifting to be building and running applications, such as installing software, managing servers, coordinating patch schedules, and scaling to meet demand. Serverless architectures allow you to build and run applications and services without having to manage infrastructure. Your application still runs on servers, but all the server management is done for you by AWS. Serverless architectures can make it easier to build, manage, and scale applications in the cloud by eliminating much of the heavy lifting involved with server management.
Key Benefits of Serverless Architectures
- No Servers to Manage: There are no servers for you to provision and manage. All the server management is done for you by AWS.
- Increased Productivity: You can now fully focus your attention on building new features and apps because you are freed from the complexities of server management, allowing you to iterate faster and reduce your development time.
- Continuous Scaling: Your applications and services automatically scale up and down based on size of the workload.
What Should I Expect to Learn at a Zombie Microservices Workshop?
The workshop content we developed is designed to demonstrate best practices for serverless architectures using AWS. In this post we’ll discuss the following topics:
- Which services are useful when designing a serverless application on AWS (see below!)
- Design considerations for messaging, data transformation, and business or app-tier logic when building serverless microservices.
- Best practices demonstrated in the design of our zombie survivor chat application.
- Next steps for you to get started building your own serverless microservices!
Several AWS services were used to design our zombie survivor chat application. Each of these services are managed and highly scalable. Let’s take a quick at look at which ones we incorporated in the architecture:
- AWS Lambda allows you to run your code without provisioning or managing servers. Just upload your code (currently Node.js, Python, or Java) and Lambda takes care of everything required to run and scale your code with high availability. You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app. Lambda is used to power many use cases, such as application back ends, scheduled administrative tasks, and even big data workloads via integration with other AWS services such as Amazon S3, DynamoDB, Redshift, and Kinesis.
- Amazon Simple Storage Service (Amazon S3) is our object storage service, which provides developers and IT teams with secure, durable, and scalable storage in the cloud. S3 is used to support a wide variety of use cases and is easy to use with a simple interface for storing and retrieving any amount of data. In the case of our survivor chat application, it can even be used to host static websites with CORS and DNS support.
- Amazon API Gateway makes it easy to build RESTful APIs for your applications. API Gateway is scalable and simple to set up, allowing you to build integrations with back-end applications, including code running on AWS Lambda, while the service handles the scaling of your API requests.
- Amazon DynamoDB is a fast and flexible NoSQL database service for all applications that need consistent, single-digit millisecond latency at any scale. It is a fully managed cloud database and supports both document and key-value store models. Its flexible data model and reliable performance make it a great fit for mobile, web, gaming, ad tech, IoT, and many other applications.
Overview of the Zombie Survivor Chat App
The survivor chat application represents a completely serverless architecture that delivers a baseline chat application (written using AngularJS) to workshop participants upon which additional functionality can be added. In order to deliver this baseline chat application, an AWS CloudFormation template is provided to participants, which spins up the environment in their account. The following diagram represents a high level architecture of the components that are launched automatically:
High-Level Architecture of Survivor Serverless Chat App

- Amazon S3 bucket is created to store the static web app contents of the chat application.
- AWS Lambda functions are created to serve as the back-end business logic tier for processing reads/writes of chat messages.
- API endpoints are created using API Gateway and mapped to Lambda functions. The API Gateway POST method points to a WriteMessages Lambda function. The GET method points to a GetMessages Lambda function.
- A DynamoDB messages table is provisioned to act as our data store for the messages from the chat application.
