AWS News Blog
Auto Scaling is now available for Amazon SageMaker
Kumar Venkateswar, Product Manager on the AWS ML Platforms Team, shares details on the announcement of Auto Scaling with Amazon SageMaker.
With Amazon SageMaker, thousands of customers have been able to easily build, train and deploy their machine learning (ML) models. Today, we’re making it even easier to manage production ML models, with Auto Scaling for Amazon SageMaker. Instead of having to manually manage the number of instances to match the scale that you need for your inferences, you can now have SageMaker automatically scale the number of instances based on an AWS Auto Scaling Policy.
SageMaker has made managing the ML process easier for many customers. We’ve seen customers take advantage of managed Jupyter notebooks and managed distributed training. We’ve seen customers deploying their models to SageMaker hosting for inferences, as they integrate machine learning with their applications. SageMaker makes this easy – you don’t have to think about patching the operating system (OS) or frameworks on your inference hosts, and you don’t have to configure inference hosts across Availability Zones. You just deploy your models to SageMaker, and it handles the rest.
Until now, you have needed to specify the number and type of instances per endpoint (or production variant) to provide the scale that you need for your inferences. If your inference volume changes, you can change the number and/or type of instances that back each endpoint to accommodate that change, without incurring any downtime. In addition to making it easy to change provisioning, customers have asked us how we can make managing capacity for SageMaker even easier.
With Auto Scaling for Amazon SageMaker, in the SageMaker console, the AWS Auto Scaling API, and the AWS SDK, this becomes much easier. Now, instead of having to closely monitor inference volume, and change the endpoint configuration in response, customers can configure a scaling policy to be used by AWS Auto Scaling. Auto Scaling adjusts the number of instances up or down in response to actual workloads, determined by using Amazon CloudWatch metrics and target values defined in the policy. In this way, customers can automatically adjust their inference capacity to maintain predictable performance at a low cost. You simply specify the target inference throughput per instance and provide upper and lower bounds for the number of instances for each production variant. SageMaker will then monitor throughput per instance using Amazon CloudWatch alarms, and then it will adjust provisioned capacity up or down as needed.
After you configure the endpoint with Auto Scaling, SageMaker will continue to monitor your deployed models to automatically adjust the instance count. SageMaker will keep throughput within desired levels, in response to changes in application traffic. This makes it easier to manage models in production, and it can help reduce the cost of deployed models, as you no longer have to provision sufficient capacity in order to manage your peak load. Instead, you configure the limits to accommodate your minimum expected traffic and the maximum peak, and Amazon SageMaker will work within those limits to minimize cost.
How do you get started? Open the SageMaker console. For existing endpoints, you first access the endpoint to modify the settings.
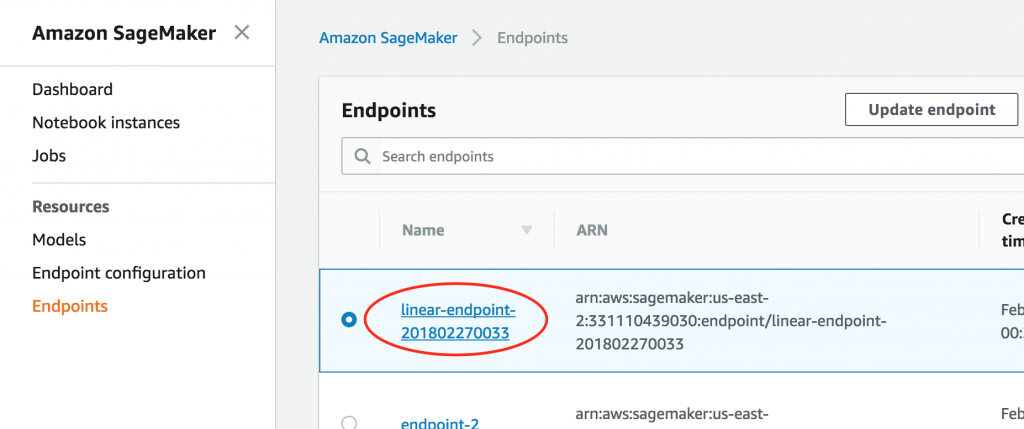
Then, scroll to the Endpoint runtime settings section, select the variant, and choose Configure auto scaling.
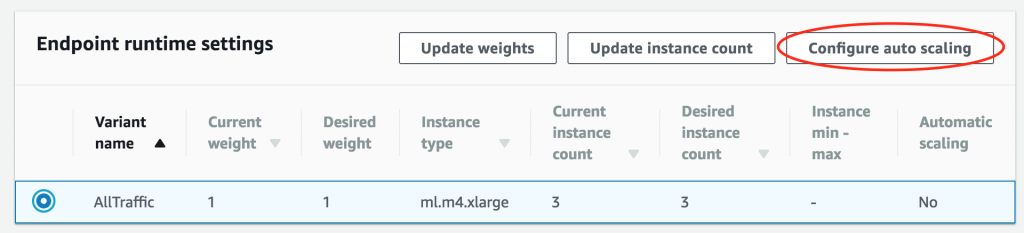
First, configure the minimum and maximum number of instances.
