Amazon Web Services ブログ
製造業の拠点の在庫管理をサプライチェーンのデータレイクで改善
課題
製造業では地理的にばらばらに離れた拠点に製品を配送し、在庫を管理します。この管理において仕入れのタイミングや数量を正しく予想することは難しい課題です。たとえば、化学製品の工場は VMI(ベンダーによる在庫管理)により、数千もの遠隔の貯蔵タンクが既に空になってしまったり(この場合は供給が遅すぎる)、もしくはタンクの在庫レベルがまだまだある(この場合は供給が必要ない)時に、運搬トラックを派遣するかどうかが契約で既に決まっていたりします。同じように自動車のスペアパーツのメーカーがディーラーの注文通りに発送できなければ、消費者の期待を裏切ることなるでしょう。仕入れが多すぎたり、少なすぎたり、時間がかかりすぎたりなどの適切ではない場合、皆の問題となりえます。
大抵の在庫補充計画において、タイムリーで正しく、包括的で標準化されたデータが一か所にまとまってはいない点がこの課題での難所となります。製造業のエンタープライズ・リソース・プランニング(ERP)システムには大抵の場合、消費量があまり多くない拠点をモデル化するための、適切な詳細度の情報がありません。このことが最適な在庫補充タイミングを予想する際に大きな問題となっています。その結果、現場のチームが拠点の在庫と補充をモデル化したデータを、表計算ソフトやサイロで運用された内製のシステムで組み上げようとし、それによってマスターデータ(拠点の位置や在庫補充にかかる時間や、仕入れの保管ポリシー)または取引のデータ(在庫レベルや販売)がバラバラになる問題が発生します。この結果、不適切な在庫補充計画や、コストがかかる手動のデータ取得や管理、また予測の作業が発生します。
包括的なアプローチ
このブログシリーズでは 4 つのブログでこの課題に取り組みます。各々のブログで問題の解決のためのキーとなる要素を提示します。この最初のブログでは、分散したデータをまとめて正規化されたサプライチェーンのデータレイクをどのようにまとめ上げられるか、を説明します。次のブログでは、サプライチェーンのデジタルツインを使用してどのように物理的な製品フローを視覚的にモデル化するか、そして情報豊富なサプライチェーンのデータレイクにどうやって育て上げるかについて説明します。3 つ目のブログでは、デジタルツインの上位レイヤで、仕入れ計画のアプリケーションをどのように開発していくか、そして最後のブログでは LoRaWAN などの IoT 技術を使用して、広範囲に分散しデータ取得が難しい拠点からデータを取り、どのように自動的に、コスト効率よく、頻度が高く粒度の細かいデータを使用して、データレイクにデータを注入するかについて説明します。
図1は、この4つの要素が相互作用で在庫補充の課題をどう解決するかを示しています。
- サプライチェーンのデータレイク
- サプライチェーンのデジタルツイン
- 補充計画などのアプリケーション
- IoT データの取得
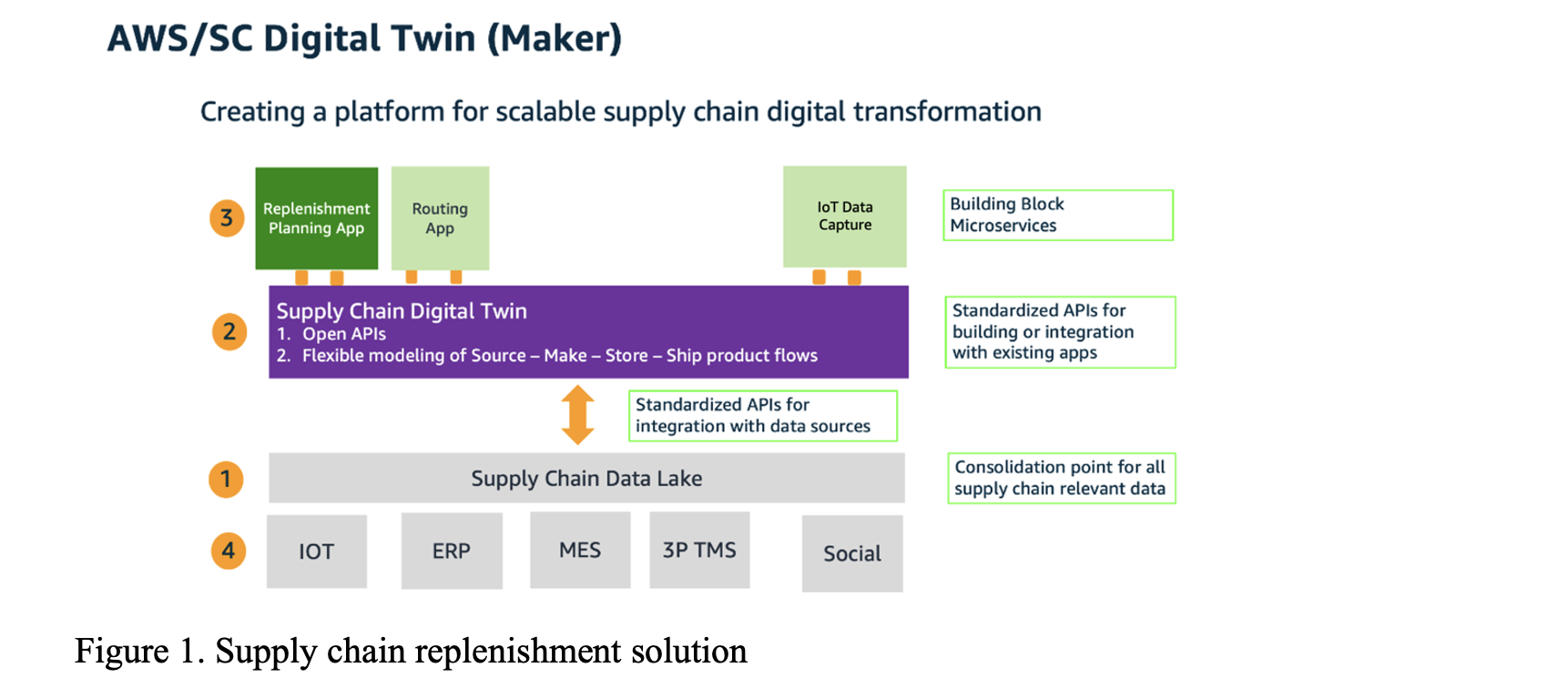
図1. サプライチェーンの在庫補充ソリューション
図 2 ではサプライチェーンデータレイクの詳細のアーキテクチャ図です。タイムリーで正確に、また包括的で標準化されたデータが統一されていることにより、サプライチェーンのデジタルツイン、アプリケーション、そして IoT の 3 つの要素をどのように統合できるかを示しています。

図2. サプライチェーンデータレイクのアーキテクチャ
サプライチェーンにおけるデータレイク構築の課題
サプライチェーンにおけるデータレイクは、データを収集し、意味づけをして、成形し、多くのデータソースからデータを集積する必要があります。これらのデータソースは、配送のための保管量レベル、売り上げ、管理対象とする製品、また補充予測に必要となる目標保管量レベルのデータを持ちます。
このことにより、2 つの課題が浮上します。
- 膨大な量のデータを社内と顧客とパートナーからコスト効率高く受け取る必要がある
- 大量の異なるデータフォーマットを共通の基本データで使用できるよう正規化し、意味づけする必要がある
上記が達成できたとしても、次に 3 つ目の課題があります。
- 組織の内外の数十~数百人のユーザーのユーザーがデータレイクにアクセスするため、行/列/セルレベルなどで様々なアクセス要件をもつ複雑なセキュリティとアクセス管理をする必要がある
