AWS Partner Network (APN) Blog
Fraud Detection for the FinServ Industry with Redis Enterprise Cloud on AWS
By Srinivas Pendyala, Cloud Solutions Architect – Redis Inc.
By Antony Prasad Thevaraj, Sr. Partner Solutions Architect – AWS
 |
| Redis |
 |
In the financial services industry, detecting fraud is a complex process. For any given transaction or activity, the system needs to decide whether it’s fraudulent or not and take action within seconds.
Failing to do so can lead to significant losses. Fraudsters are evolving every day and are moving in tandem with digital banking transformations, discovering innovative ways to steal or fake customers’ identities and commit fraud.
In this post, we will focus on the two challenges–false positives and latency. Both yield unhappy customers and substantial loss to sellers.
With Redis Enterprise Cloud‘s sub-millisecond latency speeds, up to five 9’s of availability, linear scalability, and multiple data model support coupled with the global cloud infrastructure support of Amazon Web Services (AWS), organizations can benefit from building a real-time fraud detection system to manage and control fraud.
Redis is an AWS Partner and cloud-native database-as-a-service that unifies your hybrid and multi-cloud data layer. Customers can find Redis Enterprise Cloud offerings on AWS Marketplace to easily transact and adopt the technologies.
False Positives
A false positive is when the system flags a legitimate transaction by the user as fraud. This can be frustrating for the customer and costly for the seller.
Effective machine learning (ML) algorithms, such as Random Cut Forest and XGBoost, are effective in combating fraud. However, as fraud constantly evolves, a multi-layer approach needs to be in place for better detection, along with continual model learning.
Latency
If companies cannot detect whether a transaction is fraudulent or not within a few seconds, by default it’s considered genuine. Therefore, latency is critical in fraud detection.
Because of its ultra-low latency features, Redis Enterprise Cloud on AWS helps resolve challenges with real-time fraud detection without sacrificing the end user or customer experience.
This solution takes advantage of the breadth and maturity of AWS services such as Amazon SageMaker for machine learning operations. By using Redis Enterprise Cloud on AWS in your architecture, you can help mitigate fraud detection in real time.
Solution Approach
Organizations can adopt either a rule-based solution or ML-based solution, or a combination of both, in order to mitigate fraud detection in real time.
Rule-based solutions typically enforce a set of hardcoded rules to determine if the transaction is fraudulent or not. A few examples of implementing rule-based solutions include:
- Blacklisting a set of IP addresses.
- Utilizing users’ geographical coordinate (longitude, latitude)-based rules.
- Evaluating per-user purchase profile information (Has this customer purchased in this product category?)
Let’s explore how AWS and Redis Enterprise Cloud integrate to provide the best of both worlds when implementing rule-based and ML-based real-time fraud detection systems.
Architecture Overview
Amazon SageMaker comes with pre-built ML algorithms such as XGBoost and Random Cut Forest. Implementing these algorithms straight out of the box from Amazon SageMaker decreases development time in implementing ML-based fraud detection solutions.
Redis Enterprise Cloud is a fully managed database-as-a-service, and Redis modules such as RediSearch, RedisJSON, and RedisTimeSeries extend core Redis data structures to implement modern data models for building real-time fraud detection solutions.
RedisJSON allows applications to persist end-user transactional data as JSON documents, allowing ultrafast sub-elemental data access. RediSearch enables indexing data while persisting for faster complex SQL-like query executions. RedisTimeSeries can be leveraged to persist the ML inferenced results data in time-series format, to build data visualizations using Grafana dashboards for real-time analytics.
At inference time, the ML engine needs to quickly read the latest feature values from the online feature store and use them at the inference time. Based on the real-time features, the ML model will score the transaction.
Redis Enterprise Cloud can also be used as an in-memory feature store for ML operations. Organizations that invest in feature engineering for their ML operations can benefit from Redis Enterprise Cloud’s ultra-low latency and in-memory capabilities. This makes building an online and real-time accessible features store on Redis a strong architectural design choice.
