AWS News Blog
Amazon EMR 5.0.0 – Major App Updates, UI Improvements, Better Debugging, and More
The Amazon EMR team has been cranking out new releases at a fast and furious pace! Here’s a quick recap of this year’s launches:
- EMR 4.7.0 – Updates to Apache Tez, Apache Phoenix, Presto, HBase, and Mahout (June).
- EMR 4.6.0 – HBase for realtime access to massive datasets (April).
- EMR 4.5.0 – Updates to Hadoop, Presto; addition of Spark and EMRFS (April).
- EMR 4.4.0 – Sqoop, HCatalog, Java 8, and more (March).
- EMR 4.3.0 – Updates to Spark, Presto, and Ganglia (January).
Today the team is announcing and releasing EMR 5.0.0. This is a major release that includes support for 16 open source Hadoop ecosystem projects, major version upgrades for Spark and Hive, use of Tez by default for Hive and Pig, user interface improvements to Hue and Zeppelin, and enhanced debugging functionality.
Here’s a map that shows how EMR has progressed over the course of the past couple of releases:

Let’s check out the new features in EMR 5.0.0!
Support for 16 Open Source Hadoop Ecosystem Projects
We started using Apache Bigtop to manage the EMR build and packaging process during the development of EMR 4.0.0. The use of Bigtop helped us to accelerate the release cycle while we continued to add additional packages from the Hadoop ecosystem, with a goal of making the newest GA (generally available) open source versions accessible to you as quickly as possible.
