AWS Partner Network (APN) Blog
Fast-Tracking Agility for Mainframe Workloads
By Phil de Valence, WW Tech Leader, Mainframe & Legacy – AWS
 |
Organizations migrate and modernize mainframes to Amazon Web Services (AWS) for agility, cost reduction, and for mitigating mainframe risks.
In this post, I will highlight the key agility attributes needed by mainframe workloads, and describe the evolutionary approach to quickly and incrementally modernize from a mainframe monolith to agile AWS services.
We focus on application and infrastructure agility to change functionality, configuration, or resources quickly and inexpensively. To become agile, mainframe workloads need to adopt 12 attributes:
- Agile development with Continuous integration and continuous delivery (CI/CD)
- Integrated Development Environment (IDE)
- Knowledge-based development
- Service-enabled and modular applications
- Elasticity with horizontal scalability
- On-demand, immutable, disposable server
- Choice of compute, data store, and language
- Broad data store access
- Pervasive automation
- Managed and fully-managed services
- Consumption-based pricing
- Innovation platform
Each attribute facilitates change at higher speed and lower cost.
Evolution to Agile Services
How do we achieve agility quickly? Since mainframe workloads are typically large, tightly-coupled monoliths, some may consider a rip-and-replace, manual rewrite to cloud-native microservices straight from a mainframe. But this is expensive, risky, and very slow.
Figure 1 is an overview of how we fast-track mainframe workloads towards agility. It’s an evolution from the mainframe to agile services. Most of the agility benefits are obtained quickly with macroservices.
It maximizes benefits by bringing agility to all business functions within a mainframe workload. It minimizes business and technical risks with evolutionary transitions and gradual modernization. It provides agility quickly by using automated, mature, and fit-for-purpose tools alongside a proven, scalable infrastructure.
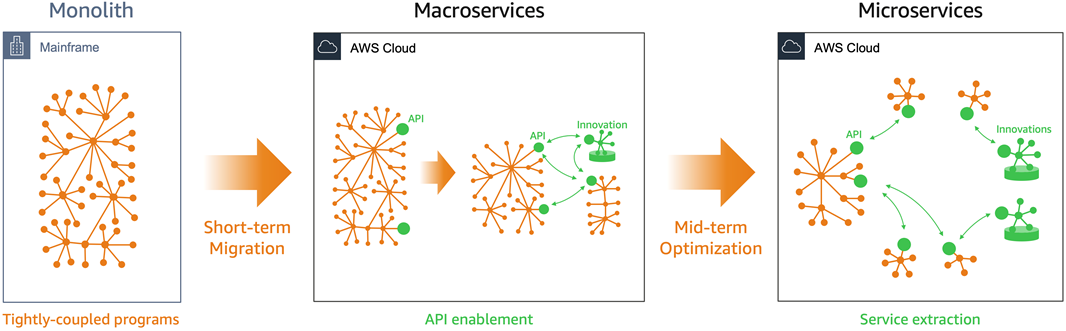
Figure 1 – Evolution from a mainframe monolith to agile services.
Transformation starts from the left in Figure 1, where you see the tightly-coupled mainframe monolith. The first phase is a short-term migration and modernization. Here, the mainframe workload is migrated and transformed into agile macroservices running on elastic compute or containers.
Macroservices are coarse-grained business services, where business functions are exposed as services using application programming interfaces (APIs). This quick migration provides substantial cost savings and return on investment (ROI) that funds ongoing modernization.
We migrate to macroservices first because they possess the 12 agility attributes needed by mainframe workloads. They provide more business value in the short term.
The migration and macroservices creation are done using tools providing speed and efficiency. Because the migration is quicker, new use cases and innovations can happen sooner. Macroservices ease the transition to microservices because they benefit from modernized application and infrastructure stacks.
The second phase is optimization of some services into microservices. In this phase, some but not all services are optimized into microservices. We extract microservices only when it makes sense.
It’s worth noting that microservices are not suitable for all workloads. Microservices add their own complexity. Creating microservices requires manual reengineering which would be challenging, slow, and expensive at the beginning of the mainframe modernization journey.
This evolutionary approach provides agility, cost efficiency, and risk mitigation with macroservices in the short term, and facilitates the transition to microservices where appropriate.
Data Store Evolution for Agile Services
Data is one of reasons we transform the mainframe monolith to macroservices first, before considering microservices. A microservice needs its own database.
The evolutionary approach accelerates modernization and reduces challenges with a shared database first. It later allows extracting one database per service if and when suitable.
