AWS Architecture Blog
Building Resilient Well-Architected Workloads Using AWS Resilience Hub
AWS Resilience Hub is a new service that helps you understand and improve the resiliency of your workloads using AWS Well-Architected best practices. As the lead for the Reliability Pillar of AWS Well-Architected, I am eager to share with you how you can use Resilience Hub to ensure your workload architecture is as reliable as you need.
In this blog post, I’ll show you how to use Resilience Hub to assess and improve the resiliency of your architecture based on its recommendations. I’ll start with a single Availability Zone (AZ) architecture, and evolve the architecture using the resiliency recommendations.
Single AZ architecture
Figure 1 shows the single AZ architecture I’m going to start with and assess using Resilience Hub. This simple web server runs on Amazon Elastic Compute Cloud (Amazon EC2). It serves a static web page stored in an Amazon Simple Storage Service (Amazon S3) bucket, and then records web site statistics in a MySQL Amazon Relational Database Service (Amazon RDS) database. A NAT gateway is also deployed so the EC2 servers can make calls out to the internet. When I add my application to Resilience Hub, it will discover my application structure. Then I can use it to assess my application’s resiliency per the instructions in the Measure and Improve Your Application Resilience with AWS Resilience Hub blog post.
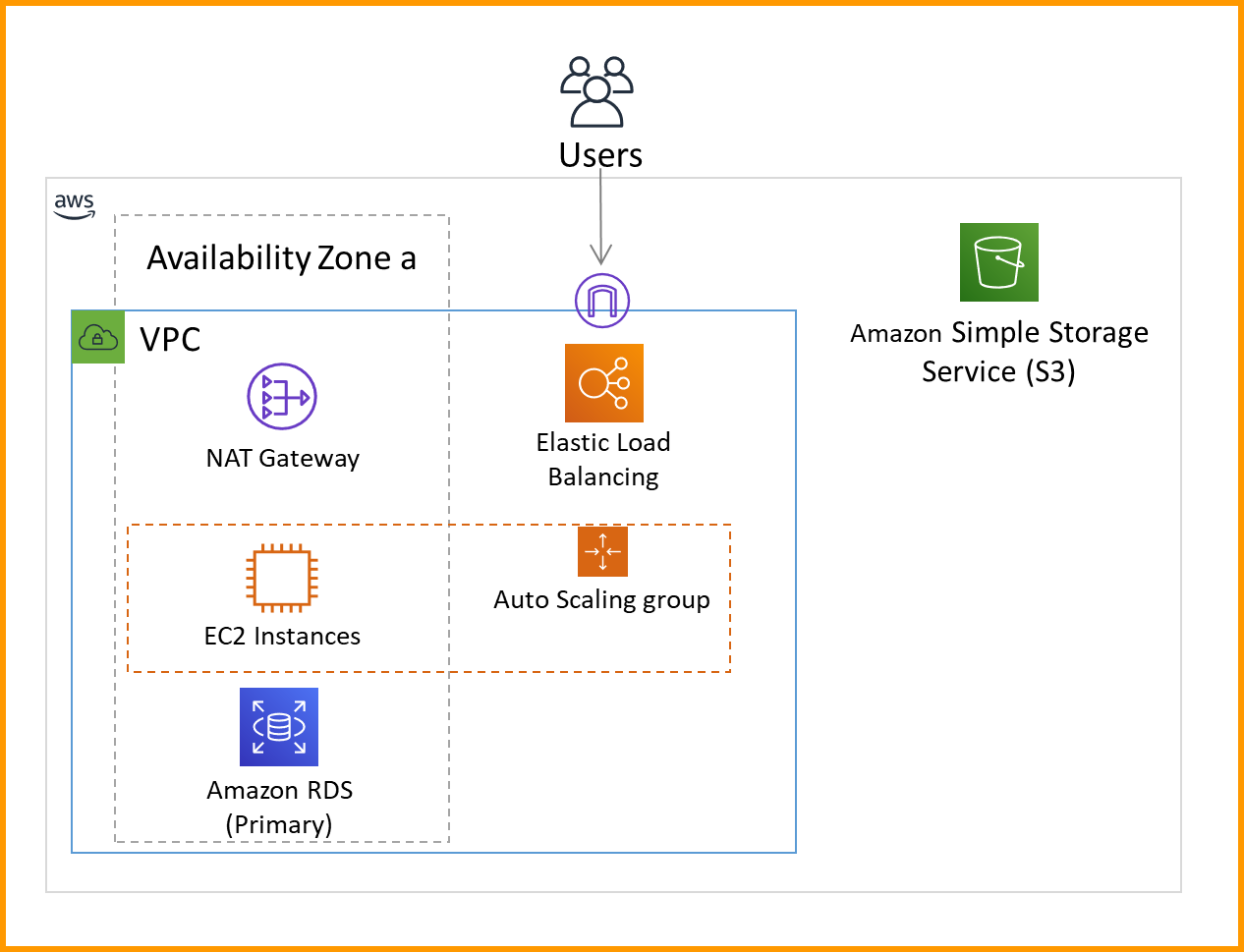
Figure 1. Single AZ architecture
Even with only a single Amazon EC2 instance, it is still useful to include an Elastic Load Balancer. This lets you configure health checks performed against the EC2 instance. It also makes it easier to add more EC2 instances later. The Amazon EC2 Auto Scaling group helps improve resiliency—if the EC2 instance fails its health check, the Amazon EC2 Auto Scaling group will replace it.
Resilience Hub assessment results for the single AZ architecture
Figure 2 shows the results from Resilience Hub; it’s showing a lot of red flags! This architecture does not meet my required RTO (Recovery Time Objective) and RPO (Recovery Point Objective) goals for resiliency, and it is unrecoverable for all failure types. Figure 2 shows that Resilience Hub assesses for several failure types, including failures in the workload application (bad code or data), infrastructure (component failure), or individual AZ availability. AZs within a Region are independent of each other, even if one AZ experiences issues, the other AZs will remain available. The single AZ architecture does not take advantage of that.