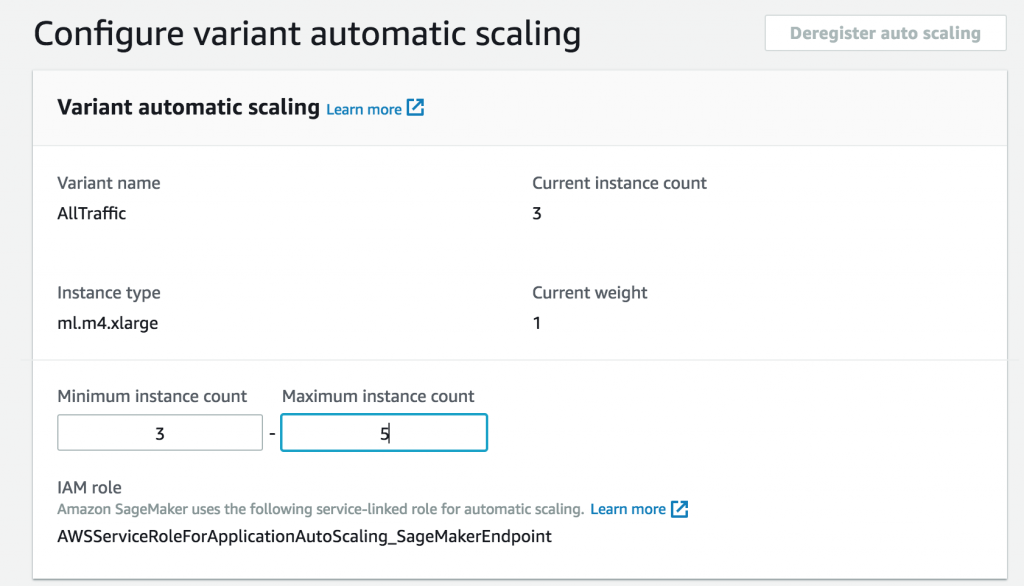
Next, choose the throughput per instance at which you want to add an additional instance, given previous load testing.
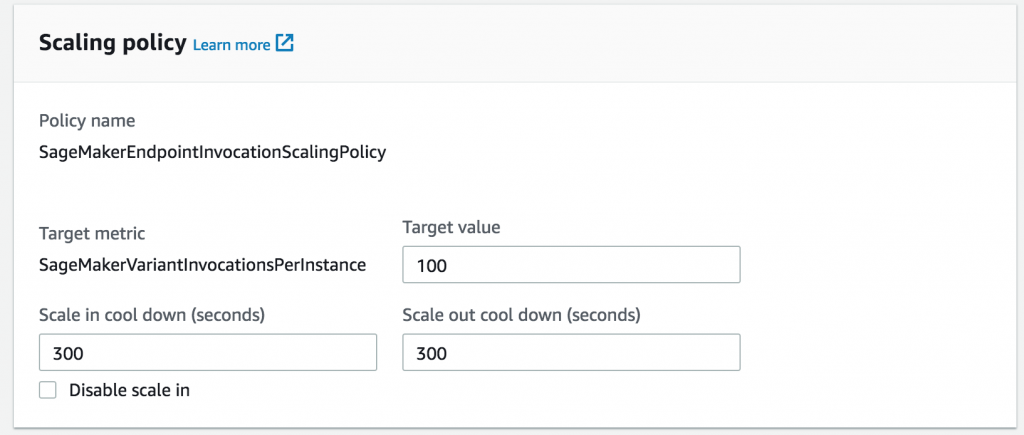
You can optionally set cool down periods for scaling in or out, to avoid oscillation during periods of wide fluctuation in workload. If not, SageMaker will assume default values.
And that’s it! You now have an endpoint that will automatically scale with increasing inferences.
You pay for the capacity used at regular SageMaker pay-as-you-go pricing, so you no longer have to pay for unused capacity during relative idle periods!
Auto Scaling in Amazon SageMaker is available today in the US East (N. Virginia & Ohio), EU (Ireland), and U.S. West (Oregon) AWS regions. To learn more, see the Amazon SageMaker Auto Scaling documentation.

Kumar Venkateswar is a Product Manager in the AWS ML Platforms team, which includes Amazon SageMaker, Amazon Machine Learning, and the AWS Deep Learning AMIs. When not working, Kumar plays the violin and Magic: The Gathering.
![]()