Category: Amazon Rekognition
Amazon Rekognition – 유명인사 인식 기능 출시
지난 AWS re:Invent 행사에서 Amazon Rekognition를 정식 출시한 후, 이미지 관리 기능을 추가하였습니다. 오늘 유명인사 인식 기능을 출시하였습니다!
유명인사 인식 기능은 정치, 스포츠, 엔터테인먼트, 비즈니스 및 미디어 분야에서 유명하거나 주목할 만한 저명 인사가 있는 수십 만 명의 사람들을 확인하도록 훈련된 결과로서 자주 업데이트됩니다.
본 기능을 사용하려면 새로운 RecognizeCelebrities 함수를 호출하면 됩니다. 기존 DetectFaces 함수에서 얼굴 내 상자 및 랜드 마크 기능 외에도 유명 인사에 대한 정보를 반환합니다.
Urls은 유명인에 대한 추가 정보를 제공합니다. API는 현재 IMDB 콘텐츠에 대한 링크를 반환합니다. 앞으로 다른 출처를 추가 할 수 있습니다. AWS 관리 콘솔에서 Celebrity Recognition Demo를 사용하여이 기능을 시험해 볼 수 있습니다.
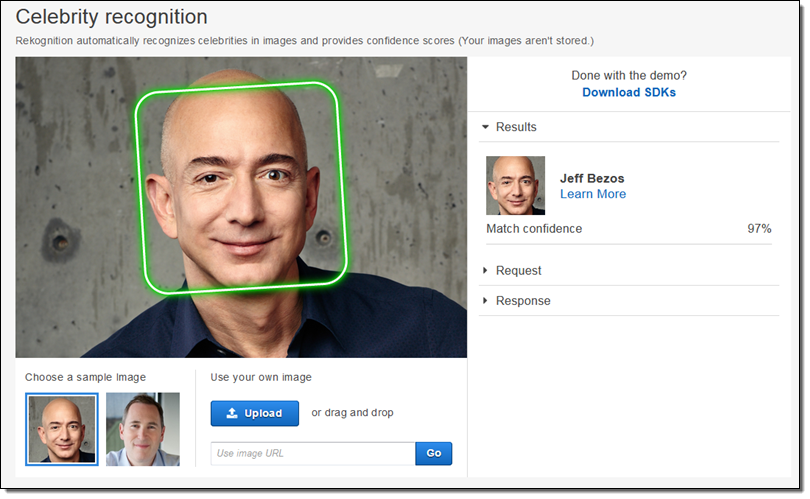 이미지 아카이브가 있는 경우, 유명 인사 별로 색인을 생성 할 수 있습니다. 유명 인사 인식과 개체 검색을 결합하여 모든 종류의 검색 도구를 구축 할 수도 있습니다. 이미지가 이미 S3에 저장되어있는 경우, 해당 이미지를 내부에서 처리 할 수 있습니다.
이미지 아카이브가 있는 경우, 유명 인사 별로 색인을 생성 할 수 있습니다. 유명 인사 인식과 개체 검색을 결합하여 모든 종류의 검색 도구를 구축 할 수도 있습니다. 이미지가 이미 S3에 저장되어있는 경우, 해당 이미지를 내부에서 처리 할 수 있습니다.
여러분도 새로운 기능에 대한 모든 흥미로운 사용 방법에 대한 아이디어를 생각해 보세요!
— Jeff;
Amazon Rekognition – 이미지 관리 및 Amazon Polly – 음성 표식 및 속삭임 생성 기능 업데이트
지난 re:Invent 2016 행사에서 개발자들이 손쉽게 스마트 애플리케이션을 개발할 수 있는 딥러닝 기반의 이미지 인식 서비스인 Amazon Rekognition과 Amazon Polly 및 Amazon Lex 등을 출시하였습니다. 이들 인공 지능 서비스에 최근 새로운 기능을 추가하였습니다. 이 글에서는 최근 업데이트 기능에 대해 간단하게 알아보겠습니다.
