AWS Architecture Blog
How to Audit and Report S3 Prefix Level Access Using S3 Access Analyzer
Data Services teams in all industries are developing centralized data platforms that provide shared access to datasets across multiple business units and teams within the organization. This makes data governance easier, minimizes data redundancy thus reducing cost, and improves data integrity. The central data platform is often built with Amazon Simple Storage Service (Amazon S3).
A common pattern for providing access to this data is for you to set up cross-account IAM Users and IAM Roles to allow direct access to the datasets stored in S3 buckets. You then enforce the permission on these datasets with S3 Bucket Policies or S3 Access Point policies. These policies can be very granular and you can provide access at the bucket level, prefix level as well as object level within an S3 bucket.
To reduce risk and unintended access, you can use Access Analyzer for S3 to identify S3 buckets within your zone of trust (Account or Organization) that are shared with external identities. Access Analyzer for S3 provides a lot of useful information at the bucket level but you often need S3 audit capability one layer down, at the S3 prefix level, since you are most likely going to organize your data using S3 prefixes.
Common use cases
Many organizations need to ingest a lot of third-party/vendor datasets and then distribute these datasets within the organization in a subscription-based model. Irrespective of how the data is ingested, whether it is using AWS Transfer Family service or other mechanisms, all the ingested datasets are stored in a single S3 bucket with a separate prefix for each vendor dataset. The hierarchy can be represented as:
vendor-s3-bucket
->vendorA-prefix
->vendorA.dataset.csv
->vendorB-prefix
->vendorB.dataset.csv
Based on this design, access is also granted to the data subscribers at the S3 prefix level. Access Analyzer for S3 does not provide visibility at the S3 prefix level so you need to develop custom scripts to extract this information from the S3 policy documents. You also need the information in an easy-to-consume format, for example, a csv file, that can be queried, filtered, readily downloaded and shared across the organization.