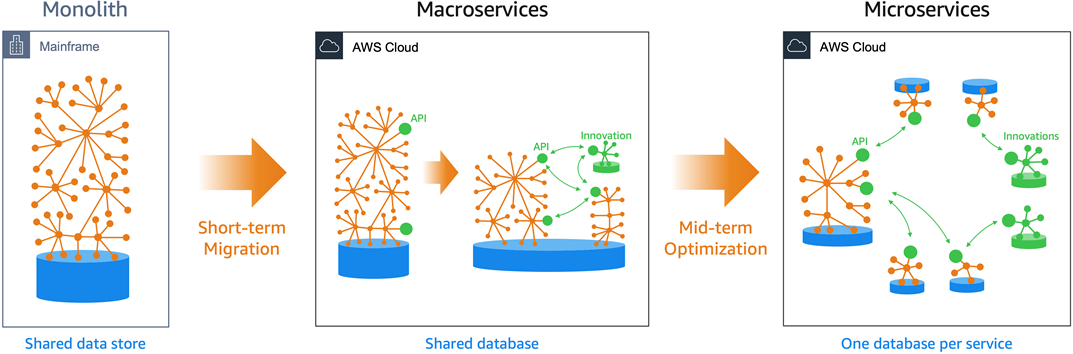
Figure 2 – Data store evolution for agile services.
During the first migration and modernization phase shown in Figure 2, the mainframe workload’s legacy data store is typically migrated to a relational database. For example, it can be an indexed file to a relational database migration.
Once migrated, the database is shared by the macroservices, which provides many advantages. It’s fully supported by tools for quick and reliable migration, and retains data normalization and structure, which minimizes application changes. It also preserves data integrity with strict consistency and ACID transactions.
During the optimization phase, we create independently-deployable microservices which own their own data. A microservice encapsulates data with one database per service. Here, database implies a logically isolated schema, not a database engine which could host multiple schemas.
In this optimization phase, data is extracted from the shared database into one database per service. This is a complex activity where manual reengineering is involved. We should only do this data extraction when and where it makes sense.
Evolutions Towards Agility
This evolution is not just a migration but also a modernization on many dimensions.
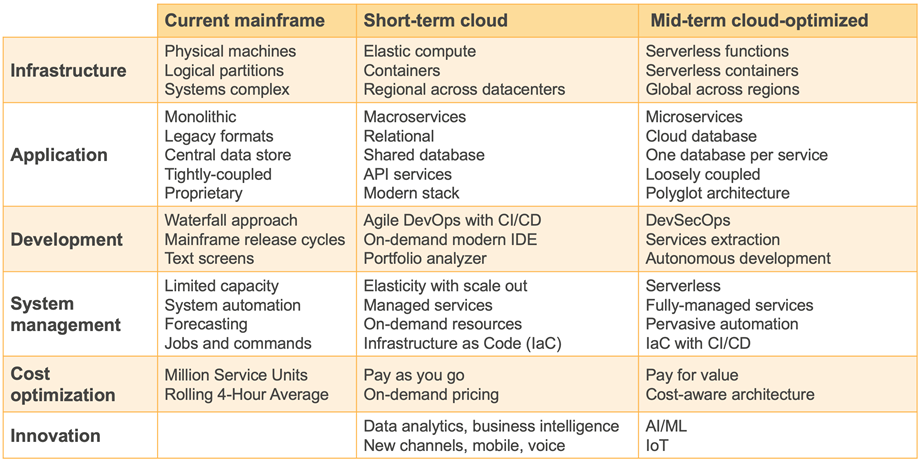
Figure 3 – Evolutions towards agility.
This highlights some of the technical changes in areas such as infrastructure, application, development, system management, cost optimization, and innovation. It shows the changes when moving from the mainframe to cloud in the short-term, and changes when optimizing on the cloud.
Mainframe Strangling Workload by Workload
Mainframes, especially large mainframes, typically run multiple workloads in parallel. A workload is a set of programs, middleware, data stores, dependencies, and resources that execute a cohesive set of business functions. It’s often supported by one data store and one transaction monitor.

Figure 4 – Mainframe strangling workload by workload.
As shown in Figure 4, mainframe workloads are migrated iteratively. Each workload typically ends up with dedicated resources for compute and data on the AWS side. We prioritize workload migration based on business criticality, technical complexity, integration points, and business value. Over time, we strangle the mainframe workload by workload.
Tool-Based Workload Migration
Looking at one mainframe workload, we can accelerate migration by using proven tools which provide emulation and automated refactoring capabilities.
These capabilities are essential to reuse and modernize mainframe assets quickly. They facilitate cloud best practices for availability, scalability, and security.
