AWS News Blog
New – Store and Process Graph Data using the DynamoDB Storage Backend for Titan
Graph databases elegantly and efficiently represent entities (generally known as vertices or nodes) and relationships (edges) that connect them. Here’s a very simple example of a graph:

Bill and Candace have a daughter named Janet, and she has a son named Bob. This makes Candace Bob’s grandmother, and Bill his grandfather.
Once a graph has been built, it is processed by traversing the edges between the vertices. In the graph above, we could traverse from Bill to Janet, and from there to Bob. Graphs can be used to model social networks (friends and “likes”), business relationships (companies, employees, partners, suppliers, and customers), dependencies, and so forth. Both vertices and edges can be typed; some vertices could be people as in our example, and others places. Similarly some edges could denote (as above) familial relationships and others could denote “likes.” Every graph database allows additional information to be attached to each vertex and to each edge, often in the form of name-value pairs.
Titan is a scalable graph database that is optimized for storing and querying graphs that contain hundreds of billions of vertices and edges. It is transactional, and can support concurrent access from thousands of users.
DynamoDB Storage Backend for Titan
Titan’s pluggable data storage layer already supports several NoSQL databases and key-value stores. This allows you to choose the backend that provides the performance and features required by your application, while giving you the freedom to switch from one backend to another with minimal changes to your application code.
Today we are making a new DynamoDB Storage Backend for Titan available. Storing your Titan graphs in Amazon DynamoDB lets you scale to handle huge graphs without having to worry about building, running, or maintaining your own database cluster. Because DynamoDB can scale to any size and provides high data availability and predictable performance, you can focus on your application instead of on your graph storage and processing infrastructure. You can also run Titan and DynamoDB Local on your laptop for development and testing.
The backend works with versions 0.4.4 and 0.5.4 of Titan. Both versions support fast traversals, edges that are both directed and typed, and stored relationships. The newer version adds support for vertex partitioning, vertex labels, and user defined transaction logs. The backend is client-based; we did not make any changes to DynamoDB to support it. You are simply using DynamoDB as an efficient way to store your Titan graphs.
Version 0.4.4 of Titan is compatible with version 2.4 of the Tinkerpop stack; version 0.5.4 of Titan is compatible with version 2.5 of the stack. Tinkerpop is a collection of tools and algorithms that provides you with even more in the way of graph processing and analysis options.
Since I am talking about graphs, I should illustrate all of the items that I have talked about in the form of a graph! Here you go:
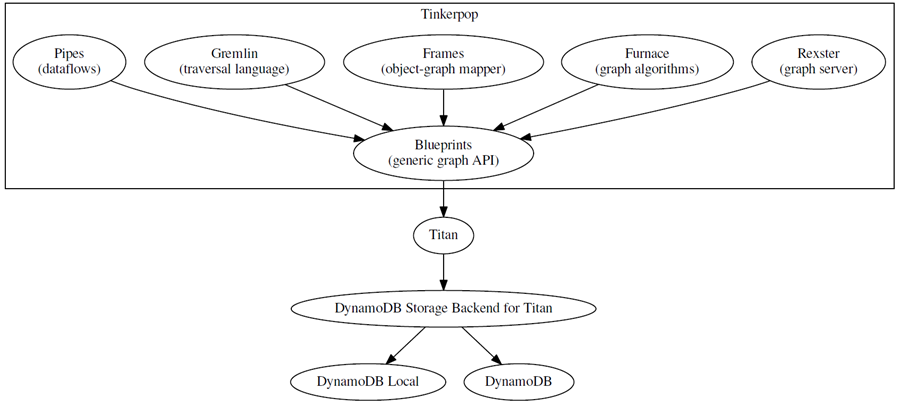
My colleague Alex Patrikalakis created the following Gremlin script. It replicates the graph above using Titan and DynamoDB:
conf = new BaseConfiguration()
conf.setProperty("storage.backend", "com.amazon.titan.diskstorage.dynamodb.DynamoDBStoreManager")
conf.setProperty("storage.dynamodb.client.endpoint", "http://localhost:4567")
g = TitanFactory.open(conf)
titan = g.addVertex(null, [name:"Titan"])
blueprints = g.addVertex(null, [name:"Blueprints"])
pipes = g.addVertex(null, [name:"Pipes"])
gremlin = g.addVertex(null, [name:"Gremlin"])
frames = g.addVertex(null, [name:"Frames"])
furnace = g.addVertex(null, [name:"Furnace"])
rexster = g.addVertex(null, [name:"Rexster"])
DynamoDBStorageBackend = g.addVertex(null, [name:"DynamoDB Storage Backend for Titan"])
DynamoDBLocal = g.addVertex(null, [name:"DynamoDB Local"])
DynamoDB = g.addVertex(null, [name:"DynamoDB"])
g.addEdge(titan, blueprints, "implements")
g.addEdge(pipes, blueprints, "builds-on")
g.addEdge(gremlin, blueprints, "builds-on")
g.addEdge(frames, blueprints, "builds-on")
g.addEdge(furnace, blueprints, "builds-on")
g.addEdge(rexster, blueprints, "builds-on")
g.addEdge(titan, DynamoDBStorageBackend, "backed-by")
g.addEdge(DynamoDBStorageBackend, DynamoDBLocal, "connects-to")
g.addEdge(DynamoDBStorageBackend, DynamoDB, "connects-to")
g.commit()
Getting Started
The DynamoDB Storage Backend for Titan is available as a Maven project on GitHub. It runs on Windows, OSX, and Linux and requires Maven and Java 1.7 (or later). The Amazon DynamoDB Storage Backend for Titan includes installation instructions and an example that makes creative use of the Marvel Universe Social Graph public dataset. We have also created a CloudFormation template that will launch an EC2 instance that has the Titan/Rexster stack and the DynamoDB Storage Backend for Titan installed and ready to use.
— Jeff;