Serverless Survivor Chat App Hosted on Amazon S3
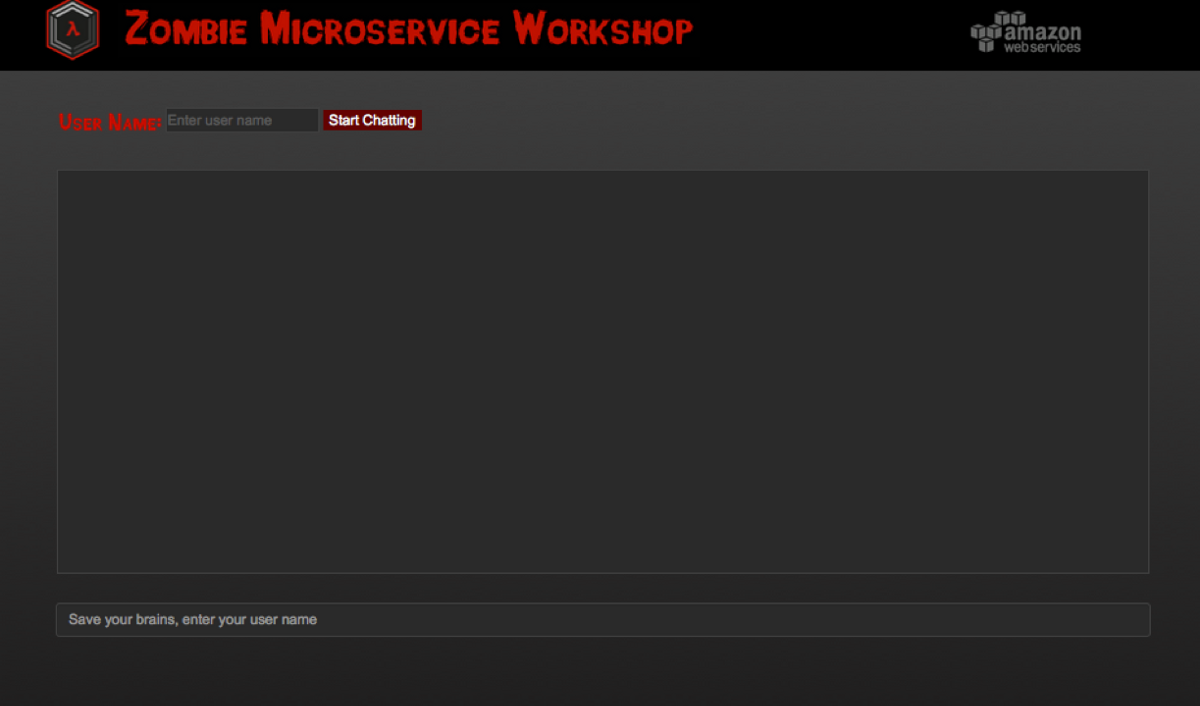
With the CloudFormation stack launched and the components built out, the end result is a fully functioning chat app hosted in S3, using API Gateway and Lambda to process requests, and DynamoDB as the persistence for our chat messages.
With this baseline app, participants join in teams to build out additional functionality, including the following:
- Integration of SMS/MMS via Twilio. Send messages to chat from SMS.
- Motion sensor detection of nearby zombies with Amazon SNS and Intel® Edison and Grove IoT Starter Kit. AWS provides a shared motion sensor for the workshop, and you consume its messages from SNS.
- Help-me panic button with IoT.
- Integration with Slack for messaging from another platform.
- Typing indicator to see which survivors are typing.
- Serverless analytics of chat messages using Amazon Elasticsearch Service (Amazon ES).
- Any other functionality participants can think of!
As a part of the workshop, AWS provides guidance for most of these tasks. With these add-ons completed, the architecture of the chat system begins to look quite a bit more sophisticated, as shown below:
Architecture of Survivor Chat with Additional Add-on Functionality

Architectural Tenants of the Serverless Survivor Chat
For the most part, the design patterns you’d see in a traditional server-yes environment you will also find in a serverless environment. No surprises there. With that said, it never hurts to revisit best practices while learning new ones. So let’s review some key patterns we incorporated in our serverless application.
Decoupling Is Paramount
In the survivor chat application, Lambda functions are serving as our tier for business logic. Since users interact with Lambda at the function level, it serves you well to split up logic into separate functions as much as possible so you can scale the logic tier independently from the source and destinations upon which it serves.
As you’ll see in the architecture diagram in the above section, the application has separate Lambda functions for the chat service, the search service, the indicator service, etc. Decoupling is also incorporated through the use of API Gateway, which exposes our back-end logic via a unified RESTful interface. This model allows us to design our back-end logic with potentially different programming languages, systems, or communications channels, while keeping the requesting endpoints unaware of the implementation. Use this pattern and you won’t cry for help when you need to scale, update, add, or remove pieces of your environment.
Separate Your Data Stores
Treat each data store as an isolated application component of the service it supports. One common pitfall when following microservices architectures is to forget about the data layer. By keeping the data stores specific to the service they support, you can better manage the resources needed at the data layer specifically for that service. This is the true value in microservices.
In the survivor chat application, this practice is illustrated with the Activity and Messages DynamoDB tables. The activity indicator service has its own data store (Activity table) while the chat service has its own (Messages). These tables can scale independently along with their respective services. This scenario also represents a good example of statefuless. The implementation of the talking indicator add-on uses DynamoDB via the Activity table to track state information about which users are talking. Remember, many of the benefits of microservices are lost if the components are still all glued together at the data layer in the end, creating a messy common denominator for scaling.
Leverage Data Transformations up the Stack
When designing a service, data transformation and compatibility are big components. How will you handle inputs from many different clients, users, systems for your service? Will you run different flavors of your environment to correspond with different incoming request standards? Absolutely not!
With API Gateway, data transformation becomes significantly easier through built-in models and mapping templates. With these features you can build data transformation and mapping logic into the API layer for requests and responses. This results in less work for you since API Gateway is a managed service. In the case of our survivor chat app, AWS Lambda and our survivor chat app require JSON while Twilio likes XML for the SMS integration. This type of transformation can be offloaded to API Gateway, leaving you with a cleaner business tier and one less thing to design around!
