AWS News Blog
Natural Language Processing at Clemson University – 1.1 Million vCPUs & EC2 Spot Instances
My colleague Sanjay Padhi shared the guest post below in order to recognize an important milestone in the use of EC2 Spot Instances.
— Jeff;
A group of researchers from Clemson University achieved a remarkable milestone while studying topic modeling, an important component of machine learning associated with natural language processing, breaking the record for creating the largest high-performance cluster in the cloud by using more than 1,100,000 vCPUs on Amazon EC2 Spot Instances running in a single AWS region. The researchers conducted nearly half a million topic modeling experiments to study how human language is processed by computers. Topic modeling helps in discovering the underlying themes that are present across a collection of documents. Topic models are important because they are used to forecast business trends and help in making policy or funding decisions. These topic models can be run with many different parameters and the goal of the experiments is to explore how these parameters affect the model outputs.
The Experiment
Professor Amy Apon, Co-Director of the Complex Systems, Analytics and Visualization Institute at Clemson University with Professor Alexander Herzog and graduate students Brandon Posey and Christopher Gropp in collaboration with members of the AWS team as well as AWS Partner Omnibond performed the experiments. They used software infrastructure based on CloudyCluster that provisions high performance computing clusters on dynamically allocated AWS resources using Amazon EC2 Spot Fleet. Spot Fleet is a collection of biddable spot instances in EC2 responsible for maintaining a target capacity specified during the request. The SLURM scheduler was used as an overlay virtual workload manager for the data analytics workflows. The team developed additional provisioning and workflow automation software as shown below for the design and orchestration of the experiments. This setup allowed them to evaluate various topic models on different data sets with massively parallel parameter sweeps on dynamically allocated AWS resources. This framework can easily be used beyond the current study for other scientific applications that use parallel computing.
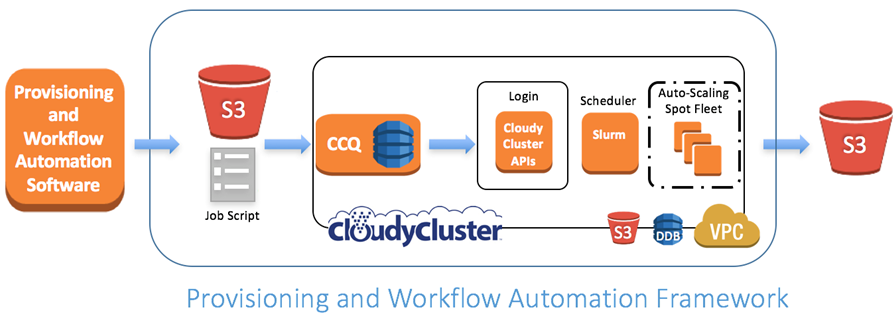
Ramping to 1.1 Million vCPUs
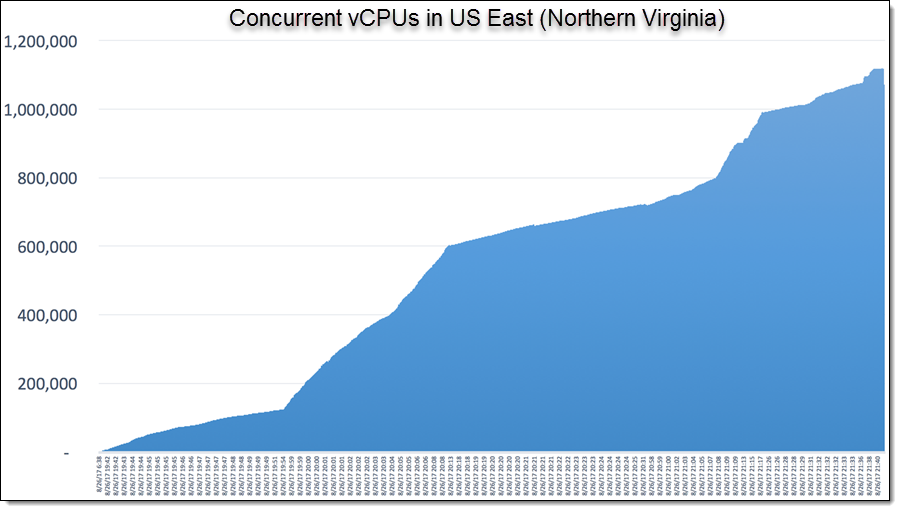
The figure below shows elastic, automatic expansion of resources as a function of time, in the US East (N. Virginia) Region. At just after 21:40 (GMT-1) on Aug. 26, 2017, the number of vCPUs utilized was 1,119,196. Clemson researchers also took advantage of the new per-second billing for the EC2 instances that they launched. The vCPU count usage is comparable to the core count on the largest supercomputers in the world.