Amazon Rekognition에 이미지 관리 기능
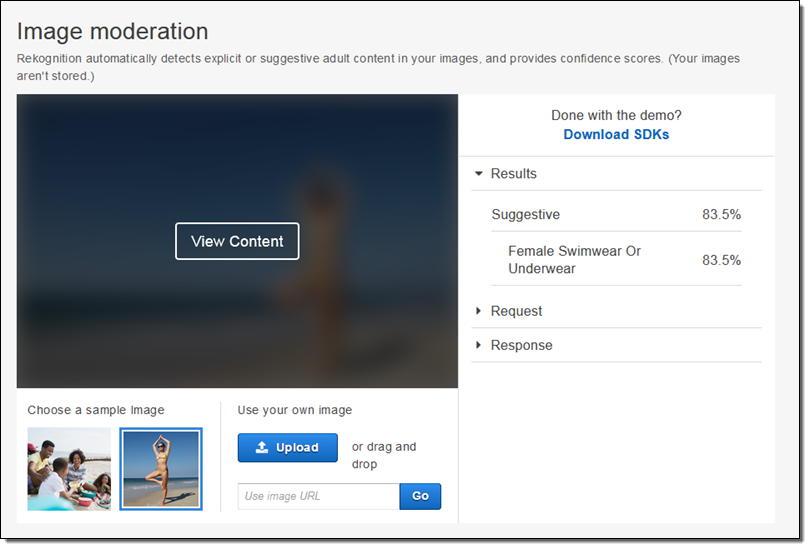
사용자가 프로필 사진에 대해 올린 경우, 사진이 적합하지 않은 콘텐츠인 경우 이미지를 식별할 수 있습니다. 상세한 레이블을 통해 허용 이미지 종류를 결정하는 미세 필터를 조정할 수 있습니다.
본 기능을 활용하려면 DetectModerationLabels 함수를 호출하면, 아래와 같은 응답을 통해 활용 가능합니다.
더 자세한 것은 Image Moderation 데모 기능을 통해 확인할 수 있습니다.
Amazon Polly 음성 표식 기능 및 속삭임 기능 출시
음성 표식(SppechMark) 기능은 개발자가 음성을 시각적 경험과 동기화 할 수 있습니다. 이 기능을 사용하면 음성을 얼굴 애니메이션과 동기화하거나 말한대로 단어의 강조 표시를 사용하여 립싱크와 같은 시나리오를 만들 수 있습니다. 