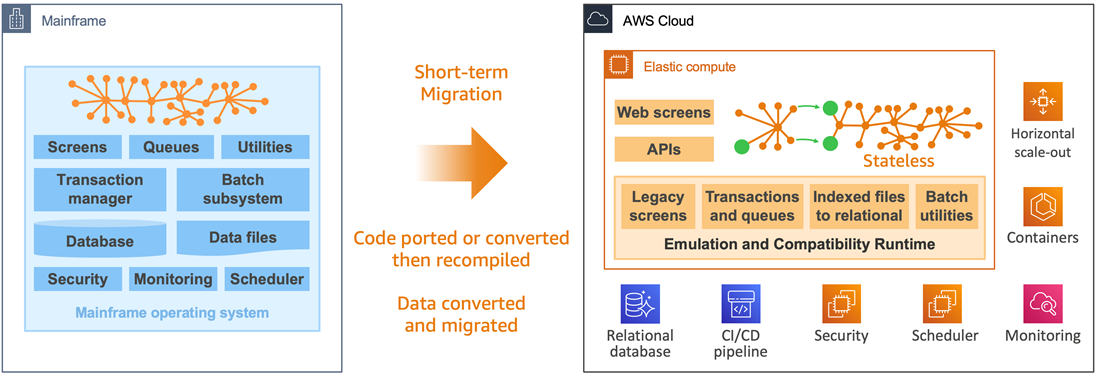
Figure 5 – Tool-based workload migration.
During migration, application code is ported or converted, then recompiled for deployment on AWS. Data is also converted and migrated, usually to a relational database. Whenever possible, there should be no manual code rewrite to avoid human errors and risks.
Creating Macroservices
Macroservices are coarse-grained services which typically share a central database. During a tool-based migration and modernization, they can be created in various ways:
- Direct API enablement: Some programs are selected and directly exposed as services manually using REST or SOAP APIs. To create these, interface operations and fields are defined, and then mapped to programs and parameters. The service interface is enabled and ready to be invoked over the network by client applications.
- Separation of frontend logic from backend logic: Some toolsets automatically package the presentation logic into a frontend and package the business logic into a separate backend invoked via APIs. These backend APIs can also be invoked over the network by client applications.
- Code slicing: Some toolsets can extract specific business logic (preferably independent programs) in its own module or package, and expose it via an API. It is pinpoint tool-based code refactoring.
Once macroservices are created, they can be quickly invoked and reused by other applications or innovations. Similarly, the macroservices data is typically in a relational datastore that is easily accessed for new options and innovations
Agility Gains with Macroservices
The migration and modernization of a mainframe workload to AWS uses a typical architecture, as shown in Figure 6 below. This shows the CI/CD pipeline which follows DevOps best practices. It includes on-demand development environments, source control, and pipelines for automated build, test, and deployment.
In the center of the diagram, you can see that macroservices are deployed on elastic compute and managed relational databases. On the right side, innovations can immediately access the macroservices’ business functions or data directly.
At the bottom are key components for the quality of service. Mainframe workloads are often business-critical, so AWS ensures we meet or exceed non-functional requirements for security, availability, scalability, and system management.
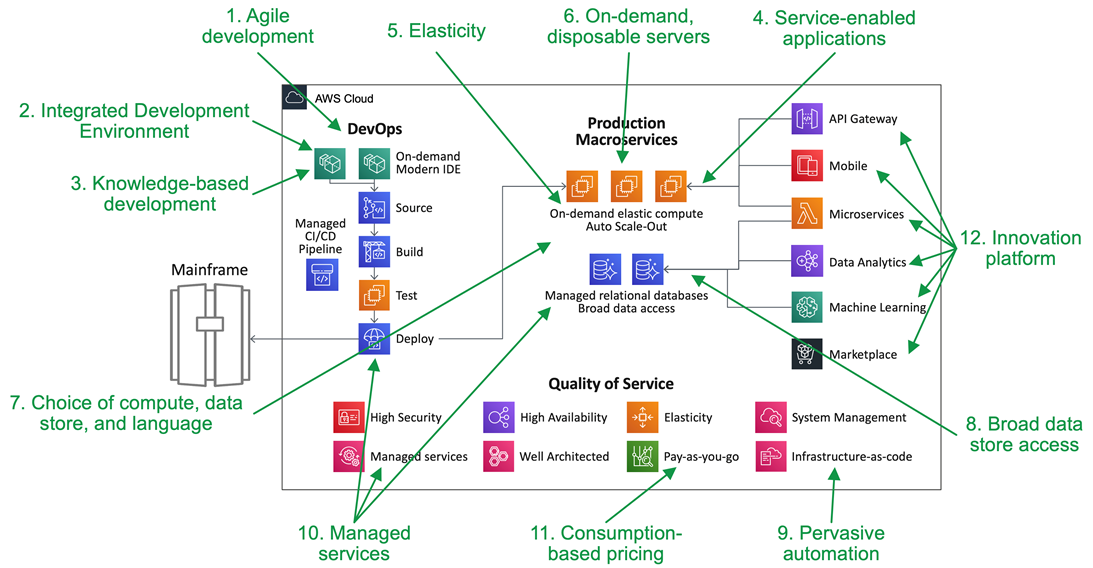
Figure 6 – Short-term architecture on AWS.