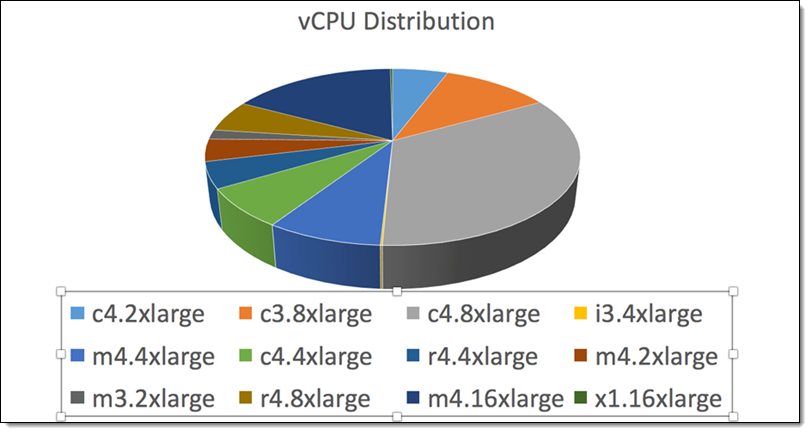
Here’s the breakdown of the EC2 instance types that they used:
Campus resources at Clemson funded by the National Science Foundation were used to determine an effective configuration for the AWS experiments as compared to campus resources, and the AWS cloud resources complement the campus resources for large-scale experiments.
Meet the Team
Here’s the team that ran the experiment (Professor Alexander Herzog, graduate students Christopher Gropp and Brandon Posey, and Professor Amy Apon):

Professor Apon said about the experiment:
I am absolutely thrilled with the outcome of this experiment. The graduate students on the project are amazing. They used resources from AWS and Omnibond and developed a new software infrastructure to perform research at a scale and time-to-completion not possible with only campus resources. Per-second billing was a key enabler of these experiments.
Boyd Wilson (CEO, Omnibond, member of the AWS Partner Network) told me:
Participating in this project was exciting, seeing how the Clemson team developed a provisioning and workflow automation tool that tied into CloudyCluster to build a huge Spot Fleet supercomputer in a single region in AWS was outstanding.
About the Experiment
The experiments test parameter combinations on a range of topics and other parameters used in the topic model. The topic model outputs are stored in Amazon S3 and are currently being analyzed. The models have been applied to 17 years of computer science journal abstracts (533,560 documents and 32,551,540 words) and full text papers from the NIPS (Neural Information Processing Systems) Conference (2,484 documents and 3,280,697 words). This study allows the research team to systematically measure and analyze the impact of parameters and model selection on model convergence, topic composition and quality.
Looking Forward
This study constitutes an interaction between computer science, artificial intelligence, and high performance computing. Papers describing the full study are being submitted for peer-reviewed publication. I hope that you enjoyed this brief insight into the ways in which AWS is helping to break the boundaries in the frontiers of natural language processing!
— Sanjay Padhi, Ph.D, AWS Research and Technical Computing