最後に 4 つ目の課題があります。
- 拡大を続けるユースケース、たとえば補充計画からルート最適化、あるいはアプリケーションの導入に伴う新規の製品計画といった複数のユースケースで用いるために、サプライチェーンデータレイクの品質や一貫性を保ち続けること
課題を解決するためのアーキテクチャ
上記 4 つの課題を解決するためには Amazon Web Services (AWS) でどのようにアーキテクティングすればよいのかを見ていきましょう。
様々なデータソースから収集してデータを正規化する
最初は多数のデータソースとやりとりする課題です。鍵となるのは、データ元のシステムが実行できるシンプルで、ドキュメントがしっかりしていて、また標準化されている API を提供することです。要件を分析し各々のシステムのデータソースごとにシステム統合を設計構築することは、組織内のデータソースでもコストが高くなるのは言うまでもなく、社外の膨大な数のデータソース--配送業者や、小売業者、配送業者や港や電車の車庫、トラック、駐車場その他ーーになると、法外なほどコストが高くなります。これらは典型的にはサプライチェーンにおける購買と販売、そして移動の業務に影響します。Amazon API Gateway ——開発者が安全に API を作成して公開し、メンテナンスしてモニターすることをどのような規模でも簡単にできる完全にマネージドサービス——は、サーバーレスでイベント駆動の処理サービスである AWS Lambda の関数にデータを渡すことにより、サプライチェーンのデータを収集する標準的な API を作り、さらに発展させることができます。AWS Lambda の関数はデータを Amazon Simple Storage Service (Amazon S3) のオブジェクト形式のバケットに保存された、サプライチェーンのデータレイクに保存する前に、データの正当性チェックと成形を最初の段階で行うことができます。
多くのデータソースからのデータは共通の API で収集できますが、もしかしたらデータソースによっては、密接な統合方法が効率的だったり、元システムを API へのデータ送信ができる様に変更するのが難しい場合もあります。そのような場合、AWS Lambda の関数がこういったシステムのインターフェイスからデータを取り出すことができます。個別の対応を最小限にとどめることにより、結果的には拡張性もコスト効率もよい、サプライチェーンのデータレイクを成長させることが出来ます。
E メールで在庫の注文状況を報告したい社外のパートナーは、 Amazon Simple Email Service (Amazon SES)を使用してコスト効率がよく柔軟性が高く、大規模な利用が可能なメールサービスを生かしてデータの統合を自動化できます。また Amazon Textract は、機械学習(ML)のサービスで自動的に文字列、手書き文字とデータを画像ファイルから抽出します。これらを使用して Email の添付ファイルからのデータ処理が可能になります。Amazon Comprehend は、自然言語処理(NLP)サービスで、取引に関する属性をテキストから識別して取得することができます。
似たような活用法では、AWS Lambda 関数はデータを Microsoft Excel などの Email の添付ファイルから抽出できます。その出力結果に対して共通 API を呼び出し、Amazon S3 の生データのバケットにあるサプライチェーンのデータレイクへデータを流すことになります。
ERP のシステムでは完全にマネージドの統合サービスの Amazon AppFlow が SAP や Salesforce やその他の ERP との統合を加速し、フィルタやデータの整合性チェック、変換やマッピング用のコネクタを提供します。重要なデータ入力から在庫補充の予測や計画への、安全で機密性のあるデータフロー確立します。