This short-term architecture provides the 12 agility attributes needed by mainframe workloads. It provides agility gains for all business functions that are part of a workload migrated to AWS.
You can read about the specific AWS services providing agility in my post: Accelerating Agility with 12 Attributes for Mainframe Workloads.
Cost Efficiency and Risk Mitigation with Macroservices
In addition to agility gains, this short-term architecture on AWS also provides necessary attributes for cost efficiency. This includes consumption-based pricing, business and IT capacity alignment, cost-aware architecture, managed services, pervasive automation, cost optimization services, economies of scale, and a large vendor ecosystem.
The architecture allows mitigation of typical mainframe risks, and addresses the mainframe skills shortage with modern, popular technology. It reduces vendor lock-in with portable technology stacks while eliminating isolated platform silos with an open service-based architecture.
The architecture also removes bottlenecks from physical machines’ limited capacity by using on-demand elastic resources. It minimizes outages with global and regional redundancy, and prevents escalating costs with a cost-efficient architecture.
It addresses slow waterfall release cycles with DevOps CI/CD pipelines, and unlocks valuable business data with modern, broad data access. It solves the lack of legacy platform innovation with a vibrant cloud innovation ecosystem.
Optimize and Innovate for More Agility
Now that we have migrated and modernized mainframe workloads to AWS using macroservices, we can enter the second phase of optimization and innovations.
This optimization is facilitated by the breadth of services and features available on AWS. There are over 200 fully-featured services on the AWS Cloud. With these, we can optimize the migrated workload for more agility in many different dimensions.
For example, we can create more granular services towards microservices. Or, we could introduce more automation with pipelines and infrastructure as code (IaC). We can also reduce operational complexity and increase speed with managed and serverless services.
There’s another benefit of creating macroservices on AWS in the short-term: we can quickly integrate macroservices with the rest of the AWS services for innovations. This applies to all mainframe functions and data migrated onto AWS.
For example, we can quickly introduce predictive analytics or artificial intelligence (AI) or machine learning (ML). We can enable new mobile or voice interfaces, or we can introduce new use cases based on serverless and container services.
Once the mainframe workload is migrated to AWS, we unleash its application and data potential with agility.
Microservices?
A microservice is an independent deployable service which can be developed, tested, deployed and scaled independently from other services. It is loosely coupled and communicates using lightweight mechanisms with other services.
Microservices are modeled around a business capability, which allows grouping strongly-related functions and aligning them with business outcomes. A microservice owns its own data, making each microservice independent and decoupled from other services.
This also enables information hiding to prevent unintended coupling. So, if you see a database shared across services, these are not microservices yet.

Figure 7 – Macroservice and microservice differences.
Benefits of using microservices include autonomy, technology choices, scalability options, reduced time to market, and smaller blast radius.
There are also drawbacks and challenges with microservices. For example, managing distributed transactions and losing ACID properties are difficult. Dealing with eventual consistency may not be acceptable. Network latency and failures may make things unpredictable.
Microservices’ operational complexity can increase exponentially with the proliferation of functions, databases, and interfaces. As James Lewis says, “Microservices BUY you options.” There is a cost for microservices, and you must evaluate whether the options are worth the cost. That’s why microservices should not be the default.
Actually, coarse-grained agile macroservices often meet organizations’ business needs. We should incrementally create microservices only when and where it makes sense, with a specific goal and scope for each.
Extracting Microservices
Let’s assume we have justification to create a microservice; for example, if we know a specific business function needs extreme scalability with a different data store type. In this case, we’ll have to extract both programs and data in order to create a proper microservice. Fortunately, extracting a microservice from a modern stack on AWS is much easier than extracting a microservice from a legacy mainframe.
On the application side, we must first identify the granularity, business functions, and program grouping. We should look at the scope of transactions to avoid the challenges of distributed transactions. We can use Domain-Driven Design to model the business domain, and divide it into Bounded Contexts and Aggregates, and then we can map these to individual microservices.