Figure 2. Resilience Hub assessment of the single AZ architecture
Figure 3 shows the component-level assessment of resiliency where each component corresponds to a part of the single AZ architecture. The results show that the S3 bucket does well. S3 is resilient to AZ failures and stores data across multiple AZs, which results in high data durability.
However, having a single RDS instance means that if the instance fails (infrastructure), or the AZ containing the instance fails (AZ) then it cannot operate (unrecoverable RTO), and the data will be lost (unrecoverable RPO). Similarly, deploying only one NAT gateway leaves the architecture vulnerable if the AZ experiences issues, so it shows as unrecoverable for AZ disruptions. But, because the NAT gateway is a fully managed service, there is no hardware to manage, and therefore it shows as resilient (0s RTO) for infrastructure issues.

Figure 3. Resilience Hub component-level assessment of the single AZ architecture against cloud infrastructure failures
To improve the single AZ architecture’s resiliency, Resilience Hub recommends enabling multi-AZ for the RDS instance. This will set up a standby database instance in another AZ. For the NAT gateway, it suggests “Add NAT Gateways in multiple AZs. (i.e., every AZ you have resources in).” I’ll implement these suggestions in the next section.
Multi-AZ architecture
Figure 4 shows the multi-AZ architecture that I built based on Resilience Hub’s recommendations, which use the following Well-Architected Reliability best practices:
| Well-Architected Best Practice | Modification to Architecture |
| Deploy the workload to multiple locations | I set up RDS instances, NAT gateways, and EC2 instances distributed across AZs. |
| Fail over to healthy resources | If one EC2 instance fails, the Elastic Load Balancer will fail over and send traffic to the remaining healthy ones. If the primary RDS instance fails, the standby will be promoted to be the new primary. |
| Automate healing on all layers | The Amazon EC2 Auto Scaling group will replace faulty EC2 instances, and the RDS failover is automatic. |

Figure 4. Multi-AZ architecture
In the next section, I’ll send this new architecture through Resilience Hub to check how much it has improved.
Resilience Hub assessment results for the multi-AZ architecture
As shown in Figure 5, the architecture still has some problems, but it’s looking much better! Resilience Hub has highlighted application failure as the possible source of resilience issues, so let’s dive into application RTO and RPO.
By making RDS multi-AZ, data is replicated to a standby instance. If your infrastructure or AZ fails, the system will fail over to the standby instance.