データを収集するためのスケール可能なアーキテクチャを設計すると、続いて二つ目の課題に直面します。データフォーマット毎で異なる意味付けがある、巨大な量のデータを正規化しなければいけません。視覚的に操作できるデータ準備のための最新のツールである AWS Glue DataBrew は、このタスクで価値を発揮します。視覚的にデータ準備とデータの成形や正規化をコードを書かずに行うことができます。複数の ERP のシステムや顧客やパートナーのデータから持ってきて、データを標準化するだけではなく、サプライチェーンにおけるセンシングなど IoT 機器から新たに自動的に取得されたデータがあった場合、それらに情報を付与をしたり正規化したりすることができます。非常に多くのデータソースから取得されたデータをチェックし、成形し、意味づけをして変換した後、情報整理用の S3 バケットにその結果を保存するための中心となるサービスです。
アクセスを管理する
さてサプライチェーンのデータレイクのデータを正規化して、必要なデータソースから詳細情報を意味づけをしたうえで、データを集積して Amazon S3 の情報整理されたバケットに保存できました。次の課題はアクセスを管理し、必要な要員がビジネス目的を達成するためにのみアクセス可能になるよう、管理しなければなりません。要員の範囲が拡がっていく状況で、特定の行やカラムやセルといった必要対象のデータへのアクセスのみに絞ることを考えると、これは相当大きな課題となりえます。サプライチェーンの成長と、新規のビジネス要件やビジネス機会に対応するための変更 によって、この課題はさらに大きくなります。
AWS Lake Formationでは、セキュアなデータレイクを簡単に構築できます。 サーバーレスのデータ統合サービスである AWS Glue の機能を使い、AWS Lake Formation では直感的に一気通貫でパワフルなサプライチェーンのデータレイクを構築できます。そしてこのデータレイクは最初から業界のベストプラクティスや標準コンプライアンスが考慮されていています。また AWS Lake Formation は多くの機能を提供し、サプライチェーンのデータレイクのセットアップの一部として最初から組み込まれるべきガバナンスを、以下の最低限の設定で提供します。
1.ロールとユーザーグループによる権限管理 — 組織の成長に合わせてユーザーを追加・削除できるように、 ロールは必要なアクセスコントロールポリシーで定義され、ユーザーグループに適用されます。
2.行、カラム、セルの単位でのアクセス許可 — AWS Lake Formation は個人特定可能な情報(PII)などの機微情報をきめ細やかなレベルでアクセスを制限するデータのフィルタ を提供し、シンプルで統一されたアクセスの管理を可能にします。
3.暗号化と鍵管理 — データレイクに保存されているデータのどれが暗号化保存されるべきか、送受信されるデータがどの時点で暗号化されるべきかというポリシーを鑑み、暗号化の設定がされなければなりません。AWS Lake Formation はセキュリティ設定におけるこうした側面を簡単に実施することができます。
4.重複排除— AWS Lake Formation は、FindMatches というデータ変換機能を持ち、これは機械学習により重複データ排除を支援します。FindMatches では、ユーザーが重複したレコードにラベルを付けると、既存サンプルを元に、大規模に重複データを取り除くための条件を学習します。これにより 4 つ目の課題であるデータ品質の一貫性を保つことができます。
5.パーティショニング — パーティショニングはコストとパフォーマンス両方に影響します。そのため、データの性質とアクセスパターンをもとに最適なパーティショニングをすることは大変重要です。
AWS Lake Formation は AWS インフラストラクチャ内での組織全体でアカウントでの動向をモニタし記録する AWS CloudTrail と統合されています。監査の記録のため構築初期から監査ログに基づいた監視とレポート機構を設定した方が良いでしょう。
また、AWS Lake Formation のデータ収集のためのテンプレートを使って、MySQL、PostgreSQL、Oracle、SQL Server といったデータベースや一般的なログファイルのフォーマットから、サプライチェーンのデータレイクにデータを取り込む最初の一歩を簡単に踏み出すことができます。
データレイクのメンテナンス
セキュアなデータレイクを構築した後、もう一つの課題があります。新しいデータソースやユーザーが追加されて新しいユースケースに対応するにつれて、データレイクが汚濁したデータの沼地になってしまわないようにすることです。たとえば、経路の最適化や製品の計画、または新しい顧客や新しいパートナーとの連携などのユースケースの追加が、この問題を引き起こす可能性があります。
