Networking & Content Delivery
Slashing CloudFront change propagation times in 2020 – recent changes and looking forward
As a Senior Product Manager of Amazon CloudFront, I have the privilege of an insider’s view into everything our developers do for the service. From this viewpoint, I can see that much of what our developers do on the service is not something we talk about externally. This is because their work often involves security and availability improvements that are either confidential or are a fundamental expectation to uphold. Similarly, we don’t generally talk externally about performance improvements but for somewhat different reasons. For the most part, we’ve not discussed performance gains externally because we never view the job as finished. There’s always more work to be done and we’re always setting more aggressive goals and looking towards the next milestone.
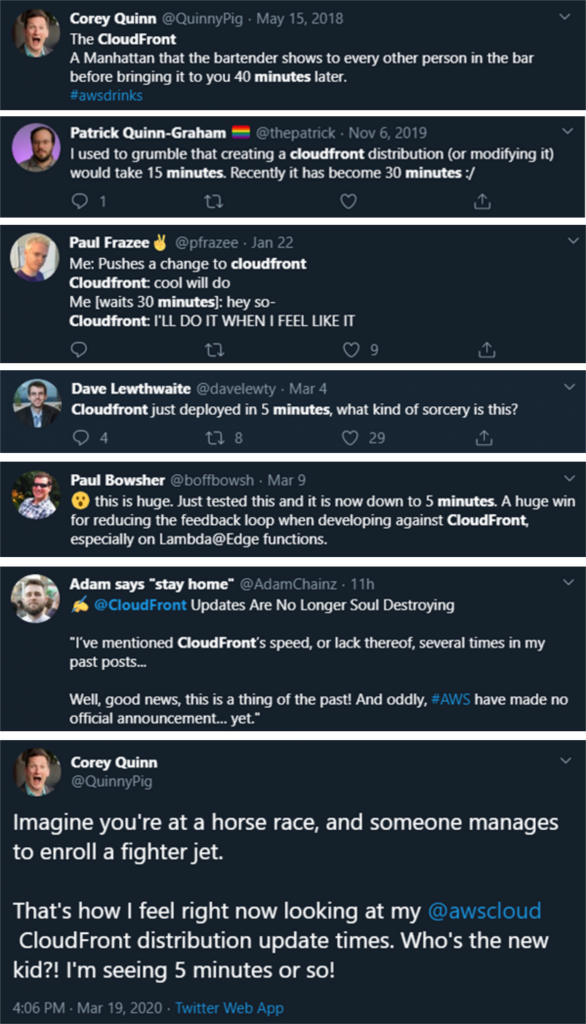
Recently, we made a series of back-end changes that dramatically improved the time it takes to deploy configuration changes through our entire network. Having noticed this improvement, many of you commented in various social media channels about the pleasant surprise but were left somewhat confused as to why we made no official announcement. These improvements fall into this same category of never being finished. We ourselves take on the mantra of being “divinely discontent” with the status quo and are continually seeking to raise the bar. We knew these changes would be significant and that customers would clearly notice the difference, but we did not want to give even the slightest degree of indication that we viewed the project as mission accomplished.
Reducing change propagation time is, and continues to be, one of our team’s primary goals for 2020.
So what changed, and where are we going in 2020? First, let’s look at how we got here in the first place.
A bit of history and context
Over the past few years, we’ve seen tremendous growth for the service. The pace at which the service continues to accelerate in terms of the number of customers, the amount of bytes served, the record traffic peaks we continually set for ourselves, and the infrastructure we continue to deploy has been staggering on all fronts.
From the time that CloudFront launched, up until the point we hit our first million distributions (generally speaking a distribution represents a hosted domain on CloudFront), deploying configuration changes was accomplished by packaging the configuration database in a flat file called a parcel and shipping it to all Edge locations around the world. As that system approached its limitations we moved to a hybrid, diff-based system that incorporated periodic snapshots of the entire database along with parcels that only contained the new configurations recently changed.
CloudFront has always maintained the standard that we do not call change propagation done until we can confirm every host in every Edge location around the world has received the new configuration parcel. We’ve never made an exception to this rule even though >90% of Edge locations receive the parcel within seconds and already operate under the new configuration while we’re waiting on the final confirmation from the last host to report back. Waiting until every in-service host gets this new configuration is the only way that we can guarantee a deterministic behavior across the entire network. This is important in workflows like deploying a new version of a website in a fully automated process without the risk of an older version of an asset getting cached under the wrong configuration.
Recent changes driving the improvement
Over the past couple of months we’ve deployed a series of changes that significantly reduced the average change propagation time as well as the spikes that made it “soul destroying” as some would put it. Instead of change propagation times that averaged between 17 and 35 minutes, we’re now at a point where we are reliably pushing these changes within 5 minutes.

To give a little bit of insight into what drove these improvements, we’ve summarized three of the changes that produced the most notable reductions.
Improved DNS service
First, we made several improvements to our Edge DNS services. DNS hosts used to report back version numbers of the configuration changes being ingested, as well as the configuration file that was last used to build its IP lists and sent to the DNS hosts. We simplified this process by removing unnecessarily complex checks while still maintaining the robustness in keeping everything in sync. The resulting impact of these optimizations cut the time involved in these configuration updates by 50%.
Eliminated two-step propagations
Second, when we first built Dedicated IP for Legacy Client Support for SNI-less connections, we needed a way to ensure that we kept custom certificates and IP list associations in sync before the changes made their way to the DNS hosts. This involved a two-step process in which we first made these associations and then propagated the change to the DNS host. This process was unnecessarily applied to new distributions being created with custom certificates using Shared IP addresses. For these standard distributions using Shared IP addresses, connections don’t need to rely on associations between specific IP addresses and certificates because the correct certificate can be returned using the SNI extension to keep requests separate. This means that for new distributions created with a custom certificate, change propagation times were reduced by 50%.
Eliminated snapshots
Lastly, we eliminated the need to rely on snapshots of the entire configuration database at the Edge location and moved to a purely diff-based system. Previously, replacing the snapshot at each Edge location caused each location to temporarily pause the consumption of new diff files as a means of reducing the load when processing these multi-gigabyte snapshot files. As our service has grown in the number of customers and distribution configurations, so too did the size of the snapshots. This meant that over time the temporary pauses became longer and longer. We have since stopped shipping snapshots to the Edge locations and moved on from the hybrid system to a pure diff-based one.
Looking forward and continuing to listen
We are pleased with the recent progress we’ve made, but we want to emphasize that our job is not yet done. There is more work to be done and more ambitious goals to achieve. We’ve heard loud and clear what the expectations are and we aspire to get there as soon as we can. We have a dedicated team continuing to work on improving the performance and reliability of our change propagation times. The changes discussed in this blog are a product of their work so far and we are all looking forward to what will come throughout the year.
We know this has been a source of pain for too long, and we’re not proud of the types of tweets that arose out of this situation, some of which you can see below. However, we are encouraged by the fact that so many have noted the difference and we’re looking forward to making this even better as we continue this journey.
(Timeline of tweets from the pain of years past to the relief of recent improvements)