음성 표식 메타 데이터는 합성된 음성을 설명하고 음성 오디오 스트림과 함께 사용함으로써 사운드, 단어, 문장 및 SSML 태그의 시작과 끝을 결정할 수 있습니다. 개발자는 립싱크 아바타를 만들고, 시각적으로 읽은 경험을 강조하고, Amazon Lumberyard와 같은 게임 엔진에 음성 기능을 통합하여 캐릭터에게 음성을 제공 할 수 있습니다.
네 가지 유형의 음성 표시가 있습니다.
- 문장 : 입력 텍스트에서 문장 요소를 지정합니다.
- 단어 : 입력 텍스트의 단어 요소를 나타냅니다.
- Viseme : 말한 소리에 해당하는 얼굴과 입의 위치를 보여줍니다.
- SSML (Speech Synthesis Markup Language) : SSML 입력 텍스트에서 <mark> 요소를 설명합니다.
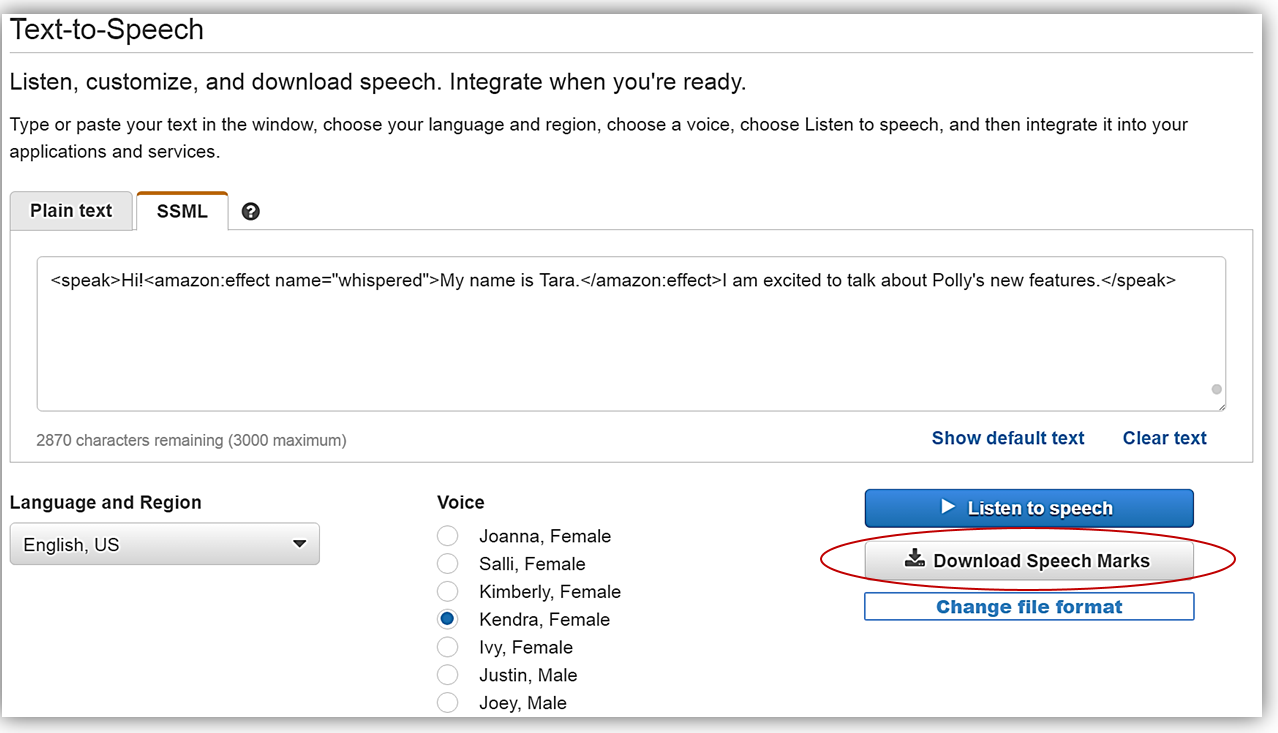