データレイクが成長しても、正常で透明性をもったデータレイクを維持するための鍵は、ガバナンスを効かせ続け、運用のベストプラクティスに従った運用を、自動化されたモニタリング、アラートや自動修復の設定により実施することです。すでに AWS Lake Formation によりガバナンスを効かせることができるとご紹介しました。さらにロールとユーザーグループを明確で拡張可能なように維持し続けることにより、アクセスポリシーの適用が簡単になります。また、AWS Lake Formation のタグを使用した管理 (LF-TBAC) により、ロールとユーザーグループを明確で拡張可能なように維持し続けることにより、簡単に新しいドメインやユーザー群をデータレイクに取り込むことを可能にして、急速に拡大するデータレイクのメンテナンスの手助けになります。この作業は簡単で、同じタグを新しいユーザーとそのユーザーがアクセス可能なオブジェクトに追加するだけです。
最後に、AWS CloudWatch のアラートとアラームは重要なメトリクスと通知を提供します。また日常的なメンテナンスや調整が必要な時に自動でアクションを取り、データレイクの健常な運用を可能にします。AWS Config は、AWS リソースの設定をして査定し、監査し、そして評価するサービスですが、ポリシーを遵守するよう導き、運用のベストプラクティスへの準拠させることによりデータレイクの監視と一貫性を維持する支援をします。AWS Config template for data lakes で簡単にスタートを切れますし、カスタマイズして、監視やレポートの出力や長期的にデータレイクの荒廃につながるような状況の修正を行うことができます。
結論
Well-Architected に準拠し管理されたデータレイクは、配送の計画が難航している組織に対し、即座に大きな価値を提供します。組織の持つデータのサイロを解体し、データが中央管理され、情報が付加され、清浄化され、正規化されれば、組織は継続的に、また効率的にインサイトを得ることが出来ます。たとえば Amazon Athena でインタラクティブなクエリを実行したり、クラウド上でのビッグデータのプラットフォームである Amazon EMR を使用したりなどが可能となります。 Amazon OpenSearch Service — インタラクティブなログの分析やニアリアルタイムのアプリケーションのモニタリングやウェブサイトの検索等を行うことを簡単にするサービス — などのアナリティクスのサービスも使用できます。また AI や ML のサービス、たとえば Amazon SageMaker で機械学習モデルを構築して学習してデプロイするといったサービスを活用することもできます。Amazon Forecast は時系列の予測サービスです。Amazon Comprehend は Amazon S3 の情報が整理されたバケット内のデータを読み込むことができます。
このシリーズの次のブログでは、情報整理されたデータが、どのようにデータレイクの中で、単純化された製造フローをサプライチェーンのデジタルツインの中で表現するか、そしてどのように配送の問題を解決するかについて議論したいと思います。
さらにこのシリーズにご興味があれば、Rajesh Mani と Shaun Kirby にご連絡いただくか、皆様のアカウント担当者にご連絡ください。
 |
Shaun KirbyShaun KirbyはIoTとロボティクスを専門とするのAWSプロフェッショナルサービスのプリンシパルカスタマーデリバリーアーキテクトです。クラウドでのお客様の成功を導き、ビジネスでの課題に深掘りし、各業種での画期的なソリューションを開発います。 |
 |
Rajesh ManiRajesh ManiはAWSのサプライチェーンのソリューションのリーダーでサプライチェーンのソリューションの構築と市場開拓を専門としています。お客様のサプライチェーンを変革に25年以上の経験を持ち、サプライチェーンの計画と運用、IoTとお客様体験においてソリューションのデザインをしています。 |
翻訳は Solutions Architect の伊藤ジャッジが担当しました。原文はこちらです。