AWS News Blog
AWS Data Pipeline Now Supports Amazon Redshift
AWS Data Pipeline (see my introductory blog post for more information) is a web service that helps you to integrate and process data across compute and storage services at specified intervals. You can transform and process data that is stored in the cloud or on-premises in a highly scalable fashion without having to worry about resource availability, inter-task dependencies, transient failures, or timeouts.
Amazon Redshift (there’s a blog post for that one too) is a fast, fully managed, petabyte-scale data warehouse optimized for datasets that range from a few hundred gigabytes to a petabyte or more, and costs less than $1,000 per terabyte per year (about a tenth the cost of most traditional data warehousing solutions). As you can see from this post, we recently expanded the footprint and feature set of Redshift.
Pipeline, Say Hello to Redshift
Today we are connecting this pair of powerful AWS services; Amazon Redshift is now natively supported within the AWS Data Pipeline. This support is implemented using two new activities:
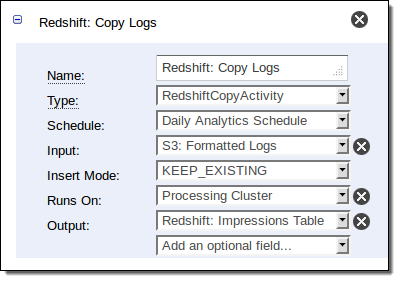
The RedshiftCopyActivity is used to bulk copy data from Amazon DynamoDB or Amazon S3 to a new or existing Redshift table. You can use this new power in a variety of different ways. If you are using Amazon RDS to store relational data or Amazon Elastic MapReduce to do Hadoop-style parallel processing, you can stage data in S3 before loading it into Redshift.
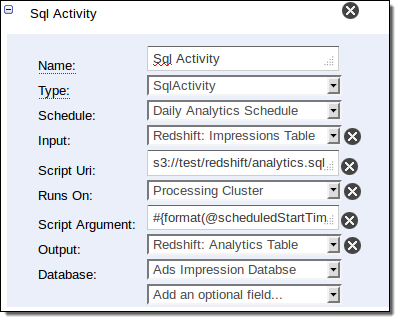
The SqlActivity is used to run SQL queries on data stored in Redshift. You specify the input and output tables, along with the query to be run. You can create a new table for the output, or you can merge the results of the query into an existing table.
You can access these new activities using the graphical pipeline editor in the AWS Management Console, a new [Redshift Copy template], the AWS CLI, and the AWS Data Pipeline APIs.
Putting it Together
Let’s take a look at a representative use case. Suppose you run an ecommerce website and you push your clickstream logs into Amazon S3 every 15 minutes. Every hour you use Hive to clean the logs and combine them with customer data residing in a SQL database, load the data into Redshift, and perform SQL queries to compute statistics such as sales by region and customer segment on a daily basis. Finally, you store the daily results in Redshift for long-term analysis.
Here is how you would define this processing pipeline using the AWS Management Console:
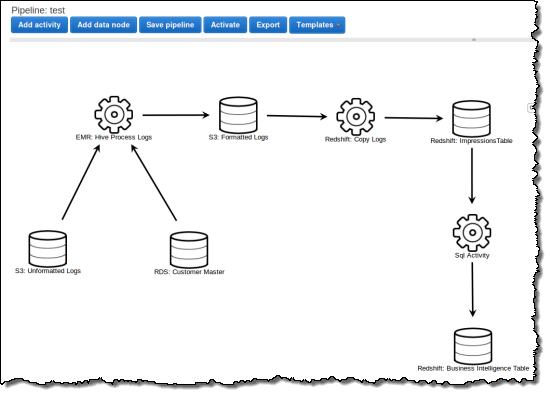
Here is how you define the activity that copies data from S3 to Redshift in the pipeline shown above:
And here is how you compute the statistics:
Start Now
The AWS Data Pipeline runs in the US East (Northern Virginia) Region. It supports access to Redshift in that region, along with cross-region workflows for Elastic MapReduce and DynamoDB. We plan to add cross-region access to Redshift in the future.
Begin by reading the Copy to Redshift documentation!
— Jeff;