Amazon Polly에서 Change file format을 누른 후, File Format 옵션에서 Speech Marks를 선택합니다. Change 버튼을 눌러서 다운로드 포맷을 바꿀 수 있습니다.
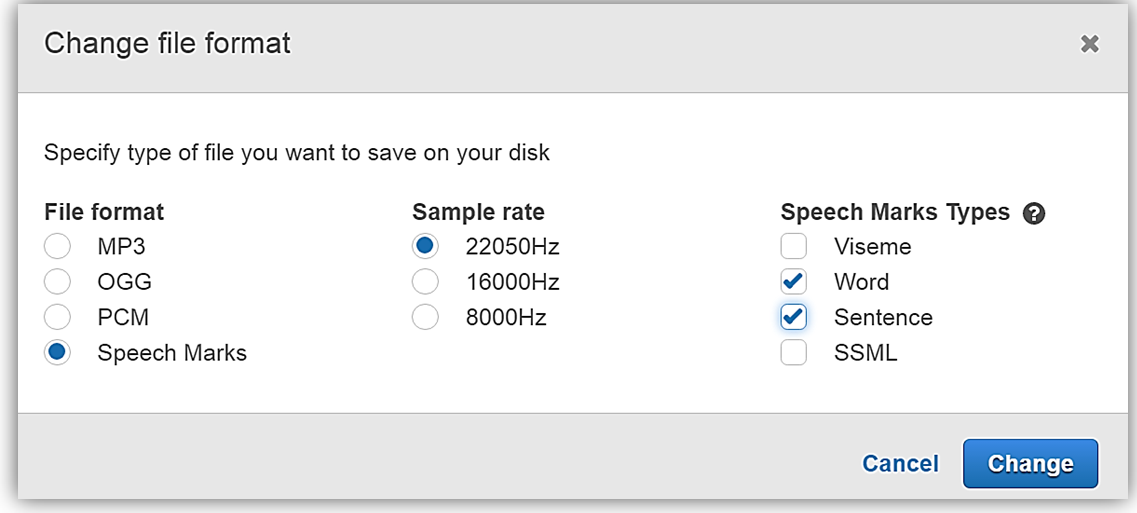
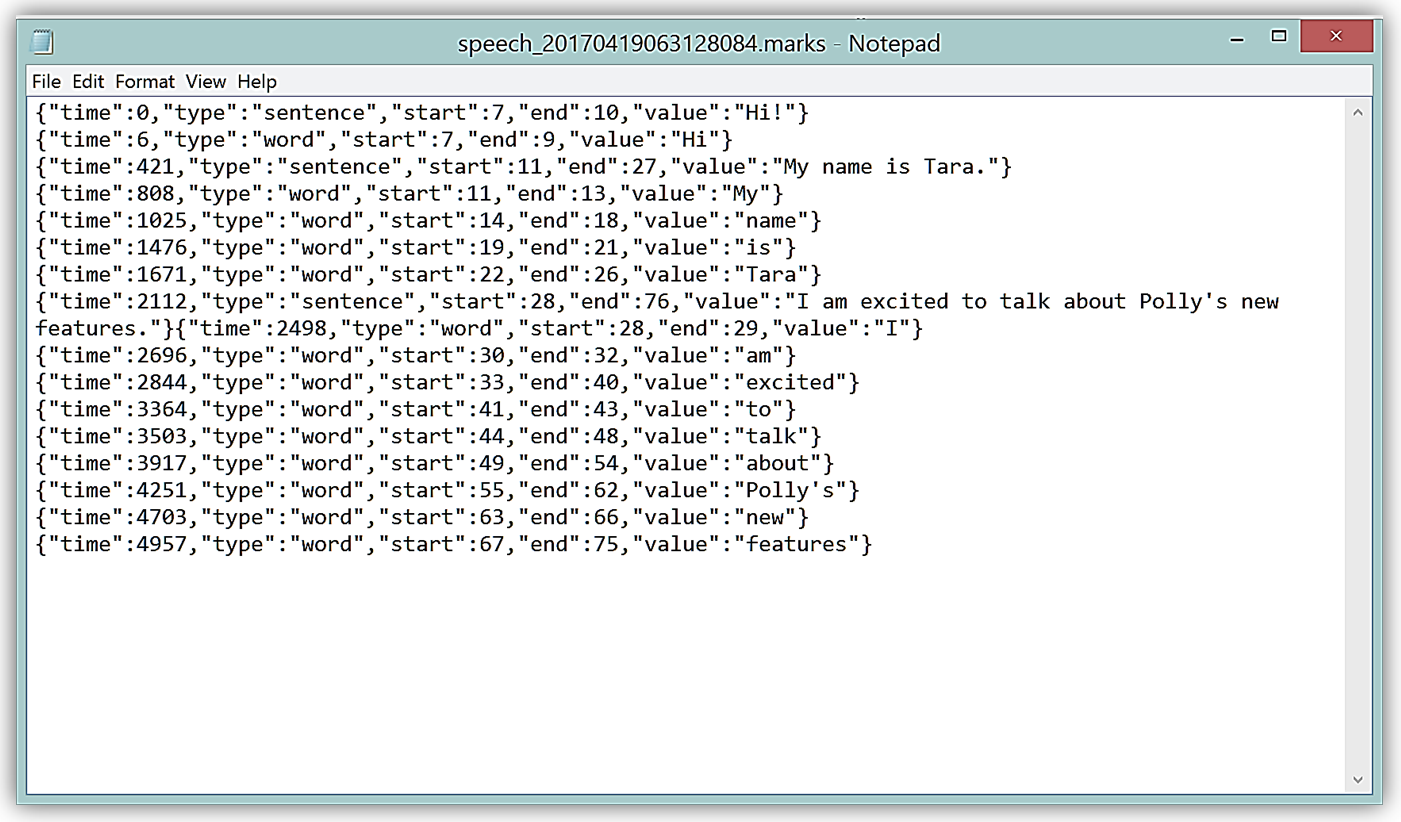
다운로드를 하면, 다음과 같이 음성 표식이 있는 텍스트 파일을 다운로드 할 수 있습니다.
속삭임 기능은 개발자가 Text-to-Speech 출력을 수정할 수있는 표현형 음성 기능에서 피치, 템포 및 소리 크기에 대한 음성 효과입니다. 속삭이는 기능을 사용하면 개발자는 <amazon:effect name=”whispered”> SSML 요소를 사용하여 속삭이는 음성으로 말한 입력 텍스트의 단어를 가질 수 있습니다.
