AWS Architecture Blog
Running Multiple HTTP Endpoints as a Highly Available Health Proxy
Route 53 Health Checks provide the ability to verify that endpoints are reachable and that HTTP and HTTPS endpoints successfully respond. However, there are many situations where DNS failover would be useful, but TCP, HTTP, and HTTPS health checks alone can’t sufficiently determine the health of the endpoint. In these cases, it’s possible for an application to determine its own health, and then use an HTTP endpoint as a health proxy to Route 53 Health Checks to perform DNS failover. Today we’ll look at an example using Route 53 Health Checks to provide DNS failover between many pairs of primary and standby databases.
Determining the Health Status of Resources
In this example, we have many pairs of primary and standby databases. For each pair, we would like to perform DNS failover from the primary to the standby whenever the primary is unable to respond to queries. Each of these pairs is independent of the others, so one primary database failing over should not have any impact on the remaining databases.
The existing Route 53 health check types aren’t really sufficient to determine the health of a database. A TCP health check could determine if the database was reachable, but not if it was able to respond to queries. In addition, we’d like to switch to the standby not only if the primary is unable to answer queries, but also proactively if we need to perform maintenance or updates on the primary.
Reporting Health
Having determined the criteria for failing over a database, we’ll then want to provide this information to Route 53 to perform DNS failover. Since the databases themselves can’t meaningfully respond to health checks, we set up an HTTP endpoint to respond to health checks on behalf of the databases. This endpoint will act as a health proxy for the database, responding to health checks with HTTP status 200 when the database is healthy and HTTP status 500 when the database is unhealthy. We can also use a single HTTP endpoint to publish the health of all our databases. Since HTTP health checks can specify a resource path in addition to IP address and port, we can assign a unique resource path for each database.
To pull the information into Route 53, we then create an HTTP health check for each database. These health checks will all use the HTTP endpoint’s IP address and port, and each will have a unique resource path specific to the database we want to check. For example, in the diagram below, we see that the primary uses a path of “/DB1Primary” while the standby database uses a path of “/DB1Standby” on the same IP address endpoint.
We also configure the health checks with a failure threshold of 1 and interval of 10 seconds to better suit our use case. The default interval of 30 seconds and failure threshold of 3 are useful when we want Route 53 to determine the health of an endpoint, but in this case we already know the health of the endpoint and are simply using health checks to surface this information. By setting the failure threshold to 1, Route 53 immediately takes the result of the latest health check request. This means our health check will become unhealthy on the first health check request after the HTTP endpoint reports the database in unhealthy, rather than waiting for three unhealthy responses. We also use the 10 second interval to speed up our reaction time to an unhealthy database. With both of these changes, Route 53 should detect the HTTP endpoint becoming unhealthy within approximately 10 seconds instead of approximately 90 seconds.
Increasing Availability
At this point we have created health checks for our databases which could be associated with resource records sets for DNS failover. Although this works well for providing the health of the resource to Route 53, it does have a downside that traditional health checks don’t. If the health proxy itself fails, all health checks targeting it will time out and fail as well. This would prevent DNS failover for databases from working at all, and could result in all DNS queries responding with the standby database.
The first step to fixing this is to run more than one HTTP endpoint, each providing the status of the same resources. This way, if one of the endpoints fails, we’ll still have others to report the same information. We’ll then create a health check for each combination of database and HTTP endpoint. So if we run three HTTP endpoints, we’ll create three health checks for each database.
The diagram below shows how the HTTP endpoints receive health statuses from a single primary and standby database, and then pass it on to the Route 53 health checks. The bold line in the diagram depicts how the health status for a single database is sent by multiple HTTP endpoints to multiple Route 53 health checks.
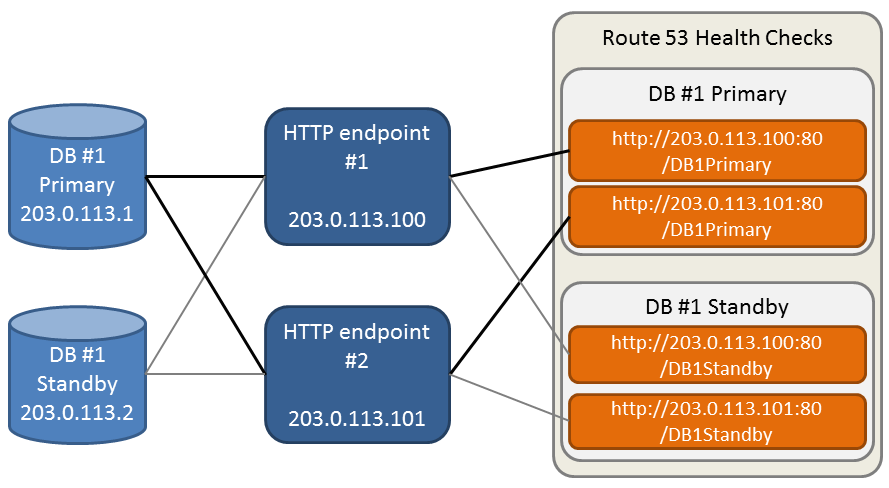
With multiple HTTP endpoints, we’ll want to consider the primary database as healthy if at least one HTTP endpoint reports that it is healthy, or if at least one of its health checks is healthy. We’ll want to failover if none of the primary health checks report healthy, but at least one of the standby’s health checks reports healthy. If none of the primary’s or standby’s health checks report healthy, we would rather respond with the primary’s IP than return nothing at all. This also provides the desired behavior in case all HTTP endpoints go down; we’ll respond with the primary database for all database pairs, rather than failing over all databases.
To configure this behavior, we use multiple weighted round robin (WRR) resource record sets for each database. Each database and health check will have a separate WRR set, with primaries being weighted one and standbys weighted zero. When all primary database’s health checks are healthy, Route 53 will randomly choose one the WRR sets for the primary database with a weight of one. Since all these contain the same value, the IP address of the primary database, it doesn’t matter which one is selected and we get the correct response. When all health checks for a primary DB are unhealthy, their WRR sets will not be considered and Route 53 will chose randomly from the healthy zero-weighted standby sets. Once again, these all return the same IP address so it doesn’t matter which of these is chosen. Finally, if all primary and standby health checks are unhealthy, Route 53 will consider all WRR sets and choose among the one-weighted primary records.
The diagram below shows an example of WRR sets configured for DNS failover of a single database.

Applications and Tradeoffs
While this post discussed using health proxies in the context of health checking databases, this same technique can be used to apply DNS failover to many other resources. This could be applied to any other resources which can’t easily be checked by TCP, HTTP, or HTTPS health checks, such as file servers, mail servers, etc. This could also be applied to use DNS failover for other criteria, such as manually moving traffic away from a resource for deployment or when the error rate for a service rises above 5%.
It’s also worth mentioning that there are some tradeoffs to this approach that may make it less useful for some applications. The biggest of these is that in this approach the health checks no longer provide a connectivity check to the actual endpoint of interest. Since we configured the health checks to target the HTTP endpoints, we would actually be checking the connectivity of the HTTP endpoints instead of the databases themselves. For the use case in this example, this isn’t a problem. The databases are usually queried from other hosts in the same region, so global connectivity isn’t a concern.
The other tradeoff is having to maintain additional hosts for the HTTP endpoints. In the above example, we have more database pairs than HTTP endpoints, so this is a relatively small cost. If we only had a few databases, this design would be much less sensible.
– John Winder