To help address this requirement, we show how to implement a solution that builds on the S3 access analyzer findings to generate a csv file on a pre-configured frequency. This solution provides details about:
- External Principals outside your trust zone that have access to your S3 buckets
- Permissions granted to these external principals (read, write)
- List of s3 prefixes these external principals have access to that is configured using S3 bucket policy and/or S3 access point policies.
Architecture Overview
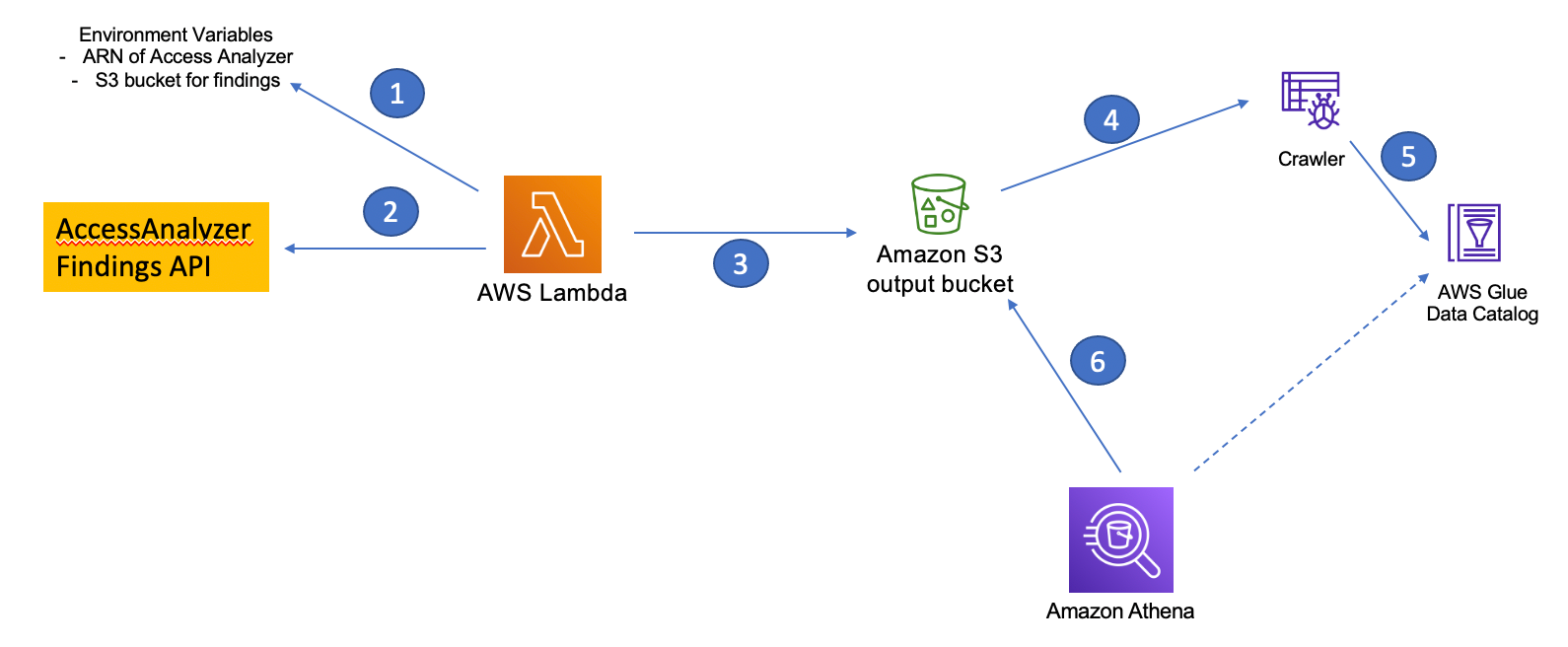
Figure 1 – How to Audit and Report S3 prefix level access using S3 Access Analyzer
The solution entails the following steps:
Step 1 – The Access Analyzer ARN and the S3 bucket parameters are passed to an AWS Lambda function via Environment variables.
Step 2 – The Lambda code uses the Access Analyzer ARN to call the list-findings API to retrieve the findings information and store it in the S3 bucket (under json prefix) in JSON format.
Step 3 – The Lambda function then also parses the JSON file to get the required fields and store it as a csv file in the same S3 bucket (under report prefix). It also scans the bucket policy and/or the access point policies to retrieve the S3 prefix level permission granted to the external identity. That information is added to the csv file.
Steps 4 and 5 – As part of the initial deployment, an AWS Glue crawler is provided to discover and create the schema of the csv file and store it in the AWS Glue Data Catalog.
Step 6 – An Amazon Athena query is run to create a spreadsheet of the findings that can be downloaded and distributed for audit.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account
- S3 buckets that are shared with external identities via cross-account IAM roles or IAM users. Follow these instructions in this user guide to set up cross-account S3 bucket access.
- IAM Access Analyzer enabled for your AWS account. Follow these instructions to enable IAM Access Analyzer within your account.
Once the IAM Access Analyzer is enabled, you should be able to view the Analyzer findings from the S3 console by selecting the bucket name and clicking on the ‘View findings’ box or directly going to the Access Analyzer findings on the IAM console.