Figure 5. Resilience Hub assessment of the multi-AZ architecture
As seen in Figure 6, application failures are different. If the data is corrupted or deleted due to a bug, accident, or unauthorized action, then that deletion or corruption will be replicated to the standby. The standby does not protect you in this case. Similarly, with S3, I need to protect against unwanted deletion or corruption by the application, so let’s see what Resilience Hub recommends.
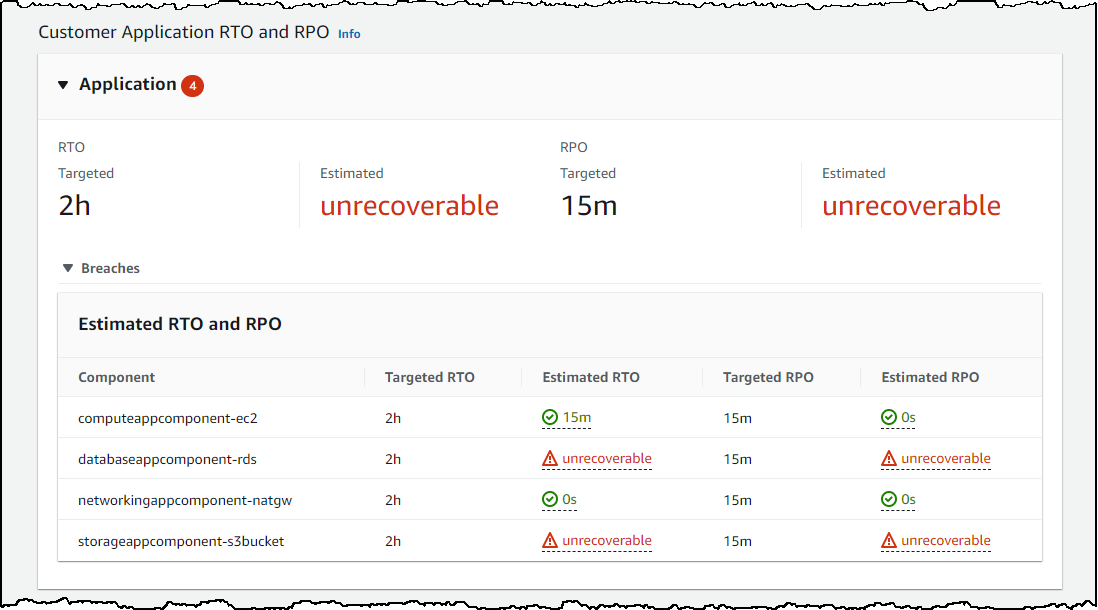
Figure 6. Resilience Hub component-level assessment of the multi-AZ architecture against customer application failures
As shown in Figure 7, for RDS, I can enable instance backup, with a suggested retention period of 7 days. By doing this, I can achieve an RPO of 5 minutes because using automatic backup in RDS allows me to restore a DB instance to any specific time during the backup retention period. The latest restorable time for a DB instance is typically within 5 minutes of the current time. The RTO is longer because it takes time to restore a new RDS instance from backup.

Figure 7. Resilience Hub suggestions to improve RDS resiliency in the architecture
As shown in Figure 8, for S3, it recommends I enable versioning. This feature allows me to roll back any change to an object (including deletion) to a last known good state. This means zero data loss and a 0s RPO.

Figure 8. Resilience Hub suggestions to improve S3 resiliency in the architecture
Let’s implement these suggestions!
Multi-AZ architecture with data backup
Figure 9 shows the multi-AZ architecture that incorporates data backup features.

Figure 9. Multi-AZ architecture incorporating data backup features
Resilience Hub has recommended more revisions to this architecture based on AWS Well-Architected Reliability best practices:
| Well-Architected Best Practice | Modification to Architecture |
| Identify and back up all data that needs to be backed up | The data in my RDS database and S3 bucket are backed up. |
| Perform data backup automatically | RDS backups are automatic. S3 object versioning is also automatic. |
Resilience Hub final assessment results
And…that’s it! You’ll see in Figure 10 that I’ve achieved the goals I set for RTO and RPO and my architecture is more resilient and reliable.

Figure 10. Resilience Hub assessment of the multi-AZ architecture after incorporating data backup features
Resilience Hub has even more recommendations for things I could improve. For example, if I switch from MySQL RDS to Amazon Aurora I can use backtracking to reduce the 1 hour 40 minute RTO that it takes to restore an RDS database backup. Backtracking “rewinds” the DB cluster to the time you specify, so you can restore a last known good state without needing to recreate the entire database from backup, which saves time and reduces RTO.
Conclusion
To improve the resiliency of your workloads, you need to apply the right best practices. This blog post shows you how Resilience Hub can help you assess and improve a workload with poor resiliency, identify areas for improvement, implement best practices, and evaluate how those practices meet your resiliency goals.