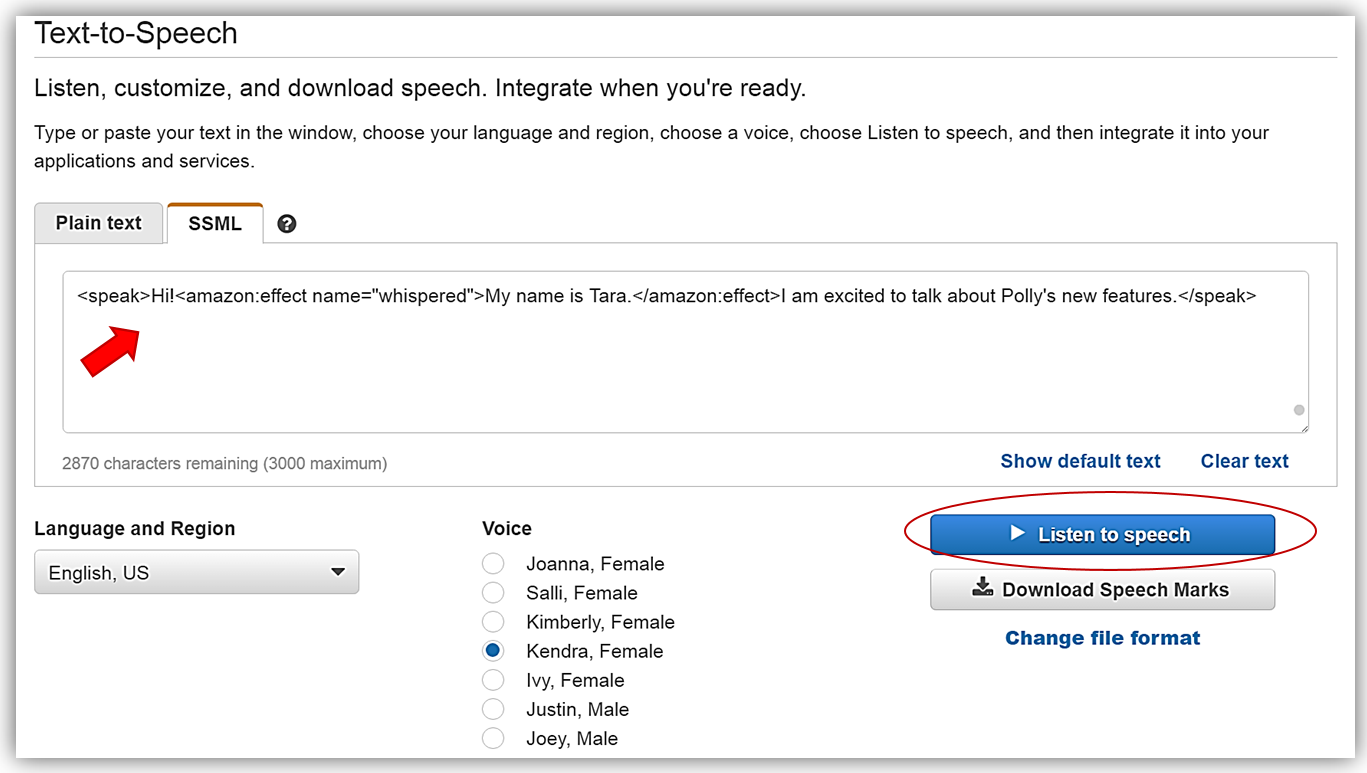
<speak>Hi!<amazon:effect name="whispered">My name is Tara.</amazon:effect>I am excited to talk about Polly's new features.</speak>
위의 마크업을 복사 한 후, Listen to speech 버튼을 누르면 “My name is Tara” 는 속삭임 소리로 들리게 됩니다.
본 기능 업데이트에 대한 자세한 소개는 아래를 참고하세요.
– Channy;
Amazon Rekognition 업데이트 – 얼굴 기반 나이 추정 속성 추가
Amazon Rekognition은 AWS의 인공 지능 서비스 중 하나입니다. Rekognition은 이미지에서 물체, 장면 및 얼굴을 감지 할 뿐만 아니라 얼굴을 검색하고 비교할 수도 있습니다. Rekognition 서비스는 백엔드에서 수십억 개의 이미지를 매일 분석하기 위해 딥러닝 기반 신경 네트워크 모델을 사용합니다. (자세한 내용은 Amazon Rekognition – 딥러닝을 기반한 이미지 탑지 및 인식 서비스 참고)
Amazon Rekognition은 이미지에서 찾은 여러 가지 속성을 API로 제공함으로서 다양한 이미진 기반 스마트 애플리케이션을 만들 수 있습니다. 오늘은 얼굴을 토대로 추정 나이를 알려주는 재미있는 신규 속성을 추가하였습니ㄷ다. 이 값은 나이 단위로 표시되며, 연령대가 겹칠 수 있습니다. 즉, 5 살의 얼굴은 4에서 6의 추정 범위를 가질 수 있지만, 6 살 얼굴은 4에서 8의 추정 범위를 가질 수 있습니다. 새로운 속성을 사용하여, 안전 관련 애플리케이션이나 인구 통계 수집 등에 활용할 수 있습니다.
새로운 기능을 재미있게 살펴 보기 위해, 필자의 옛날 사진을 가지고 Rekognition에게 나이를 추정해 달라고 요청했습니다. 결과는 다음과 같습니다.