When you select a ‘Finding id’ for an S3 Bucket, a screen similar to the following will appear:
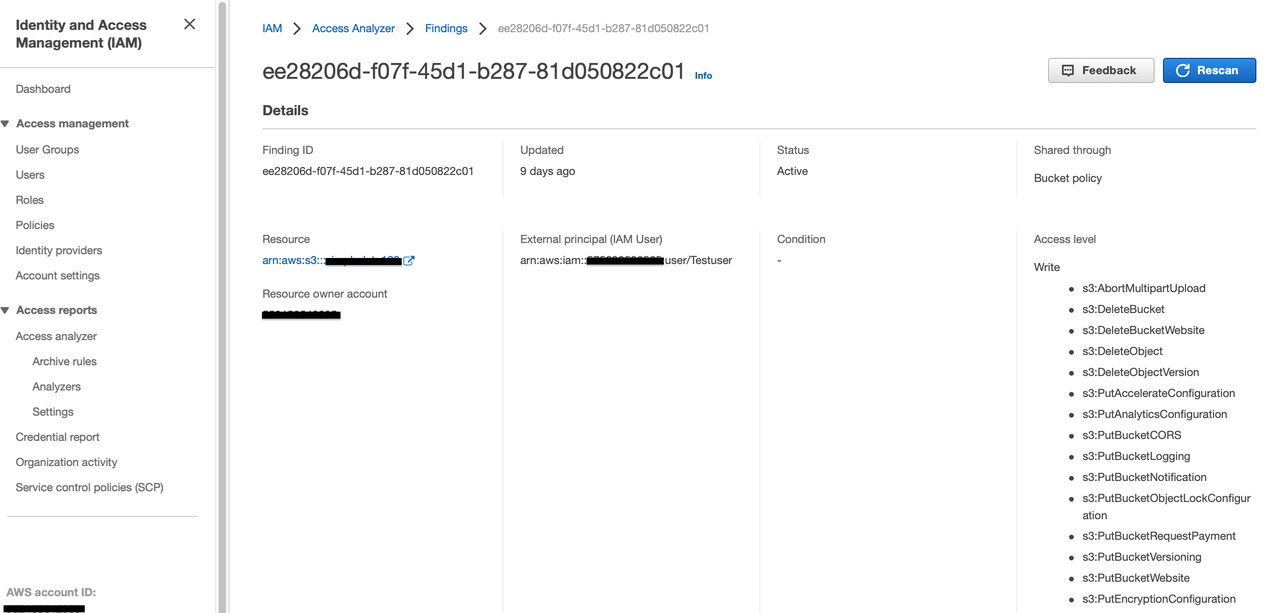
Figure 2 – IAM Console Screenshot
Setup
Now that your access analyzer is running, you can open the link below to deploy the CloudFormation template. Make sure to launch the CloudFormation in the same AWS Region where IAM Access Analyzer has been enabled.
Specify a name for the stack and input the following parameters:
- ARN of the Access Analyzer which you can find from the IAM Console.
- New S3 bucket where your findings will be stored. The Cloudformation template will add a suffix to the bucket name you provide to ensure uniqueness.
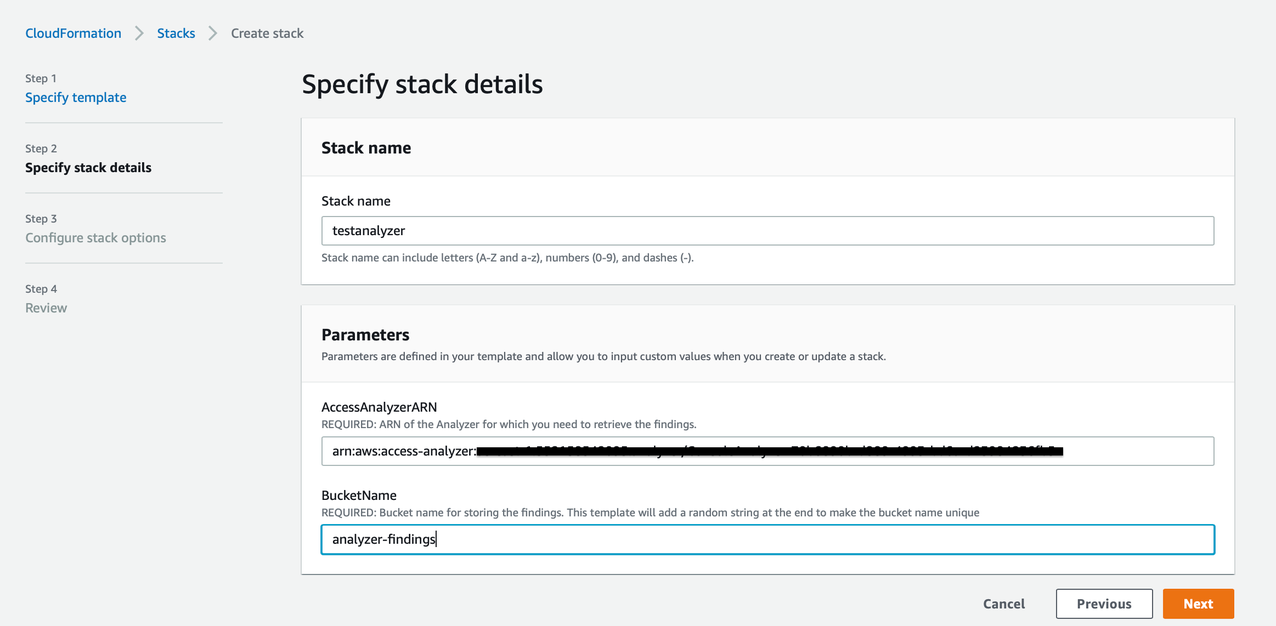
Figure 3 – CloudFormation Template screenshot
- Select Next twice and on the final screen check the box allowing CloudFormation to create the IAM resources before selecting Create Stack.