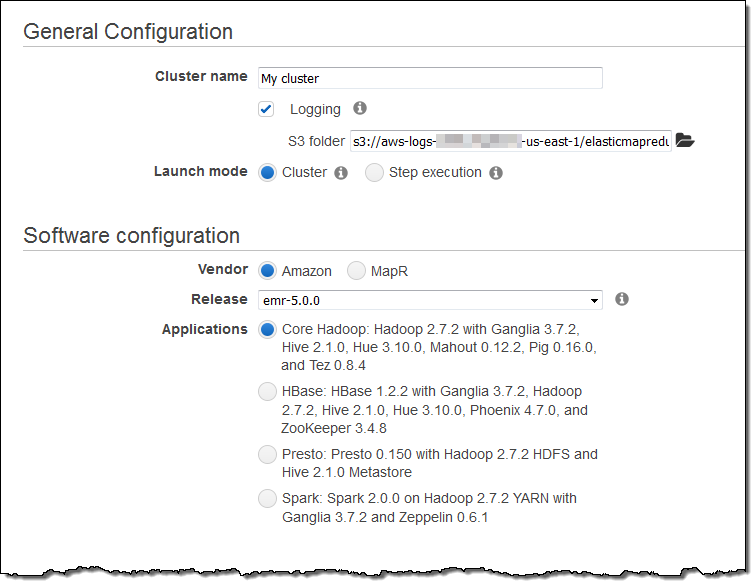
In accord with our goal, EMR 5.0 includes support for 16 Hadoop ecosystem projects including Apache Hadoop, Apache Spark, Presto, Apache Hive, Apache HBase, and Apache Tez. You can choose the desired set of apps when you create a new EMR cluster:
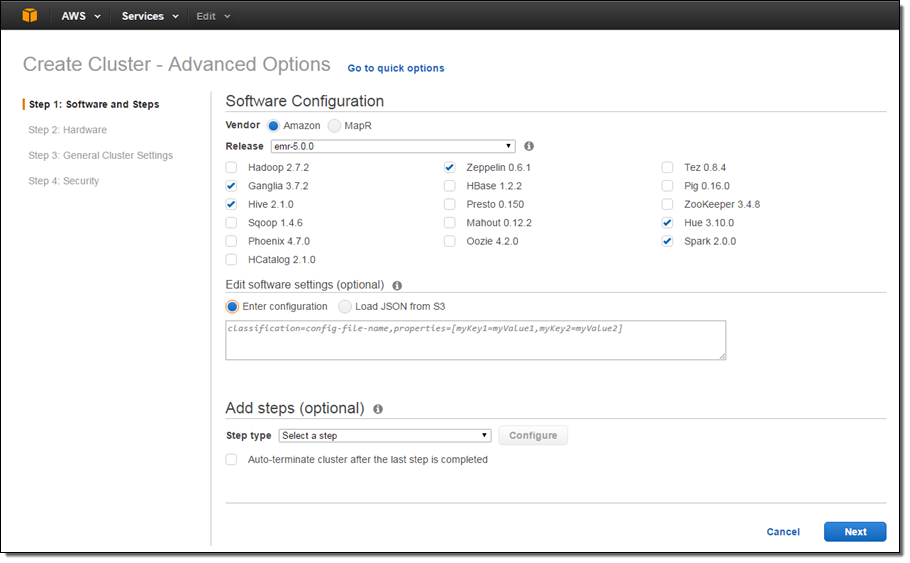
Major Version Upgrade for Spark and Hive
This release of EMR updates Hive (a SQL-like interface for Tez and Hadoop MapReduce) from 1.0 to 2.1, accompanied by a move to Java 8. It also updates Spark (an engine for large-scale data processing) from 1.6.2 to 2.0, with a similar move to Scala 2.11. The Spark and Hive updates are both major releases and include new features, performance enhancements, and bug fixes. For example, Spark now includes a Structured Streaming API, better SQL support, and more. Be aware that the new versions of Spark and Hive are not 100% backward compatible with the old ones; check your code and upgrade to EMR 5.0.0 with care.
With this release, Tez is now the default execution engine for Hive 2.1 and Pig 0.16, replacing Hadoop MapReduce and resulting in better performance, including reduced query latency. With this update, EMR uses MapReduce only when running a Hadoop MapReduce job directly (Hive and Pig now use Tez; Spark has its own framework).