첫 사진은 아마 제가 2 살 정도였습니다.

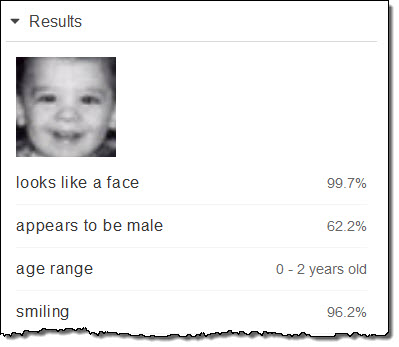
이 사진은 1966 년 봄 할머니 집에서 찍은 사진입니다.

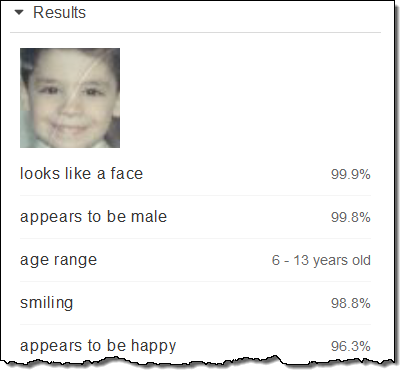
저는 6 살이었는데, 6 세에서 13 세 사이라고 추정했습니다.
제가 43 살이었던 2003 년의 나의 첫 공식 아마존 PR 사진입니다.

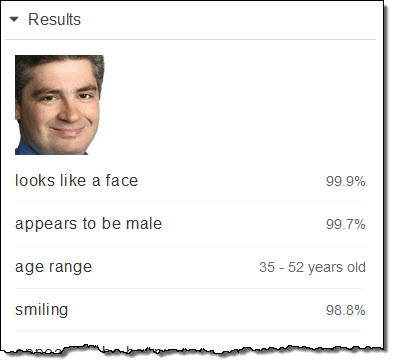
나이 범위가 17 년이지만, 실제 나이는 중간값에 있습니다.
그리고, 가장 최근의 (2015 년 말) 사진입니다. 벌서 55 살이 되었네요.

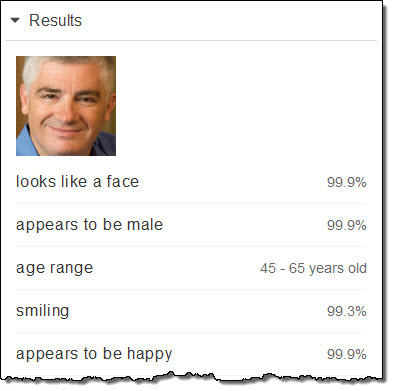
다소 넓은 나이 범위가 나오지만, 중간 값에 나옵니다. 일반적으로 각 얼굴의 실제 나이는 인식 된 범위 내로 들어오지만, 항상 중간값으로 정확하게 떨어지는 것으로 생각해서는 안됩니다.
현재 이 기능은 바로 사용 가능하며 AWS 관리 콘솔에서 데모로 해 보실 수 있습니다.
— Jeff;
이 글은 Amazon Rekognition Update – Estimated Age Range for Faces의 한국어 번역입니다.
저도 한번 해보았습니다. 여러분도 지금 바로 테스트 해보세요~!

Amazon Rekognition – 딥러닝을 기반한 이미지 탐지 및 인식 서비스
아래 사진이 무엇으로 보이시나요?

당연히 여러분은 동물이라고 인지하실 겁니다. 또한, 애완견으로서 골드리트리버 종이죠. 위의 그림과 이러한 메타 정보가 결합되는 것은 여러분의 뇌에서 바로 인지하기 때문입니다. 이는 여러분이 이미 수백 수천번 이러한 이미지와 데이터 간의 훈련을 통해 학습을 한 것입니다. 이런 방식으로 식물과 동물의 차이, 개와 고양이의 차이 그리고 골드 리트리버와 다른 견종과의 차이를 인지하는 것입니다.