That’s where the Event Storming approach can help. It’s a fast way to model a domain following Domain-Driven Design. Analyzer and refactoring tools can help refine and determine the technical scope and facilitate the programs’ extraction and packaging.
On the data side, data extraction is an important part of creating a microservice. Much of the complexity of decomposing complex systems lies in the data. With data extraction, we mean separation of database schemas.
There are patterns and techniques to split a database. For example, we can use database views, wrappers, replicas, or synchronization. Along with data separation, we must take care of data consistency and transactionality, which may require implementing compensation patterns such as Sagas or Try-Confirm-Cancel (TCC).
Sometimes, a pinpoint manual rewrite of a business function may be more effective than program extraction. In this case, the small functions rewrite should take a few days or few weeks. If it takes months to rewrite a service, it likely means the manual rewrite is not the right approach.
Overall, extracting microservices is an incremental effort for both program and data extraction. It’s done in small steps to learn from the process and adjust where needed.
Timeline to Agility
Let’s highlight how fast we get to agility using the macroservices-then-microservices approach.
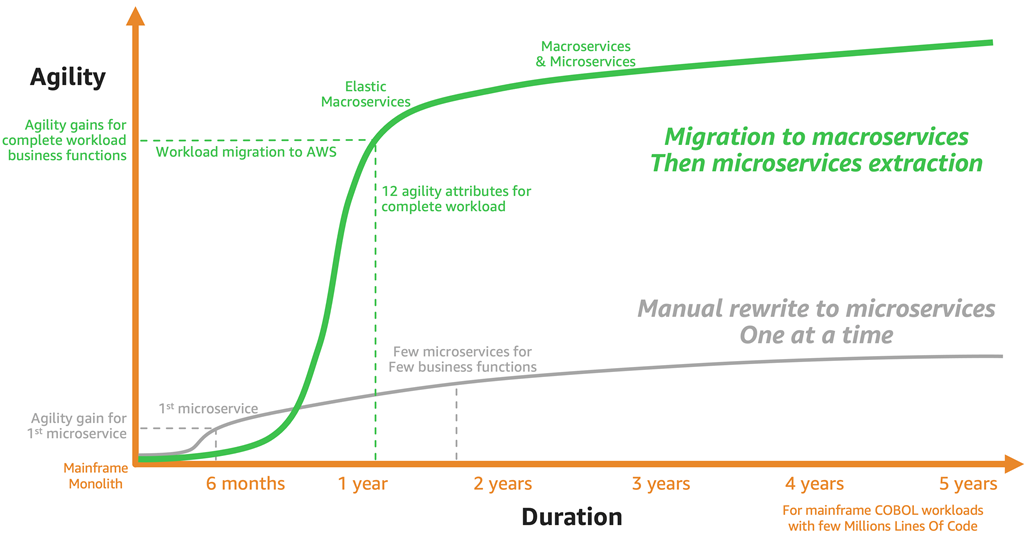
Figure 8 – Timeline to agility.
Figure 8 shows the time it takes to modernize an average mainframe workload in relation to the agility gains from modernization. The green curve shows agility growing with the macroservices implementation. Notice that agility grows very fast the first year, because the 12 agility attributes apply to the complete mainframe workload.
It’s not just few business functions being modernized, but the business domains and functions composing a mainframe workload are transformed into agile macroservices on AWS. Then, agility grows steadily while we extract microservices incrementally.
In comparison, the gray curve shows the agility when manually rewriting microservices straight from a mainframe, also called manual reengineering or re-invention approaches. Each new microservice rewritten from the mainframe has a small scope of business functions.
There are challenges and complexities for extracting subsets of programs and data across legacy mainframe components and a modern infrastructure. Consequently, agility gains are small and slow. Because microservices are created incrementally and manually, it takes a lot of time to accumulate these small agility gains.
Over time, it gets more difficult and complex to rewrite the more complex mainframe transactions. That slows down the agility gains even further. A large-scale manual rewrite or re-engineering delays agility benefits when modernizing to AWS Cloud.
Learn More
The macroservices-then-microservices approach with AWS accelerates agility for a large scope of business services. This is the fast track to agility for a mainframe workload.
You can learn more about toolsets supporting this approach, such as:
- Automated Refactoring from Mainframe to Serverless Functions and Containers with Blu Age
- Transitioning Mainframe Workloads into Agile Services with AWS and Micro Focus
You can also learn from customer stories and other solutions for mainframe modernization. Feel free to reach out to us to schedule mainframe modernization hands-on labs or workshops.