User Interface Improvements
EMR 5.0.0 also updates Apache Zeppelin (a notebook for interactive data analytics) from 0.5.6 to 0.6.1, and Hue (an interface for analyzing data with Hadoop) from 3.7.1 to 3.10. The new versions of both of these web-based tools include new features and lots of smaller improvements.
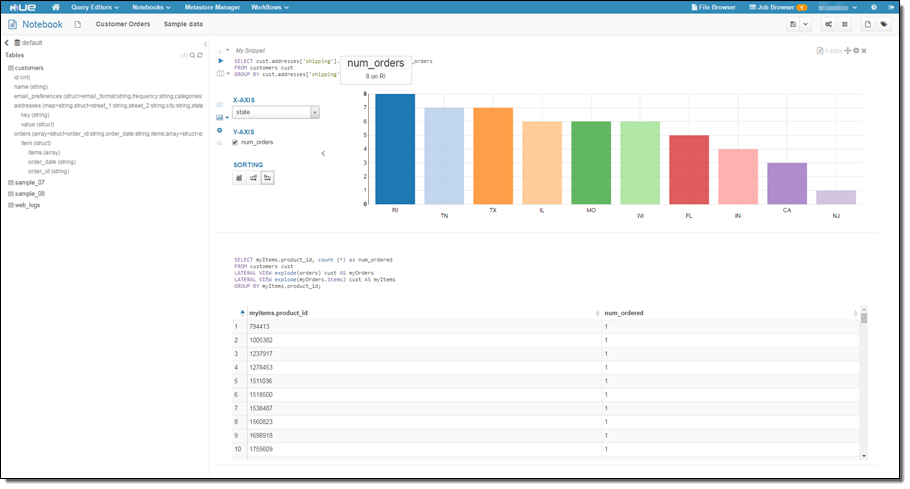
Zeppelin is often used with Spark; Hue works well with Hive, Pig, and HBase. The new version of Hue includes a notebooks feature that allows you to have multiple queries on the same page:
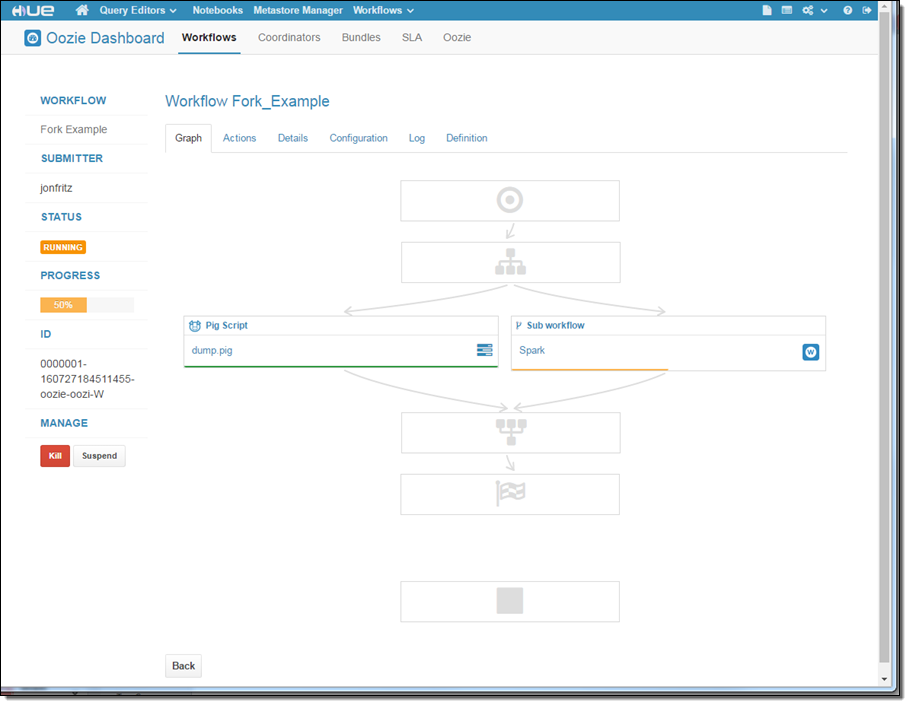
Hue can also help you to design Oozie workflows:
Enhanced Debugging Functionality
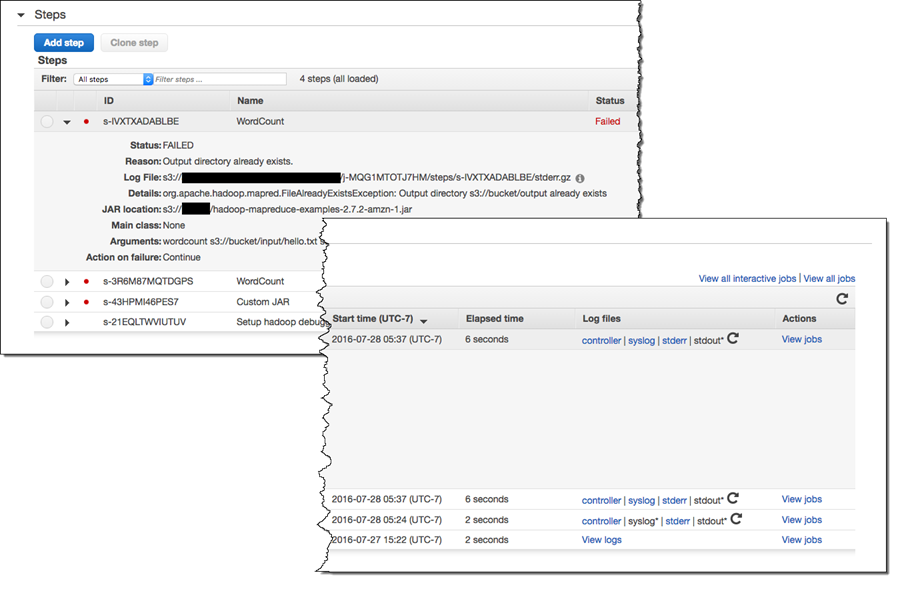
Finally, EMR 5.0.0 includes some better debugging functionality, making it easier for you to figure out why a particular step of your EMR job failed. The console now displays a partial stack track and links to the log file (stored in Amazon S3) in order to help you to find, troubleshoot, and fix errors:
 Launch a Cluster Today
Launch a Cluster Today
You can launch an EMR 5.0.0 cluster today in any AWS Region! Open up the EMR Console, click on Create cluster, and choose emr-5.0.0 from the Release menu:
Learn More
To learn more about this powerful new release of EMR, plan to attend our webinar or August 23rd, Introducing Amazon EMR Release 5.0: Faster, Easier, Hadoop, Spark, and Presto.
— Jeff;