이미지 인식을 위한 딥러닝(Deep Learning)
컴퓨터를 통해 인간과 동일한 수준의 이해력을 요구하는 것은 매우 어려운 작업임이 입증되었습니다. 수십 년 동안 컴퓨터 과학자들이 이 문제에 대해 여러 가지 다른 접근 방식을 취해 왔습니다. 오늘날 이 난제를 해결할 수 있는 가장 좋은 방법은 딥러닝 학습(deep learning)이라는 점에 공감대가 형성되었습니다. 딥러닝은 추상화와 신경망 결합을 사용하여 (Arthur C. Clarke가 말한 것처럼) 마술과 구별할 수 없는 결과를 산출합니다. 그러나 상당한 비용이 듭니다. 첫째, 데이터 훈련 단계에 많은 작업을 투입해야 합니다. 학습 네트워크에 다양한 텍스트 예제 (“this is a dog”, “this is a pet” 등)를 표시하여 이미지의 특징을 라벨과 연관 지어야 합니다. 이 단계에서 신경망의 크기와 다층 적 특성으로 인해 계산 비용이 많이 들게 되는 거죠. 트레이닝 단계가 완료된 후, 트레이닝 네트워크에서 새 이미지가 들어왔을 때 평가하기가 용이합니다. 쉽습니다. 그 결과는 일반적으로 신뢰 수준 (0-100%)으로 표현됩니다. 이를 통해 응용 프로그램에 적합한 정밀성 정도를 결정할 수 있습니다.
Amazon Rekognition 서비스 소개
오늘 Amazon Rekognition 서비스를 공개합니다. 딥러닝 기술을 이용하여 컴퓨터 비전 연구팀이 수 년에 거쳐 수십 억장의 이미지를 매일 훈련 시키는 완전 관리형 서비스입니다. 정확히 훈련된 수 천개의 객체와 장면에 대한 정보를 여러분의 애플리케이션에 사용할 수 있습니다. Rekognition 데모를 통해 사용 방법 및 샘플 코드를 보실 수 있고, 더 자세한 사항은 Rekognition API를 참고하실 수 있습니다.
Rekognition은 확장성을 고려해서 설계되었습니다. 각종 장면, 객체, 얼굴 등을 인식하여 이에 해당하는 레이블(Lavel) 정보를 반환해 주게 됩니다. 이미지에 하나 이상의 얼굴이 포함되어 있다면, 각 얼굴 경계선에 대한 정보를 제공합니다. 아래는 위의 골드 리트리버 이미지에 대한 정보입니다.
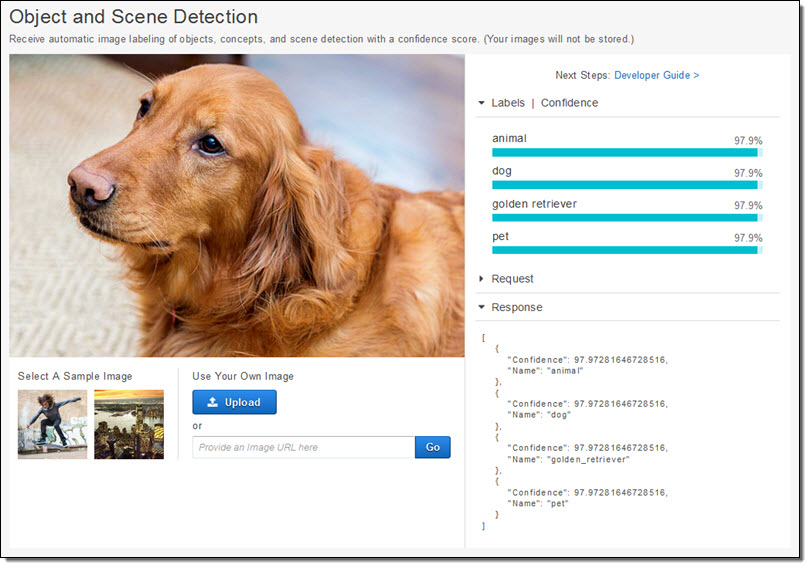
보시다시피 Rekognition을 통해 animal, dog, pet, golden retriever 등의 높은 신뢰 수준의 정보를 제공합니다. 이러한 정보들은 독립적이고 서로 명시적 관계성 없이 각자 딥러닝 모델을 통해 생성되는 것입니다. 예를 들어 개와 동물은 완전히 다른 트레이닝 결과입니다. 다만, Rekognition 결과 중 두 레이블이 동시에 강아지 중심의 훈련 자료에 동시에 나타나기도 합니다.
이제 제 와이프와 제가 찍은 사진을 한번 올려 보겠습니다.