Use API Gateway as your interface and Lambda as your common backend implementation. API Gateway uses Apache Velocity Template Language (VTL) and JSONPath for transformation logic. Of course, there is a trade-off to be considered, as a lot of transformation logic could be handled in your business-logic tier (Lambda). But, why manage that yourself in application code when you can transparently handle it in a fully managed service through API Gateway? Here are a few things to keep in mind when handling transformations using API Gateway and Lambda:
- Transform first; then call your common back-end logic.
- Use API Gateway VTL transformations first when possible.
- Use Lambda to preprocess data in ways that VTL can’t.
Using API Gateway VTL for Input/Output Data Transformations
![]()
Security Through Service Isolation and Least Privilege
As a general recommendation when designing your services, always utilize least privilege and isolate components of your application to provide control over access. In the survivor chat application, a permissions-based model is used via AWS Identity and Access Management (IAM). IAM is integrated in every service on the AWS platform and provides the capability for services and applications to assume roles with strict permission sets to perform their least-privileged access needs. Along with access controls, you should implement audit and access logging to provide the best visibility into your microservices. This is made easy with Amazon CloudWatch Logs and AWS CloudTrail. CloudTrail enables audit capability of API calls made on the platform while CloudWatch Logs enables you to ship custom log data to AWS. Although our implementation of Amazon Elasticsearch in the survivor chat is used for analyzing chat messages, you can easily ship your log data to it and perform analytics on your application. You can incorporate security best practices in the following ways with the survivor chat application:
- Each Lambda function should have an IAM role to access only the resources it needs. For example, the GetMessages function can read from the Messages table while the WriteMessages function can write to it. But they cannot access the Activities table that is used to track who is typing for the indicator service.
- Each API Gateway endpoint must have IAM permissions to execute the Lambda function(s) it is tied to. This model ensures that Lambda is only executed from the principle that is allowed to execute it, in this case the API Gateway method that triggers the back end function.
- DynamoDB requires read/write permissions via IAM, which limits anonymous database activity.
- Use AWS CloudTrail to audit API activity on the platform and among the various services. This provides traceability, especially to see who is invoking your Lambda functions.
- Design Lambda functions to publish meaningful outputs, as these are logged to CloudWatch Logs on your behalf.
FYI, in our application, we allow anonymous access to the chat API Gateway endpoints. We want to encourage all survivors to plug into the service without prior registration and start communicating. We’ve assumed zombies aren’t intelligent enough to hack into our communication channels. Until the apocalypse, though, stay true to API keys and authorization with signatures, which API Gateway supports!
Don’t Abandon Dev/Test
When developing with microservices, you can still leverage separate development and test environments as a part of the deployment lifecycle. AWS provides several features to help you continue building apps along the same trajectory as before, including these:
- Lambda function versioning and aliases: Use these features to version your functions based on the stages of deployment such as development, testing, staging, pre-production, etc. Or perhaps make changes to an existing Lambda function in production without downtime.
- Lambda service blueprints: Lambda comes with dozens of blueprints to get you started with prewritten code that you can use as a skeleton, or a fully functioning solution, to complete your serverless back end. These include blueprints with hooks into Slack, S3, DynamoDB, and more.
- API Gateway deployment stages: Similar to Lambda versioning, this feature lets you configure separate API stages, along with unique stage variables and deployment versions within each stage. This allows you to test your API with the same or different back ends while it progresses through changes that you make at the API layer.
- Mock Integrations with API Gateway: Configure dummy responses that developers can use to test their code while the true implementation of your API is being developed. Mock integrations make it faster to iterate through the API portion of a development lifecycle by streamlining pieces that used to be very sequential/waterfall.
Using Mock Integrations with API Gateway

Stay Tuned for Updates!
Now that you’ve got the necessary best practices to design your microservices, do you have what it takes to fight against the zombie hoard? The serverless options we explored are ready for you to get started with and the survivors are counting on you!
Be sure to keep an eye on the AWS GitHub repo. Although I didn’t cover each component of the survivor chat app in this post, we’ll be deploying this workshop and code soon for you to launch on your own! Keep an eye out for Zombie Workshops coming to your city, or nominate your city for a workshop here.
For more information on how you can get started with serverless architectures on AWS, refer to the following resources:
Whitepaper – AWS Serverless Multi-Tier Architectures
Reference Architectures and Sample Code
*Special thanks to my colleagues Ben Snively, Curtis Bray, Dean Bryen, Warren Santner, and Aaron Kao at AWS. They were instrumental to our team developing the content referenced in this post.