- It will take a couple of minutes for the stack to create the resources and launch the AWS Lambda function.
- Once the stack is in CREATE_COMPLETE status, go to the Outputs tab of the stack and note down the value against the DataS3BucketName key. This is the S3 bucket the template generated. It would be of the format analyzer-findings-<xxxxxxxxxxxx>. Go to the S3 console and view the contents of the bucket.
There should be two folders archive/ and report/. In the report folder you should have the csv file containing the findings report. - You can download the csv directly and open it in a excel sheet to view the contents. If would like to query the csv based on different attributes, follow the next set of steps.
Go to the AWS Glue console and click on Crawlers. There should be an analyzer-crawler created for you. Select the crawler to run it. - After the crawler runs successfully, you should see a new table, analyzer-report created under analyzerdb Glue database.
- Select the tablename to view the table properties and schema.
- To query the table, go to the Athena console and select the analyzerdb database. Then you can run a query like “Select * from analyzer-report where externalaccount = <<valid external account>>” to list all the S3 buckets the external account has access to.
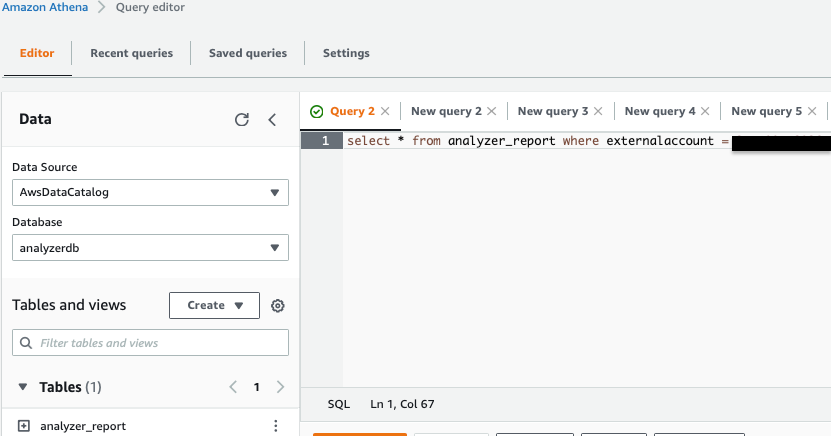
Figure 4 – Amazon Athena Console screenshot
The output of the query with a subset of columns is shown as follows:

Figure 5 – Output of Amazon Athena Query
This CloudFormation template also creates a Cloudwatch event rule, testanalyzer-ScheduledRule-<xxxxxxx>, that launches the Lambda function every Monday to generate a new version of the findings csv file. You can update the rule to set it to a frequency you desire.
Clean Up
To avoid incurring costs, remember to delete the resources you created. First, manually delete the folders ‘archive’ and ‘report’ in the S3 bucket and then delete the CloudFormation stack you deployed at the beginning of the setup.
Conclusion
In this blog, we showed how you can build audit capabilities for external principals accessing your S3 buckets at a prefix level. Organizations looking to provide shared access to datasets across multiple business units will find this solution helpful in improving their security posture. Give this solution a try and share your feedback!