AWS News Blog
Run Amazon Elastic MapReduce on EC2 Spot Instances

|
We’ve combined two popular Amazon EC2 features Spot Instances and Elastic MapReduce to allow you to launch managed Hadoop clusters using unused EC2 capacity. You will be able to run long-running jobs, cost-driven workloads, data-critical workloads, and application testing at a discount that has historically ranged between 50% and 66%.
What
The EC2 instances used to run an Elastic MapReduce job flow fall in to one of three categories or instance groups:
Master– The Master instance group contains a single EC2 instance. This instance schedules Hadoop tasks on the Core and Task nodes.
Core – The Core instance group contains one or more EC2 instances. These instances use HDFS to store the data for the job flow. They also run mapper and reducer tasks as specified in the job flow. This group can be expanded in order to accelerate a running job flow.
Task – The Task instance group contains zero or more EC2 instances and runs mapper and reduce tasks. Since they don’t store any data, this group can expand or contract during the course of a job flow.
You can choose to use either On-Demand or Spot Instances for each of your job flows. If you run your Master or Core groups on Spot Instances, these instances will be terminated if the market price rises above your bid price, and the entire job flow will fail. If you run your Task group on Spot Instances, the unfinished work running on those instances will be returned to the processing queue.
If you have purchased one or more EC2 Reserved Instances, Elastic MapReduce will also take advantage of them (this is not new but I wanted to make sure that you knew about it).
When
Here are some guidelines to get you started with Elastic MapReduce on Spot Instances:
Long-running Job Flows and Data Warehouses – If you maintain a long-running Elastic MapReduce cluster with some predictable variations in load, you can handle peak demand at lower cost using Spot Instances. Run the Master and Core instance groups on On-Demand instances and supplement the cluster with Spot Instances in a Task instance group at peak times.
Cost-Driven Workloads – If your jobs are relatively short-lived (generally several hours or less), the time to completion is less important than the cost, and losing partial work is acceptable, run the entire job flow on Spot Instances for the largest potential cost savings.
Data-Critical Workloads – If the overall cost is more important than the time to completion and you don’t want to lose any partial work, run the Master and Core instance groups on On-Demand instances, making sure that you run enough Core instance groups to hold all of your data in HDFS. Add Spot Instances as needed to reduce the overall processing speed and the total cost.
Application Testing – If you want to test an entire application before moving it to production, run the entire job (Master and Core instance groups) on Spot Instances.
How
You can start to use Spot Instances for all or part of a job flow by specifying a bid price for one or more of the flow’s instance groups. You can do this from the AWS Management Console, the command line, or the Elastic MapReduce APIs. To determine how that maximum price compares to past Spot Prices, the Spot Price history for the past 90 days is available via the EC2 API and the AWS Management Console. Here’s a screen shot of the AWS Management Console. As you can see, all you need to do is to check “Request Spot Instances” and enter a Spot Bid Price to benefit from Spot Instances:
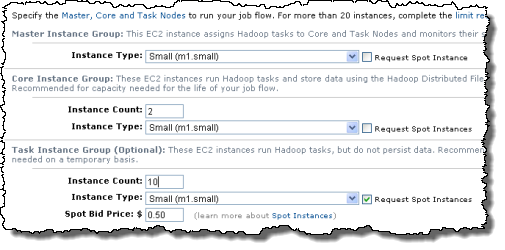
You can also add additional TASK instance groups to a running job flow and you can specify a bid price for the instances as you add each group. You could use this feature to create a layered set of bids if you’d like. As you probably know, each job flow is limited to 20 EC2 instances by default. If you would like to run larger job flows, you need to fill out the instance request form.
Who
We expect that Elastic MapReduce users with several types of job flows will really enjoy and make good use of Spot Instances. Two areas that come to mind are:
- Batch-processing workloads that are not particularly time-sensitive such as image and video processing, data processing for scientific research, financial modeling, and financial analysis.
- Data warehouses that have a recurring workload variance at peak times.
Our customers have been using Elastic MapReduce to process large volumes of data quickly and economically. For example:
Fliptop (full case study) helps brands convert email lists into social media profiles. They are able to do this using Spot Instances and have realized a cost savings of over 50%.
Foursquare (full case study) performs analytics across more than 3 million daily check-ins using Elastic MapReduce, Spot Instances, Amazon S3, MongoDB, and Apache Flume. This is what Matthew Rathbone of Foursquare told us:
Elastic MapReduce had already significantly reduced the time, effort, and cost of using Hadoop to generate customer insights. Now, by expanding our clusters with Spot Instances, we have reduced our analytics costs by over 50% while decreasing processing time for urgent data-analysis, all without requiring additional application development or adding risk to our analytics.
Watch
We have put together a new video, using EC2 Spot Instances with EMR, to show you how to run an Elastic MapReduce job using a combination of On-Demand and Spot Instances.
Read More
Finally
I am a big fan of our Spot Instances and I am really looking forward to hearing about new and interesting ways that our customers put them to use. You now have the opportunity to fine-tune your business processes to reduce your costs, and you can now make some very explicit tradeoffs between cost, time to completion, and what happens if the market price rises above your bid. If you are an IT professional, you have some shiny new tools that will allow you to reduce costs while getting work done more quickly.
And what do you think?
— Jeff;