AWS News Blog
New – EC2 Instances Powered by Gaudi Accelerators for Training Deep Learning Models

|
There are more applications today for deep learning than ever before. Natural language processing, recommendation systems, image recognition, video recognition, and more can all benefit from high-quality, well-trained models.
The process of building such a model is iterative: construct an initial model, train it on the ground truth data, do some test inferences, refine the model and repeat. Deep learning models contain many layers (hence the name), each of which transforms outputs of the previous layer. The training process is math and processor intensive, and places demands on just about every part of the systems used for training including the GPU or other training accelerator, the network, and local or network storage. This sophistication and complexity increases training time and raises costs.
New DL1 Instances
Today I would like to tell you about our new DL1 instances. Powered by Gaudi accelerators from Habana Labs, the dl1.24xlarge instances have the following specs:
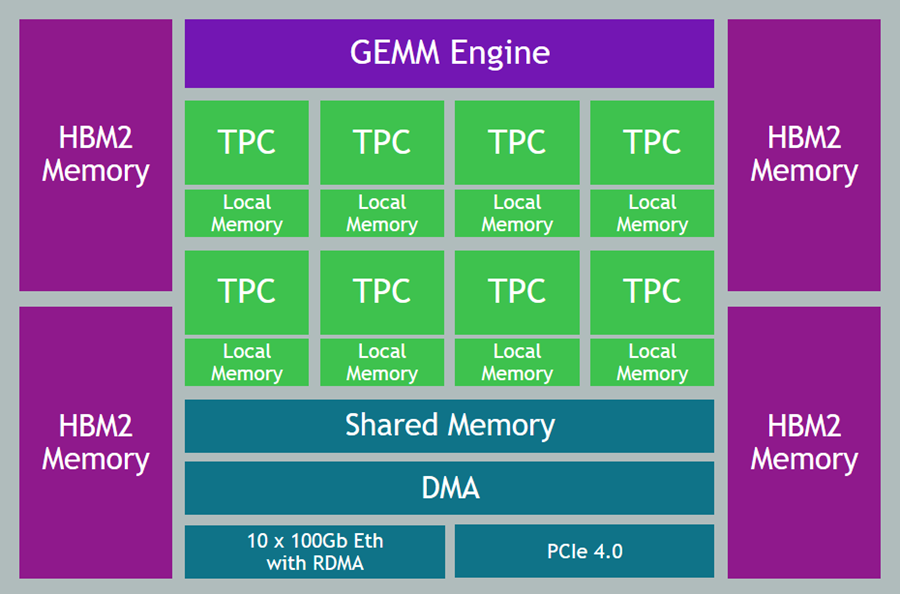
Gaudi Accelerators – Each instance is equipped with eight Gaudi accelerators, with a total of 256 GB of High Bandwidth (HBM2) accelerator memory and high-speed, RDMA-powered communication between accelerators.
System Memory – 768 GB of system memory, enough to hold very large sets of training data in memory, as often requested by our customers.
Local Storage – 4 TB of local NVMe storage, configured as four 1 TB volumes.
Processor – Intel Cascade Lake processor with 96 vCPUs.
Network – 400 Gbps of network throughput.
As you can see, we have maxed out the specs in just about every dimension, with the goal of giving you a highly capable machine learning training platform with a low cost of entry and up to 40% better price-performance than current GPU-based EC2 instances.
Gaudi Inside
The Gaudi accelerators are custom-designed for machine learning training, and have a ton of cool & interesting features & attributes:
Data Types – Support for floating point (BF16 and FP32), signed integer (INT8, INT16, and INT32), and unsigned integer (UINT8, UINT16, and UINT32) data.
Generalized Matrix Multiplier Engine (GEMM) – Specialized hardware to accelerate matrix multiplication.
Tensor Processing Cores (TPCs) – Specialized VLIW SIMD (Very Long Instruction Word / Single Instruction Multiple Data) processing units designed for ML training. The TPCs are C-programmable, although most users will use higher-level tools and frameworks.
Getting Started with DL1 Instances
The Gaudi SynapseAI Software Suite for Training will help you to build new models and to migrate existing models from popular frameworks such as PyTorch and TensorFlow:
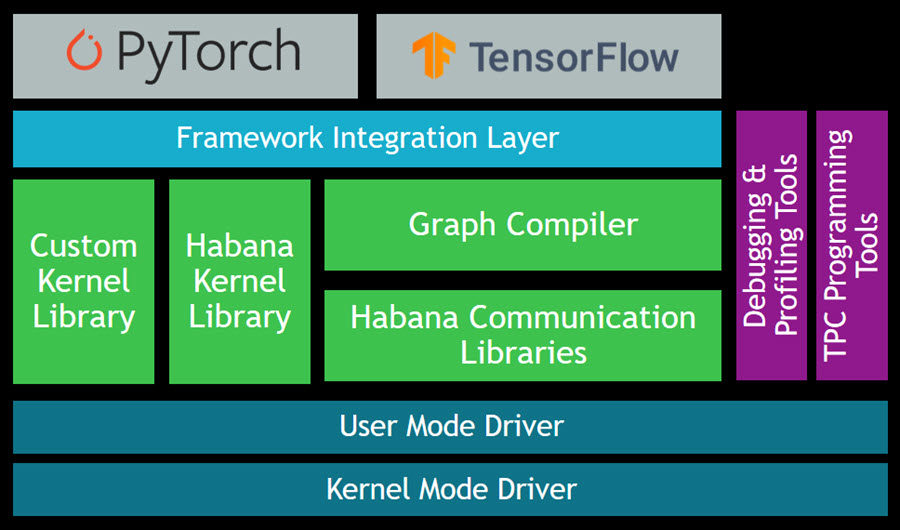
Here are some resources to get you started:
TensorFlow User Guide – Learn how to run your TensorFlow models on Gaudi.
PyTorch User Guide – Learn how to run your PyTorch models on Gaudi.
Gaudi Model Migration Guide – Learn how to port your PyTorch or TensorFlow to Gaudi.
HabanaAI Repo – This large, active repo contains setup instructions, reference models, academic papers, and much more.
You can use the TPC Programming Tools to write, simulate, and debug code that runs directly on the TPCs, and you can use the Habana Communication Library (HCL) to build applications that harness the power of multiple accelerators. The Habana Collective Communications Library (HCCL) runs atop HCL and gives you access to collective primitives for Reduce, Broadcast, Gather, and Scatter operations.
Now Available
DL1 instances are available today in the US East (N. Virginia) and US West (Oregon) Regions in On-Demand and Spot form. You can purchase Reserved Instances and Savings plans as well.
— Jeff;