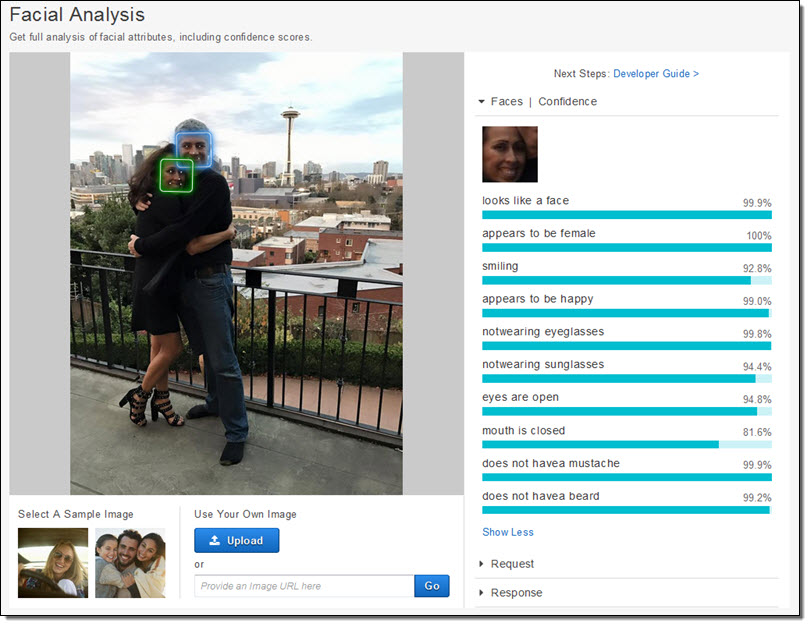
Amazon Rekognition를 통해 두 사람의 얼굴과 경계선을 얻을 수 있습니다. 와이프가 행복한 표정을 짓고 있다는 것도 알려주네요. (이 사진은 와이프 생일날 찍은 것입니다.)
또한, Rekognition는 얼굴을 비교하고 해당 이미지 인식을 요청한 많은 얼굴 중 하나가 포함되어 있는지 확인합니다.
모든 기능은 API 함수를 통해 더 자세하게 제공됩니다. (콘솔에서는 간단한 데모를 보시는데 좋습니다.) 예를 들어, DetectLabels로 첫 번째 예제를 프로그래밍으로 처리하고, 두번째로 DetectFaces를 실행합니다. Rekognition에서 IndexFaces을 여러 번 호출해서 인식할 이미지를 준비시킬 수도 있습니다. 실행 할 때마다, 몇 기지 주요 정보(face vectors)를 이미지에서 추출해서 벡터로 저장하고 이미지를 없앱니다. 하나 이상의 인식용 모음을 만들어서 각각 페이스 벡터의 관련 그룹에 저장할 수 있습니다.
Rekognition는 Amazon Simple Storage Service (S3)에 있는 이미지를 직접 가져올 수도 있습니다. AWS Lambda 함수를 통해 새로 업로드 되는 이미지 인식 작업을 수행할 수 있는데, 이 때 AWS Identity and Access Management (IAM)으로 Rekognition API 접근을 하게 하고 AWS CloudTrail로 API 사용 로그를 남길 수도 있습니다.
Rekognition 애플리케이션
이미지 인식 서비스에 대한 응용 분야는 무궁무진합니다. 만일 많은 사진 정보가 있다면 Amazon Rekognition를 통해 태깅 및 색인 작업을 할 수 있습니다. Rekognition은 클라우드 서비스로서 저장 인프라 설치와 처리 그리고 확장성에 염려할 필요가 없기 때문입니다. 이미지 검색 기능, 태그 기반 브라우징 등 어떤 종류의 대화형 검색 서비스에 적합니다.
또한, 다양한 인증 및 보안 서비스에도 활용할 수 있습니다. 웹캠을 통해 신분증 정보를 확인하거나, 사무실 출입이나 보안 영역 출입 허가를 할 수도 있고, 시각적 감시를 수행하고, 관심 있는 대상 및 사람들을 위해 안면 검사를 할 수도 있습니다. 궁극적으로 영화에 나오는 것 같은 얼굴 인식 정보를 통한 “스마트” 광고판을 만들어 볼 수도 있을 것입니다.
정식 출시
Rekognition은 오늘 부터 US East (Northern Virginia), US West (Oregon), EU (Ireland) 리전에서 서비스를 시작합니다. AWS 프리티어(무료 체험판)을 통해 한달에 5,000개의 이미지는 비용 없이 분석 가능하고 일년에 1,000 개의 페이스 벡터를 저장할 수 있습니다. 그 이상에 대해서는 이미지량과 저장 볼륨에 따라 금액이 책정됩니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 Amazon Rekognition – Image Detection and Recognition Powered by Deep Learning의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.