AWS News Blog
New G2 Instance Type with 4x More GPU Power
The GPU-powered G2 instance family is home to molecular modeling, rendering, machine learning, game streaming, and transcoding jobs that require massive amounts of parallel processing power. The NVIDIA GRID GPU includes dedicated, hardware-accelerated video encoding; it generates an H.264 video stream that can be displayed on any client device that has a compatible video codec. Here’s the block diagram from my original post:
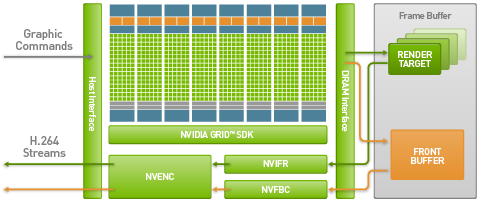
Today we are adding a second member to the G2 family. The new g2.8xlarge instance has the following specifications:
- Four NVIDIA GRID GPUs, each with 1,536 CUDA cores and 4 GB of video memory and the ability to encode either four real-time HD video streams at 1080p or eight real-time HD video streams at 720P.
- 32 vCPUs.
- 60 GiB of memory.
- 240 GB (2 x 120) of SSD storage.
This new instance size was designed to meet the needs of customers who are building and running high-performance CUDA, OpenCL, DirectX, and OpenGL applications.
From our Customers
AWS customer OpenEye Scientific provides software to the pharmaceutical industry for molecular modeling and cheminformatics. The additional memory and compute power of the g2.8xlarge allows them to accelerate their modeling and shape-fitting process. Brian Cole (their GPU Computing Lead) told us:
 FastROCS is an extremely fast shape comparison application, based on the idea that molecules have similar shape if their volumes overlay well and any volume mismatch is a measure of dissimilarity. The unprecedented speed of FastROCS represents a paradigm shift in the potential for 3D shape screening as part of the drug discovery process. To meet the high performance of FastROCS on NVIDIA GPUs, the molecular database must reside in main memory.
FastROCS is an extremely fast shape comparison application, based on the idea that molecules have similar shape if their volumes overlay well and any volume mismatch is a measure of dissimilarity. The unprecedented speed of FastROCS represents a paradigm shift in the potential for 3D shape screening as part of the drug discovery process. To meet the high performance of FastROCS on NVIDIA GPUs, the molecular database must reside in main memory.
The 15GB of memory provided by the g2.2xlarge was a limiting factor in OpenEye’s ability to use AWS for FastROCS. The only piece of our cloud offering not yet running in AWS is an on-premises dedicated FastROCS machine. Now that the g2.8xlarge instance provides nearly four times more memory, FastROCS can be run on production-sized pharmaceutically-relevant datasets in AWS.
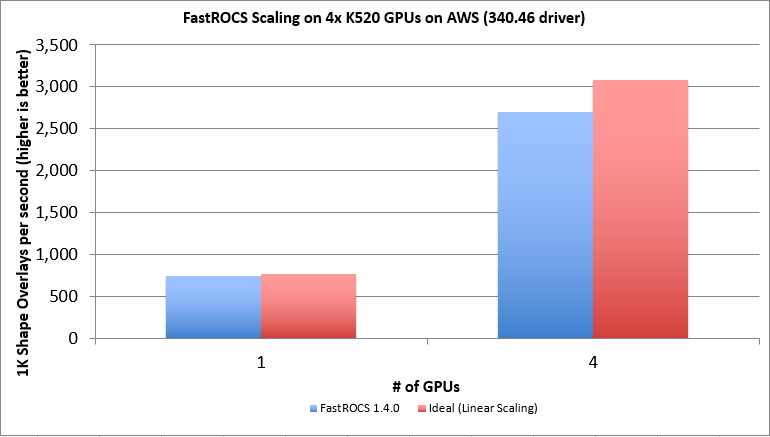
In addition, we have observed a four times performance increase from scaling across four GPUs on the g2.8xlarge instance. This will bring with it all the great flexibility and maintainability we have come to rely on from the AWS cloud.
Here’s a visual representation of the scaling that they have been able to achieve by using all four GPUs in a g2.8xlarge instance:
AWS customer OTOY builds GPU-based software that is designed to create cutting-edge digital content. Their AWS-powered Octane Render Cloud (ORC) provides users with high-quality, cloud-based rendering.
3D artists and visual effects (VFX) houses can use ORC to access essentially unlimited rendering capacity (including computationally intensive tasks such as light fields and path-traced cloud gaming), all powered by EC2 instances equipped with GPUs. This frees up their local workstations for creative work.
ORC’s web-based UI allows users to log in, upload projects, and create render jobs. The jobs are rendered on g2.2xlarge and g2.8xlarge instances and the user receives an email notification when the rendering is complete. Visual assets are deduplicated and stored in S3; this allows for space efficiency even if render scenes from different users make use of some of the same assets.
Brigade is OTOY’s real-time GPU path tracer. They are currently using ORC to port Octane scenes to Brigade for live, path-traced cloud gaming. Take a look at this video to see what this looks like:

Finally, AWS customer Butterfly Network (“Transforming Diagnostic and Therapeutic Imaging with Devices, Deep Learning, and the Cloud”) uses the g2.8xlarge to support their machine learning platform. Alex Rothberg (Senior Scientist) told us:
 With the benefit of the new g2.8xlarge instances, we can now leverage data parallelism across multiple GPUs to speed up training our neural networks. This will allow us to more rapidly iterate on deep learning methods which will enable us to democratize medical imaging.
With the benefit of the new g2.8xlarge instances, we can now leverage data parallelism across multiple GPUs to speed up training our neural networks. This will allow us to more rapidly iterate on deep learning methods which will enable us to democratize medical imaging.
Go GPU Today!
You can launch these instances today in the US East (N. Virginia), US West (N. California), US West (Oregon), Europe (Ireland), Asia Pacific (Singapore), and Asia Pacific (Tokyo) regions today in On-Demand or Spot form; Reserved Instances are also available.
— Jeff;