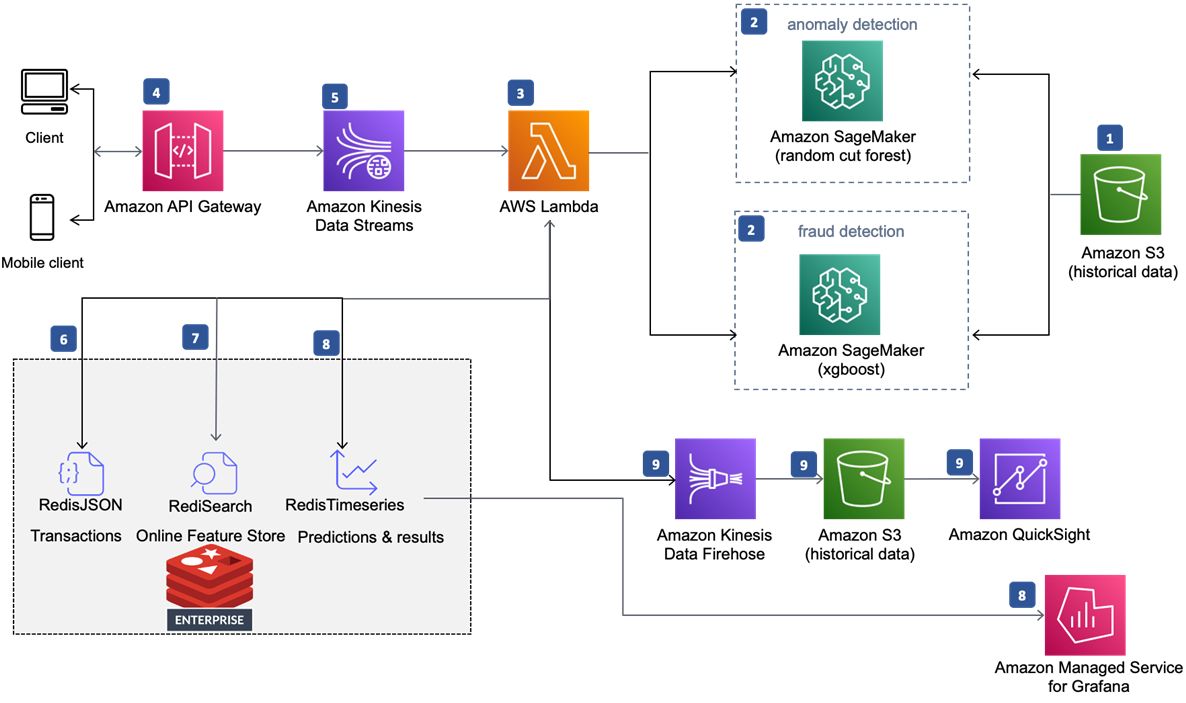
Figure 1 – Real-time fraud detection powered by Redis Enterprise Cloud on AWS.
In the diagram above, the numbered annotations directly match to the numbered bullet points:
- An Amazon Simple Storage Service (Amazon S3) bucket contains historical datasets of credit card transactions.
- An Amazon SageMaker notebook instance with different ML models will train on the datasets.
- An AWS Lambda function processes transactions from the historical datasets and invokes the two SageMaker endpoints that assign anomaly scores and classification scores to incoming data points.
- End users (mobile and web clients) invoke Amazon API Gateway REST API for predictions using signed HTTP requests.
- Amazon Kinesis Data Streams are used to capture real-time event data.
- Lambda function reads the stream and persists transactional data to the RediSearch and RedisJSON-enabled Redis Enterprise Cloud database.
- Optionally, Redis Enterprise Cloud can be used as a database for an online feature store platform (no Redis modules are required for this functionality). Lambda can leverage this Redis-based feature store, query features, and use it while making inferences.
- Lambda function further persists the prediction results to the Redis Enterprise Cloud database. Optionally, the results along with transactional details can be stored to a time-series database for further data visualizations using Grafana.
- Lambda function optionally can pass the prediction results via Amazon Kinesis Data Firehose, which persists the data to an S3 bucket so that Amazon QuickSight can consume this data for visualizations and analytics.
Prerequisites
To implement this real-time fraud detection solution, the following prerequisites are to be met:
- AWS account is set up to provision cloud resources.
- AWS Command Line Interface (CLI) is configured.
- Docker and Docker Compose are installed to run containerized applications and AWS Lambda functions.
- Terraform is installed to run data visualizations using Grafana dashboards.
- Redis Enterprise Cloud is configured to provision Redis databases on AWS.
Implementation Details
To get started installing and setting up Redis Enterprise Cloud on AWS, visit the Redis Labs page, subscribe, get an account, and configure your subscription and databases.
Amazon SageMaker
Use this AWS CloudFormation template to create a CloudFormation stack on AWS.
The stack will ask you to configure Amazon S3 bucket names for your Model Data and Results. Define all of the configuration details as shown below, and then create the stack.

