AWS Big Data Blog
Category: Amazon Redshift

Proactive monitoring for Amazon Redshift Serverless using AWS Lambda and Slack alerts
In this post, we show you how to build a serverless, low-cost monitoring solution for Amazon Redshift Serverless that proactively detects performance anomalies and sends actionable alerts directly to your selected Slack channels.

Modernize business intelligence workloads using Amazon Quick
In this post, we provide implementation guidance for building integrated analytics solutions that combine the generative BI features of Amazon Quick with Amazon Redshift and Amazon Athena SQL analytics capabilities.
Secure multi-warehouse Amazon Redshift access behind a Network Load Balancer using Microsoft Entra ID
In this post, we show you how to configure a native identity provider (IdP) federation for Amazon Redshift Serverless using Network Load Balancer. You will learn how to enable secure connections from tools like DBeaver and Power BI while maintaining your enterprise security standards.
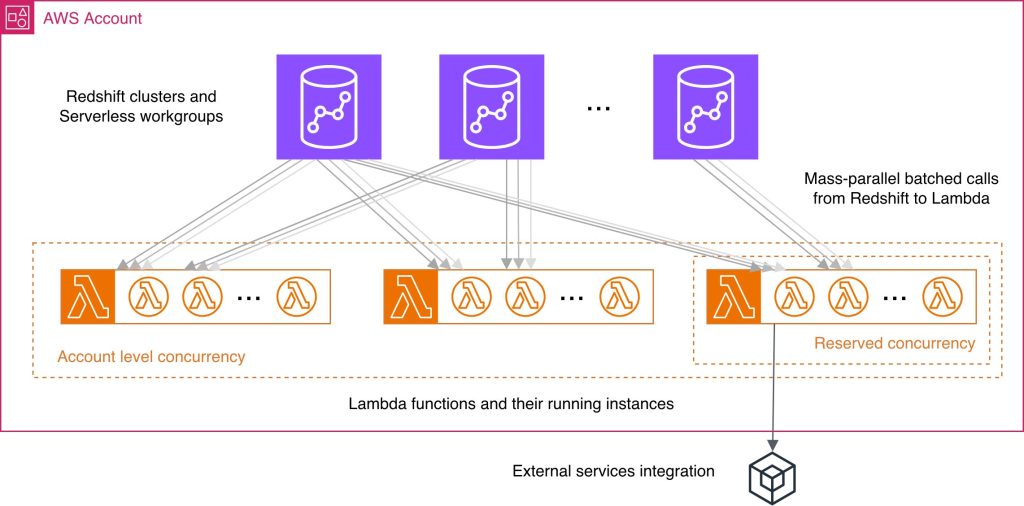
Best practices for Amazon Redshift Lambda User-Defined Functions
While working with Lambda User-Defined Functions (UDFs) in Amazon Redshift, knowing best practices may help you streamline the respective feature development and reduce common performance bottlenecks and unnecessary costs. You wonder what programming language could improve your UDF performance, how else can you use batch processing benefits, what concurrency management considerations might be applicable in your case? In this post, we answer these and other questions by providing a consolidated view of practices to improve your Lambda UDF efficiency. We explain how to choose a programming language, use existing libraries effectively, minimize payload sizes, manage return data, and batch processing. We discuss scalability and concurrency considerations at both the account and per-function levels. Finally, we examine the benefits and nuances of using external services with your Lambda UDFs.
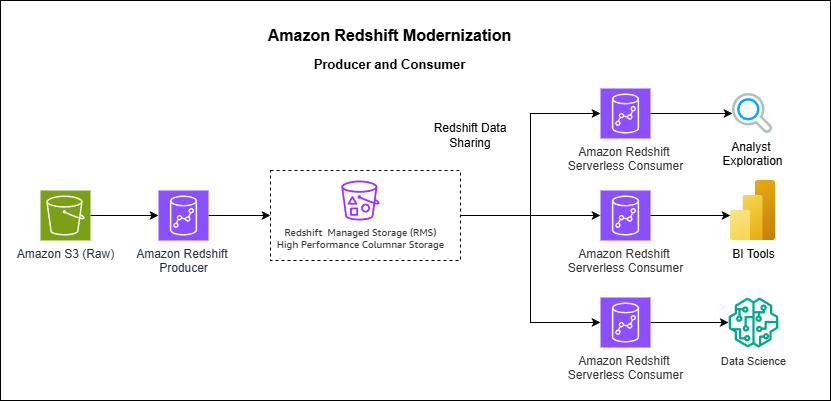
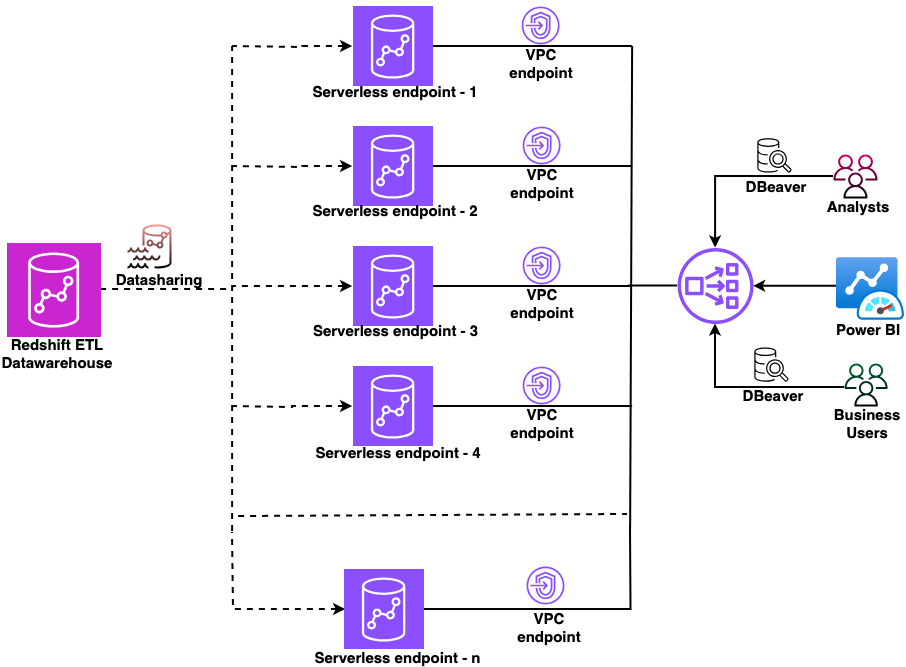
How Vanguard transformed analytics with Amazon Redshift multi-warehouse architecture
In this post, Vanguard’s Financial Advisor Services division describes how they evolved from a single Amazon Redshift cluster to a multi-warehouse architecture using data sharing and serverless endpoints to eliminate performance bottlenecks caused by exponential growth in ETL jobs, dashboards, and user queries.

