AWS News Blog
New Elastic MapReduce Goodies: Apache Hive, Karmasphere Studio for Hadoop, Cloudera’s Hadoop Distribution

|
Earlier today, Amazon’s Peter Sirota took the stage at Hadoop World and announced a number of new goodies for Amazon Elastic MapReduce. Here’s what he revealed to the crowd:
Apache Hive Support
Elastic MapReduce now supports Apache Hive. Hive builds on Hadoop to provide tools for data summarization, ad hoc querying, and analysis of large data sets stored in Amazon S3. Hive uses a SQL-based language called Hive QL with support for map/reduce functions and complex extensible user defined data types such as JSON and Thrift. You can use Hive to process structured or unstructured data sources such as log files or text files. Hive is great for data warehousing applications such as data mining and click stream analysis.
We’ve got some great resources to help you to get started with Hive including a Hive and MapReduce Articles and Tutorials, a video, and a sample Advertising tuning application.
You may also want to read Cloudera’s article on Grouping Related Trends with Hadoop and Hive. This article examines the Hive and Python code used to implement the Trending Topics site.
Karmasphere Studio For Hadoop
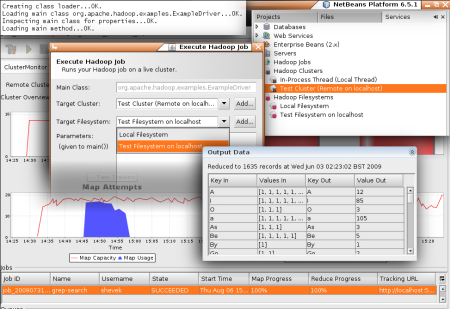
Amazon Elastic MapReduce is now supported by Karmasphere Studio For Hadoop. Based on the popular NetBeans IDE, Hadoop Studio supports development, debugging, and deployment of job flows directly from your desktop to Elastic MapReduce.
Cloudera’s Hadoop Distribution
Peter also announced that a private beta release of Amazon Elastic MapReduce support for Cloudera’s Hadoop distribution. Cloudera customers can obtain a support contract to gain access to custom Hadoop patches and help with the development and optimization of processing pipelines.
These new tools give you the power to process gigantic data sets while keeping you at arms-length from some of the more complex aspects of parallel programming. You don’t have to find a server cluster, install a bunch of software, coordinate and synchronize processes, copy data between servers, or negotiate with your colleagues for access to shared resources. These tools reduce the distance between the problem and the solution and allow you to spend your time on the more interesting aspects of your work.
If you’ve used Elastic MapReduce and Hive to do something interesting, leave a comment or a link to more info. We love to hear from our users!
— Jeff;