Figure 2 – AWS CloudFormation stack.
Once the CloudFormation stack completes its run, the following cloud resources are created:
- Amazon SageMaker instance notebooks.
- Amazon SageMaker instance lifecycle configurations.
- Appropriate AWS Identity and Access Management (IAM) roles and policies.
- Amazon S3 buckets needed for input data and for saving output (results).
Run Amazon SageMaker Notebook
Run the Jupyter SageMaker notebook found in the Amazon SageMaker instance. Run it cell by cell, as shown below.
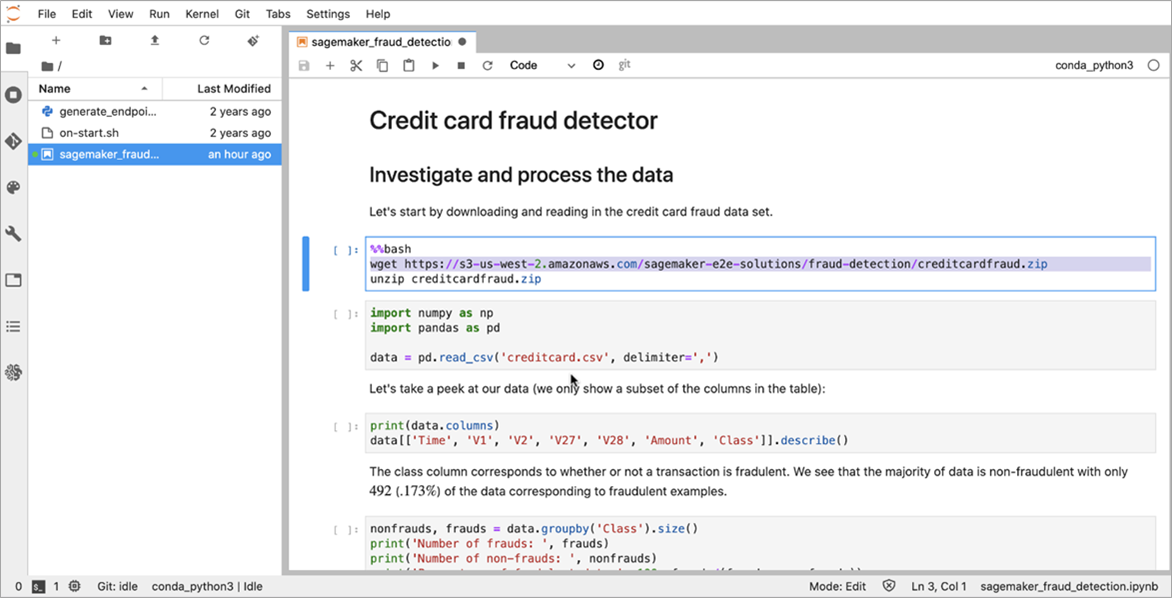
Figure 3 – Amazon SageMaker notebook.
After you run the SageMaker notebook, you’ll create the following cloud resources:
- Model training jobs for Random Cut Forest and XGBoost algorithms.
- Deployed model endpoint configurations and model endpoints.
- S3 buckets that have the input and output buckets with trained data and results.
Here is a screenshot of Amazon SageMaker models, when they are defined.

Figure 4 – Amazon SageMaker models.
Here’s a screenshot of model endpoint configurations, when they are deployed.
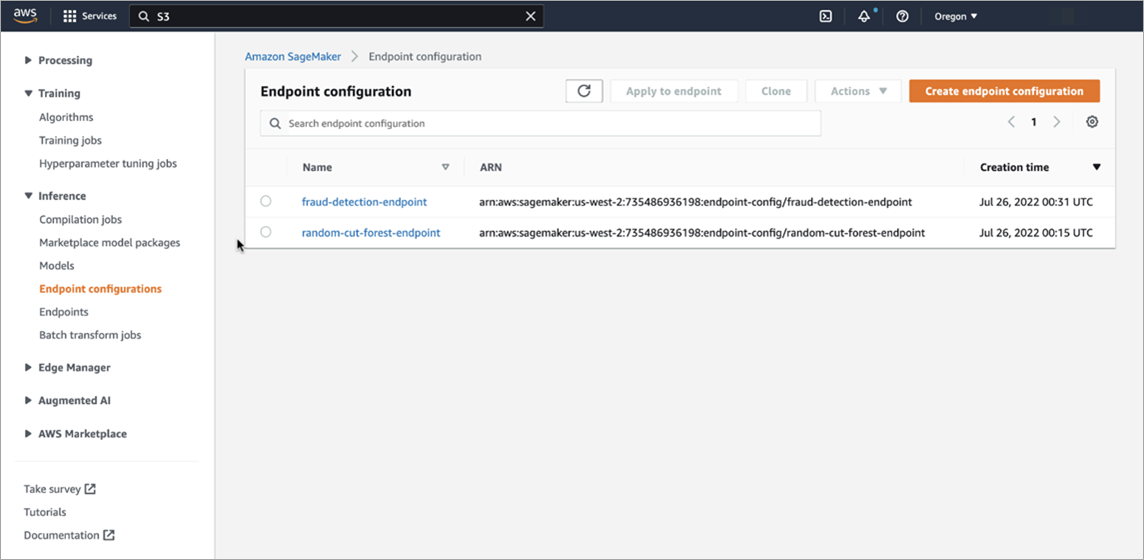
Figure 5 – Amazon SageMaker endpoint configurations.
