AWS News Blog
New Public Data Set: Wikipedia XML Data

|
Weighing in at a whopping 500 GB (388 GB of data and 112 GB of free space to allow for some in-place decompression), the Wikipedia XML data is our newest Public Data Set.
This data set contains all of the Wikimedia wikis in the form of wikitext source and metadata embedded in XML. We’ll be updating this data set every month and we’ll keep the sets for the previous three months around.
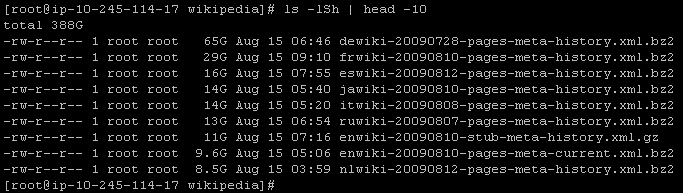
As you can see from this screen shot of my PuTTY window, there are some pretty beefy files in this data set:
As an example of what can be done with this data, take a look at Cloudera’s blog post on Grouping Related Trends with Hadoop and Hive. This article shows how to create a trend tracking site using a Cloudera Hadoop cluster running on EC2, using Apache Hive queries to process the data.
— Jeff;