Scale fine-grained permissions across warehouses with Amazon Redshift and AWS IAM Identity Center
This post provides a comprehensive technical walkthrough for implementing Amazon Redshift federated permissions with AWS IAM Identity Center to help achieve scalable data governance across multiple data warehouses. It demonstrates a practical architecture where an Enterprise Data Warehouse (EDW) serves as the producer data warehouse with centralized policy definitions, helping automatically enforce security policies to consuming Sales and Marketing data warehouses without manual reconfiguration.

Amazon Redshift DC2 migration approach with a customer case study
In this post, we share insights from one of our customers’ migration from DC2 to RA3 instances. The customer, a large enterprise in the retail industry, operated a 16-node dc2.8xlarge cluster for business intelligence (BI) and ETL workloads. Facing growing data volumes and disk capacity limitations, they successfully migrated to RA3 instances using a Blue-Green deployment approach, achieving improved ETL query performance and expanded storage capacity while maintaining cost efficiency.

Standardize Amazon Redshift operations using Templates
In this post, we introduce Redshift Templates and show examples of how they can standardize and simplify your data loading operations across different scenarios. By encapsulating common COPY command parameters into reusable database objects, templates help remove repetitive parameter specifications, facilitate consistency across teams, and centralize maintenance.

Build a data pipeline from Google Search Console to Amazon Redshift using AWS Glue
In this post, we explore how AWS Glue extract, transform, and load (ETL) capabilities connect Google applications and Amazon Redshift, helping you unlock deeper insights and drive data-informed decisions through automated data pipeline management. We walk you through the process of using AWS Glue to integrate data from Google Search Console and write it to Amazon Redshift.

Verisk cuts processing time and storage costs with Amazon Redshift and lakehouse
Verisk, a catastrophe modeling SaaS provider serving insurance and reinsurance companies worldwide, cut processing time from hours to minutes-level aggregations while reducing storage costs by implementing a lakehouse architecture with Amazon Redshift and Apache Iceberg. If you’re managing billions of catastrophe modeling records across hurricanes, earthquakes, and wildfires, this approach eliminates the traditional compute-versus-cost trade-off by separating storage from processing power. In this post, we examine Verisk’s lakehouse implementation, focusing on four architectural decisions that delivered measurable improvements.