Finally, here’s a screenshot of model endpoints that can be invoked in real-time, in order to make inferences against these models.
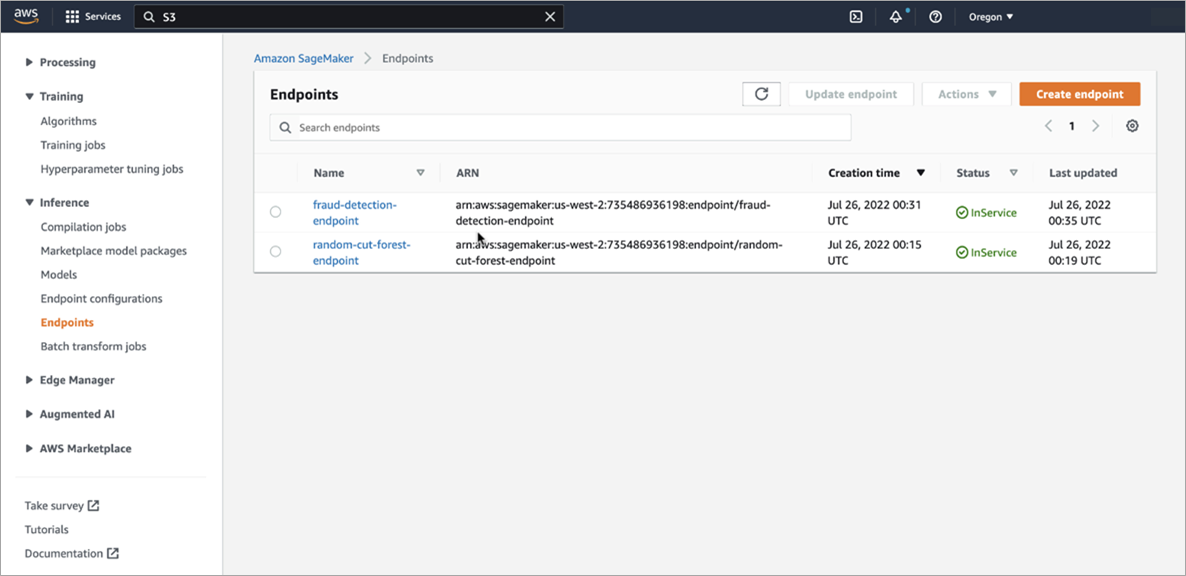
Figure 6 – Amazon SageMaker endpoints.
Now that you have the well-trained model and endpoints being published successfully in Amazon SageMaker, it’s time to do the actual inferencing using these models as the transactions happen in real time.
AWS Lambda
We’ll use AWS Lambda to react to the incoming events in real time. Lambda will read the incoming data from an Amazon Kinesis Data Stream and process each record.
For each record found in the Kinesis event stream, Lambda runs the following functions:
- persistTransactionalData – To persist the transactional data as-is, in its original JSON format, into the Redis Enterprise Cloud database that leverages the RedisJSON module.
- makeInferences – To make a real-time inference to ML endpoints published in Amazon SageMaker.
- persistMLScores – To persist the inference ML scores obtained in the previous step to a time-series database, so you can run data analytics and data visualization dashboards on this data using Grafana dashboards.
The Lambda function (in Python 3.x) would like this:
Here is the code snippet of how you can persist the incoming JSON formatted Kinesis event data into Redis that leverages the RedisJSON and RediSearch modules. Notice how the current date and timestamp is acquired and used as a part of the key by appending the word “fraud:”, while persisting the data into RedisJSON.
The last line in the above snippet also queries the data using redis_client.json().get(key) to ensure the data is indeed persisted.
Next, here is what the makeInferences function looks like. It calls functions that run anomaly detection (using Random Cut Forest) and fraud detection (using XGBoost) and returns the inference ML score results.
Here’s how you make an inference using random cut forest algorithm.
And here’s how you make an inference using XGBoost.
Once the ML scores are obtained from both Random Cut Forest and XGBoost endpoints, you can implement your own custom business logic to finalize an ML score that could be an average of both scores, or a weighted average or some other custom logic as per your business needs.
Here is how these ML scores are persisted to Redis time-series database. Notic thee #Custom Logic sections on how an enterprise can deduce an ML score and how a transaction can be flagged fraudulent.
For example, if the fraud_score >=0.8 (on a scale of 0.0 to 1.0) is categorized as fraudulent, anything less than 0.8 could be categorized as non-fraudulent.
Once the Lambda function is defined, it’s time to deploy it on AWS. A complete working Lambda function code written in Python 3.x can be found on GitHub.
You will deploy this Lambda function as a container, using the instructions given in the AWS documentation. You can also see a quick rundown of this process.
Amazon Kinesis Data Streams
Next, we will set up Amazon Kinesis Data Stream to capture end-user credit card transaction events. Give it a name called “demo-stream” and set up the batch size as 1 instead of 100, just to simulate Kinesis reading one transaction at a time.

Figure 7 – Amazon Kinesis Data Stream configuration.
Now, go ahead and set up the Kinesis Data Stream “demo-stream” as a trigger to the Lambda function created previously.
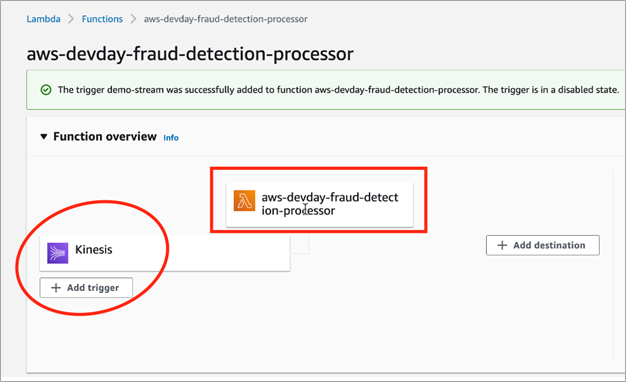
Figure 8 – Lambda trigger configuration.
The above configuration enables the Lambda function to get triggered as soon as the end-user transactional data arrives in the Kinesis Data Stream.
To run the entire flow, you can write a Python script that simulates end-user transactional data. These transactions are captured into the Kinesis Data Stream. Here’s the process to run this flow end to end.
Data Visualization
Data visualization that depicts live inference and ML scoring, as well as number of fraudulent transactions found for a specific period of time, can be done using Grafana dashboards.
Here’s an example of a typical data visualization dashboard that can be configured on the Redis database. See a complete flow and configuration of this visualization.

Figure 9 – Grafana data visualizations.
Customer Success Story
With more than five billion records searched by 35 million people a month, one of the leading FinTech customers of Redis drives customer identity verification and fraud detection services at scale, and makes it easy for businesses and individuals to find contact information and run background checks for fraud.
Redis Enterprise Cloud forms the backbone for this customer’s proprietary Identity GraphTM solution, making an average of 150,000-200,000 calls per second to the company’s 3TB database—it can even surpass this number during peak hours.
By leveraging Redis on Flash, this customer saved hundreds of thousands of dollars on their cloud investments by reducing 30% of the expensive DRAM storage usage.
Conclusion
Redis is highly adopted as a distributed cache in enterprise architectures, and Redis Enterprise Cloud unlocks features beyond a cache. It can be employed as a primary database with a number of data structures that support persistence of data models like JSON, search, time series, and graphs.
With its ultra-low latency and speed, Redis Enterprise Cloud can extend into AI/ML use cases with real-time needs and be used as a feature store for machine learning operations.
Try Redis out for yourself on AWS Marketplace, and explore this GitHub repository for fraud detection to get started.
.

.
Redis – AWS Partner Spotlight
Redis is an AWS Partner and cloud-native database-as-a-service that unifies your hybrid and multi-cloud data layer. Customers can find Redis Enterprise Cloud offerings on AWS Marketplace to easily transact and adopt the technologies.